<!--more--> ## 零、前言 作为本书的最后一个章节,作者介绍了如何通过微调一个follow instruction的llm。 本章代码:[ch07](https://github.com/Equinox-2003/LLMs-from-scratch-Practice/tree/main/ch07) ## 一、Fine Tuning to Follow Instructions ### 1.1 Introduction to instruction fine-tuning **流程一览:** …
<!--more--> ## 零、写在前面 这一章主要讲了下如何对llm进行微调。 本章代码:[ch06](https://github.com/Equinox-2003/LLMs-from-scratch-Practice/tree/main/ch06) ## 一、Fine-tuning for classification ### 1.1 Different categories of fine-tuning 对语言模型最常用的微调方式有 **instruction fine-tuning** 以及 **classification fine-tuning**。 …
<!--more--> ## 零、前言 本章主要讲了下如何评价llm生成文本的质量,如何进行预训练。 本章代码:[ch05](https://github.com/Equinox-2003/LLMs-from-scratch-Practice/tree/main/ch05) ## 一、Pretraining on unlabeled data ### 1.1 Evaluating generative text models 首先回顾下 GPT 生成文本的过程: **创建GPT模型:** ```python import torch from …
<!--more--> ## 零、前言 这一章作者带着手搓了一下GPT 2的architecture,架构还是比价清晰易懂的。 本章代码:[ch04](https://github.com/Equinox-2003/LLMs-from-scratch-Practice/tree/main/ch04) ## 一、Implementing a GPT model ### 1.1 Coding a LLM architecture 像**GPT(generative pretrained transformer)**这样的LLM,都是大而深的神经网络架构,使得生成文本时一次生成 …
<!--more--> ## 零、前言 原书这章主要就是搓了下注意力模块,总体还是非常easy的 本章代码:[ch03](https://github.com/Equinox-2003/LLMs-from-scratch-Practice/tree/main/ch03) ## 一、Self Attention Mechanism ### 1.1 Simple Attention Mechanism 作者没有一上来就手撕多头注意力机制或者说子注意力机制,而是用了一个思想相同,但是实现上简化的一个简单版本的注意力机制。 作者之间用输入向量之间两两做点积来进行注意力分数的计 …
<!--more--> ## 一、SVD ### 1.1 什么是SVD **SVD(奇异值分解)** 线性代数中最重要的矩阵分解之一。 它的核心结论是:**任意一个矩阵(不要求是方阵、不要求满秩),都可以分解为“旋转—缩放—旋转”三个因子的乘积。** 具体地说,对于 **任意** 复矩阵$A_{mn} \in \mathbb{C}^{m\times n} $,存在分解: $$ A_{mn} = U_{mm} \Sigma_{mn} V^T_{nn} $$ 其中: - $UU^T = I$,$U$ 的列是$AA^T$的单位正交特征向量 - $VV^T = I$,$V$ …
<!--more--> ## 一、Transformer ### 1.1 Seq2Seq **Seq2Seq(序列到序列)**模型输入和输出都是一个序列,输入与输出序列长度之间的关系有两种情况。 1. 输入跟输出的长度一样 2. 机器决定输出的长度。 序列到序列模型的常见应用: 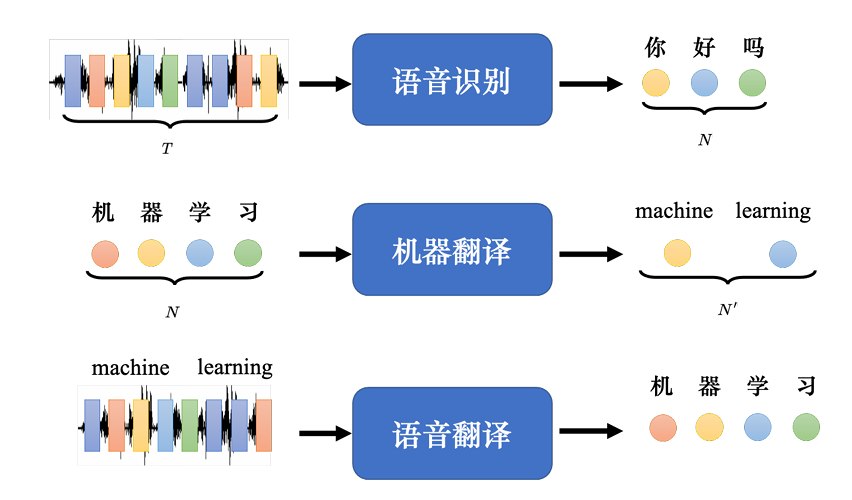 > Q:既然把语音识别系统跟机器翻译系统接起来就能达到语音翻译的效果,那么为什么 要做语音翻译? > > …
<!--more--> ## 一、word-Embedding ### 1.1 为什么 one-hot vector 是一个糟糕的选择 之前在学习逻辑回归的时候,采用 one-hot vector 来进行建模,分类。 独热编码非常易于构建,但它却很难去精准表达不同词之间的相似度。 比如我们如果用向量来表示 "queen" 和 "king",那么我们很可能希望得到 `"queen" - "king" = "woman"` ### 1.2 自监督的word2vec word2vec 有两个模型:**跳元模型(skip-gram)**和**连续词袋(CBOW)**。 对 …
<!--more--> ## 一、自注意力机制 ### 1.1 为什么需要注意力机制 假如输入一句话: > 我昨天买了一本关于深度学习的书,它非常有意思。 > 如果模型现在要理解“它”指代什么,它其实应该**重点**看前面的“书”,而不是**平均**看整句话。 传统的 RNN/LSTM 虽然能处理序列,但有两个问题: 1. **长距离依赖难学** - 前面的信息传到后面会逐渐衰减 2. **所有信息被压缩到一个固定长度表示中** - 容易丢失细节 注意力机制解决的核心思路是:**在生成当前表示时,直接去“检索”输入序列中最相关的位置。** …









