
零、写在前面
无端联想:【硬核科普】从零开始认识显卡
lecture05 主要就是讲了讲GPU的架构,以及一些性能敏感的计算技巧。
一、GPUs、TPUs
1.1 为什么 LLM 时代必须理解 GPU?
语言模型性能提升很大程度上来自 compute scaling,而 compute scaling 离不开 GPU scaling。
过去几十年,深度学习模型之所以能变大,主要依赖:
- 更强的硬件;
- 更好的并行化;
- 更高的 GPU 利用率;
- 更好的训练算法;
- 更大的数据。
在大语言模型中,很多 scaling law 结果都表明:
- 更多计算量 + 更多数据 + 更大模型
- 通常带来更低 loss 和更强能力。
所以如果我们想理解 LLM 为什么能变强,就必须理解:
- GPU 如何提供计算能力?
- 为什么有些操作很快,有些操作很慢?
- 为什么同样 FLOPs 的算法,实际速度可能差很多?
1.2 Dennard Scaling 结束后,为什么 GPU 变重要?
Dennard scaling 是早期芯片发展的一个经验规律:
晶体管变小后,电压和电流也能相应下降,因此单位面积可以放更多晶体管,同时功耗密度不变,频率可以继续提升。
粗略来说,1980–2000 年代 CPU 性能持续提升,很大程度上依赖:制程缩小 → 频率提升 → 单核更快
但后来 Dennard scaling 基本失效:
- 晶体管继续变小,但电压不能无限下降;
- 功耗和散热成为瓶颈;
- CPU 单核频率增长放缓;
- 单线程性能提升不再像以前那么快。
于是计算性能提升的主要路线变成:并行化。
GPU 正是为大规模并行计算而生。
1.3 CPU 和 GPU 的根本区别
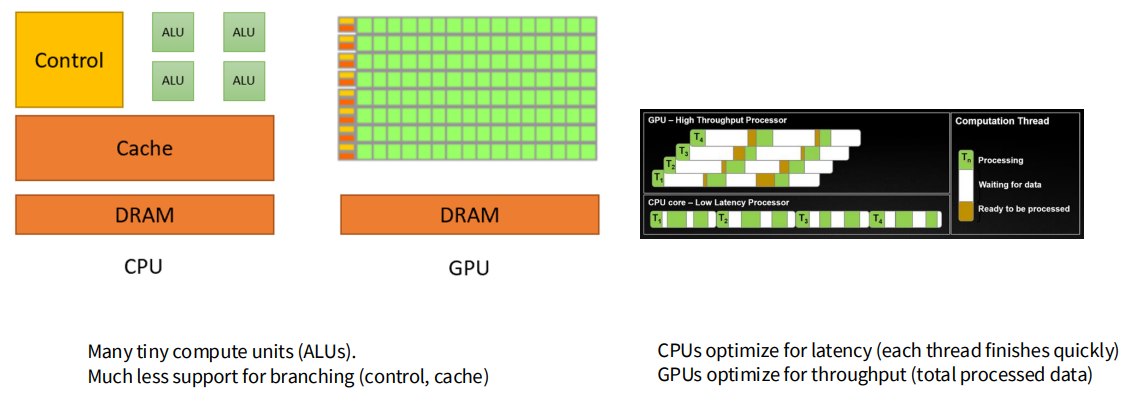
CPU 优化少量快速线程的低延迟;GPU 优化海量线程的总吞吐量。
CPU:少量复杂核心,追求低延迟
CPU 的特点:
- 核心数量相对少;
- 每个核心很强;
- 有复杂控制逻辑;
- 分支预测强;
- cache 层级复杂;
- 适合复杂控制流;
- 适合低延迟任务。
比如:
- 操作系统调度
- 浏览器
- 数据库
- 复杂逻辑判断
- 串行程序
CPU 关注的是:一个线程尽快完成。
GPU:大量简单核心,追求高吞吐
GPU 的特点:
- 有大量计算单元;
- 每个计算单元比较简单;
- 控制逻辑较弱;
- 分支能力较弱;
- 适合相同操作作用在大量数据上;
- 适合矩阵乘法、卷积、向量运算。
GPU 关注的是:单位时间处理尽可能多的数据。
深度学习正好非常适合 GPU,因为大量计算都是:
- 矩阵乘法
- 批量向量运算
- 卷积
- attention
- elementwise 操作
这些操作高度并行。
1.4 GPU 的执行结构:SM、SP、Thread、Block、Warp
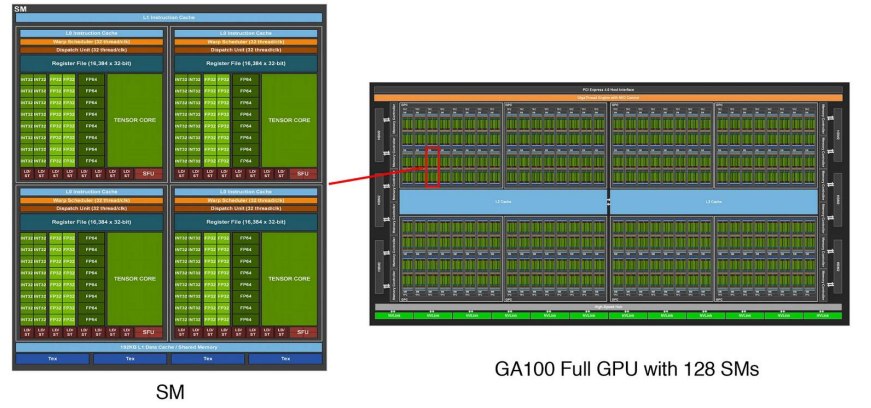
1.4.1 SM:Streaming Multiprocessor
GPU 由很多个 SM,Streaming Multiprocessor 组成。
可以把 SM 理解为 GPU 中的一个“计算小工厂”。
例如一张 NVIDIA A100 有很多 SM,每个 SM 可以独立执行一部分任务。
每个 SM 内部有:
- CUDA cores / SPs;
- Tensor Cores;
- register file;
- shared memory;
- L1 cache;
- warp scheduler。
1.4.2 SP:Streaming Processor
讲义里提到每个 SM 里有很多 SP,Streaming Processor。
SP 可以理解为执行普通浮点/整数指令的小计算单元。
不过现代 NVIDIA 架构中更常见说法是 CUDA cores。
1.4.3 Thread:线程
GPU 程序由大量 threads 执行。
每个 thread 通常处理一小部分数据。
例如做向量加法:
C[i] = A[i] + B[i]
可以让每个 thread 负责一个 i。
GPU 强的地方不是单个 thread 快,而是可以同时跑海量 threads。
1.4.4 Block:线程块
Threads 被组织成 blocks。
一个 block 会被分配到一个 SM 上运行。
block 内的 threads 可以:
- 共享 shared memory;
- 进行同步;
- 协作完成一个 tile 的计算。
不同 blocks 之间通常不能直接同步,也不能直接访问彼此的 shared memory。
如果不同 block 需要交换信息,一般必须通过:global memory。这很慢。
1.4.5 Warp:线程束
NVIDIA GPU 中,threads 实际以 warp 为单位执行。
一个 warp 通常包含:32 个连续编号的 threads
这些 threads 使用 SIMT 模型执行。
1.5 SIMT 执行模型
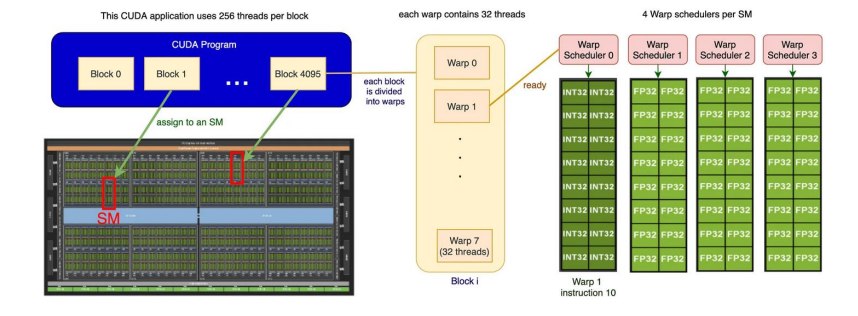
SIMT 是:Single Instruction, Multiple Threads
一个 warp 中的 32 个 threads 同时执行同一条指令,但处理不同数据。
比如:
C[i] = A[i] + B[i]
32 个 threads 同时执行加法,只是每个 thread 的 i 不同。
1.5.1 为什么分支会变慢?
如果 warp 中不同 threads 走不同分支:
if x[i] > 0:
y[i] = x[i]
else:
y[i] = 0
假设 16 个 threads 走 if,16 个走 else。
GPU 不能让同一个 warp 同时执行两条不同指令。
所以它通常会:
- 先执行 if 分支,让 else 分支线程 inactive;
- 再执行 else 分支,让 if 分支线程 inactive。
这叫:branch divergence / control divergence。结果是并行效率下降。
所以 GPU 喜欢:所有线程执行相同流程。不喜欢复杂分支。
1.6 GPU 的内存层级
越靠近 SM 的 memory 越快,但容量越小、越贵。
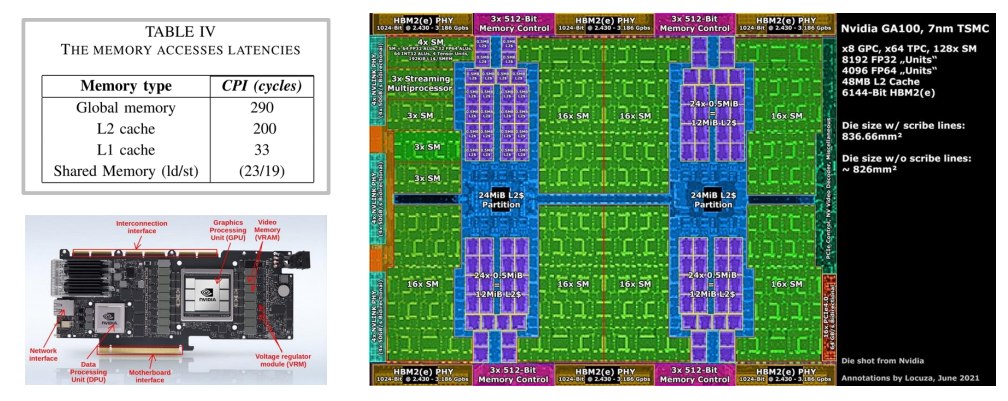
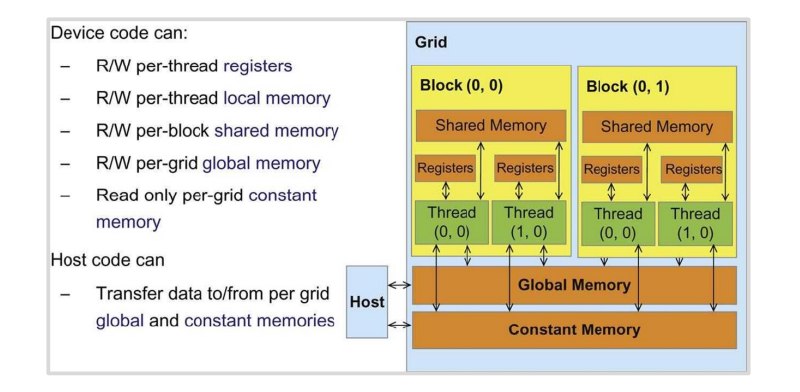
GPU 常见内存层级包括:
Registers
Shared Memory / L1 Cache
L2 Cache
Global Memory / HBM
1.6.1 Registers
每个 thread 私有。
特点:
- 最快;
- 容量很小;
- 只能本 thread 使用。
1.6.2 Shared Memory
shared memory 位于 SM 内部。
特点:
- 一个 block 内 threads 共享;
- 比 global memory 快很多;
- 容量有限;
- 程序员可以显式管理。
这是高性能 CUDA kernel 的核心工具之一。
1.6.3 L1 / L2 Cache
L1 通常靠近 SM,L2 是芯片级共享 cache。
它们用于缓存 global memory 数据。
1.6.4 Global Memory / HBM
Global memory 是 GPU 外部显存,例如 HBM。
特点:
- 容量大;
- 带宽高但延迟大;
- 比 shared memory 慢很多;
- 跨 block 通信通常必须通过 global memory。
在大模型训练中,很多性能瓶颈来自:HBM ↔ SM 的数据搬运。
1.7 SRAM vs DRAM
SRAM,比如 shared/cache memory,更贵但更快;DRAM,比如 global memory,更便宜但更慢。
| 类型 | 位置 | 速度 | 容量 | 成本 |
|---|---|---|---|---|
| SRAM | 芯片内 | 快 | 小 | 贵 |
| DRAM/HBM | 芯片外/旁边 | 慢 | 大 | 便宜 |
深度学习 kernel 优化的一个核心思想就是:
尽量把常用数据搬到 shared memory / SRAM 中复用,减少访问 global memory。
这就是 tiling 的核心。
1.8 TPU vs GPU
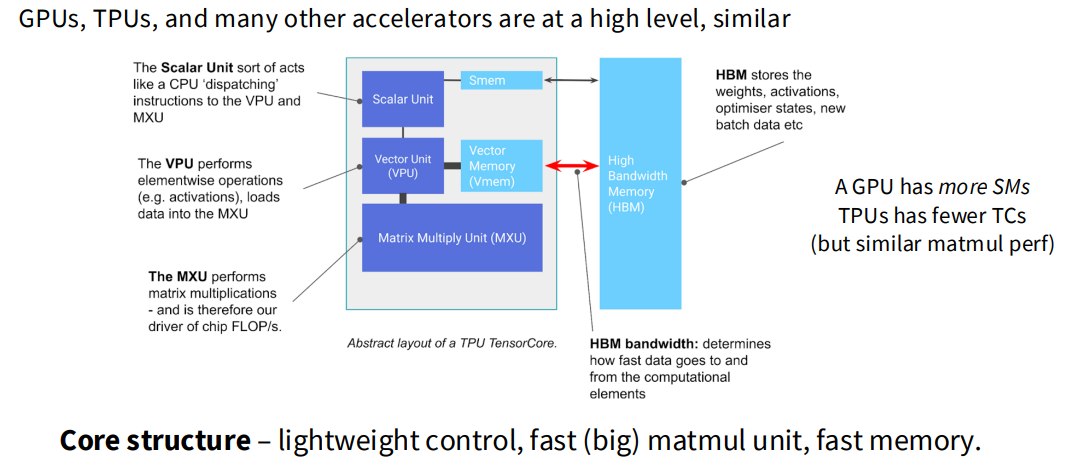
讲义简单提到 TPU。
高层看,GPU、TPU 等 AI accelerator 都类似:
- 轻量控制逻辑
- 大矩阵乘法单元
- 高速片上内存
- 高带宽互连
区别在于:
- GPU 有更多 SM;
- TPU 有更专门化的大矩阵乘法单元;
- TPU 没有 NVIDIA warp 这种模型;
- TPU 更适合大规模矩阵计算;
- GPU 更通用,生态更成熟。
可以简单理解:
- GPU 更通用;
- TPU 更像专门为深度学习矩阵计算设计的加速器。
1.9 Compute scaling 比 memory scaling 更快
FLOPs scale faster than memory.
GPU 每秒能做的计算量增长很快,但显存带宽和内存访问速度增长没那么快。
于是出现一个问题:计算单元很强,但数据送不过来。即,memory wall
现代 GPU 常常不是算不过来,而是:等数据。
所以高性能算法不仅要减少 FLOPs,更要减少:
- global memory access
- data movement
- intermediate tensor materialization
这就是 FlashAttention、operator fusion、tiling 等技术的核心。
二、如何让 ML workload 在 GPU 上跑得快?
如何避免 memory bound?
这需要理解 Roofline Model。
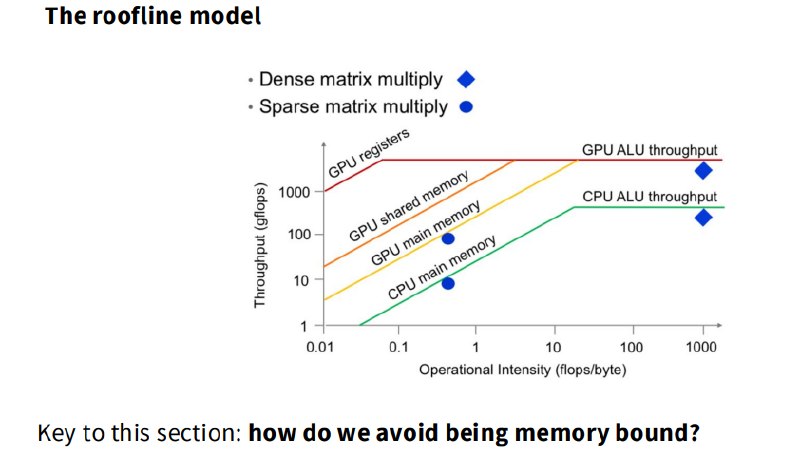
2.1 Roofline Model
Roofline model 用来判断一个算子是:compute-bound,还是 memory-bound
它关注一个指标:Arithmetic Intensity = FLOPs / Bytes moved
每搬 1 byte 数据,可以做多少计算。
2.1.1 Compute-bound
如果 arithmetic intensity 很高,说明每搬一点数据可以做很多计算。
这种操作受限于 GPU 算力。
典型例子:大矩阵乘法。尤其是形状良好的 GEMM。
2.1.2 Memory-bound
如果 arithmetic intensity 很低,说明搬很多数据只做一点计算。
这种操作受限于内存带宽。
典型例子:
- ReLU;
- LayerNorm / RMSNorm;
- dropout;
- elementwise add;
- softmax 的某些实现;
- tensor copy;
- reshape/transpose 的实际数据搬运。
如果一个操作是 memory-bound,那么减少 FLOPs 可能没用。
真正需要优化的是:
- 减少读写
- 融合操作
- 提高数据复用
- 使用 shared memory
- 低精度
- 重计算代替存储
2.2 GPU 加速技巧
讲义列了几类技巧:
- Control divergence;
- Low precision computation;
- Operator fusion;
- Recomputation;
- Coalescing memory;
- Tiling。
2.2.1 Control Divergence
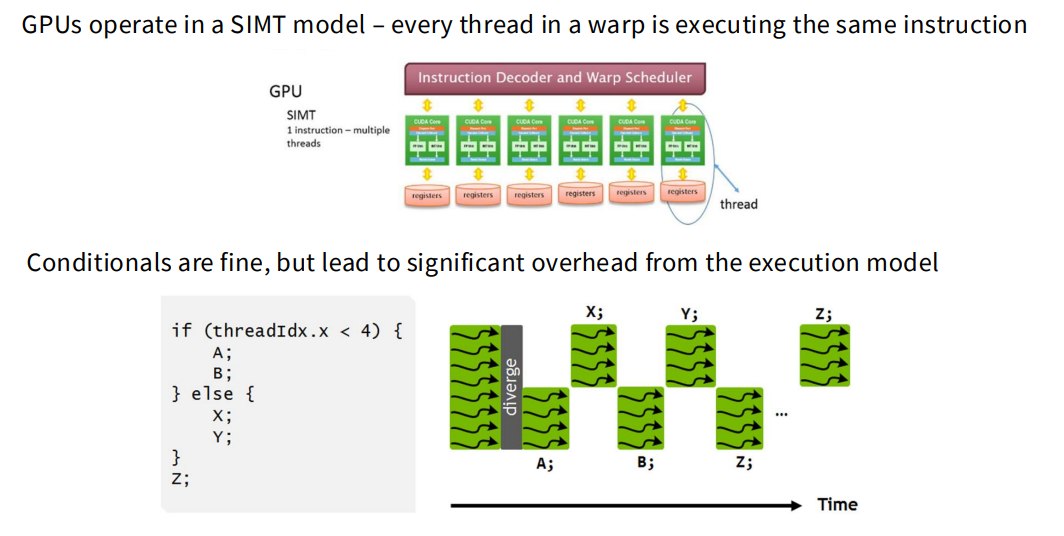
如前所述,GPU warp 内 threads 执行同一指令。
如果出现分支:
if condition:
...
else:
...
而不同 threads 走不同路径,就会产生 divergence。
这不是内存瓶颈,而是执行模型瓶颈。
优化方式:
- 避免复杂分支;
- 尽量让一个 warp 内线程走相同路径;
- 用 mask / predication 替代分支;
- 重排数据让相似条件的数据在一起。
在深度学习中,常见算子一般分支不复杂,所以这不是最大瓶颈,但写自定义 kernel 时很重要。
2.2.2 Low Precision Computation
低精度有两个好处:
- 少搬数据
- 提高 arithmetic intensity
- Tensor Core 更快
讲义提到一些前沿低精度格式。
2.2.2.1 FP8
FP8 通常有两类格式:
- E4M3:4 exponent bits,3 mantissa bits;
- E5M2:5 exponent bits,2 mantissa bits。
E4M3 精度更高,范围小一些。
E5M2 范围更大,精度低一些。
训练时常常需要 scaling factor 来避免溢出/下溢。
2.2.2.2 MXFP8
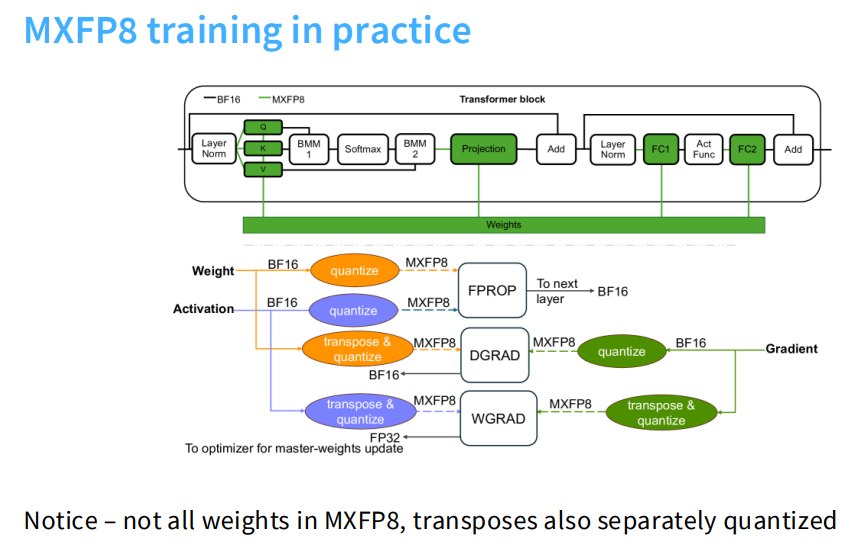
MXFP8 是一种带多个 scaling factors 的低精度方案。
讲义提到:
- 使用 E4M3;
- scale factor 自身可能是 FP8 E8M0;
- 每 32 个元素一个 scale;
- transpose 变得复杂。
为什么 transpose 复杂?
因为如果 scale 是按 block 分组的,转置后元素分组关系变了,scale 也要重新组织或重新量化。
这在低精度训练系统中是实际工程难点。
2.2.2.3 MXFP4
MXFP4 更激进。
FP4 能表示的值非常少,所以必须依赖 scaling factor。
这种格式主要用于进一步降低内存和带宽,但训练稳定性和精度挑战更大。
2.2.3 Operator Fusion
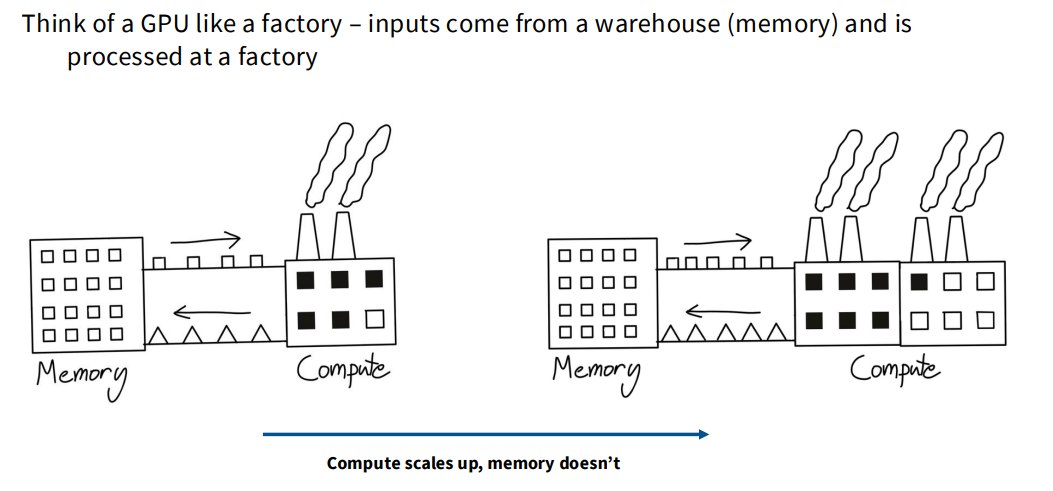
为什么 fusion 有用?
讲义用工厂类比:
- global memory 是仓库;
- SM 是工厂;
- 数据从仓库运到工厂处理;
- 处理完再运回仓库。
如果你有多个连续操作:
a = sin(x)
b = a * a
c = cos(x)
d = c * c
y = b + d
朴素实现可能每一步都:
- 读 global memory 写 global memory 启动一个 CUDA kernel
非常浪费。
非融合 vs 融合:
非融合:
x → kernel1 → intermediate1 写回 HBM
intermediate1 → kernel2 → intermediate2 写回 HBM
...
融合:
x 读入寄存器/缓存
连续做多个操作
最后只写一次 y
融合减少:
- kernel launch overhead;
- global memory 读写;
- 中间 tensor materialization。
讲义提到简单 pointwise fusion 可以由编译器自动完成,比如:
torch.compile
对于 elementwise 操作,编译器可以生成一个 fused kernel。
但对于复杂操作,例如 FlashAttention 这种,需要专门设计 kernel。
2.2.4 Recomputation / Activation Checkpointing
训练神经网络时,反向传播需要前向激活。
标准做法是:
forward 时保存 activations
backward 时读取 activations 计算梯度
但保存和读取 activations 很耗显存和带宽。
假设有三个 sigmoid 连起来:
x → sigmoid → sigmoid → sigmoid
如果保存每层激活:
forward 写中间结果
backward 读中间结果
读写很多。
如果不保存中间激活,backward 时重新算一遍:recompute activations
一个方式就是把一个前向过程划分成若干段,每段保存入口的checkpoint,反向传播计算每段梯度的时候从该段checkpoint跑一下前向过程。
虽然多做了一些计算,但减少了内存读写。如果操作是 memory-bound,那么:多算一点,少搬很多。可能更快。
这就是 activation checkpointing 的思想。
大模型训练常用 activation checkpointing。
因为 Transformer 中 activations 占显存很大,尤其长序列时。
常见策略:
- 每几层保存一次;
- attention 内部重计算;
- FlashAttention backward 中重计算 softmax tile;
- selective checkpointing。
核心 tradeoff:用更多计算换更少内存。
2.2.5 Memory Coalescing
Memory coalescing 是 CUDA 性能基础。
2.2.5.1 DRAM burst mode
Global memory 通常不是一个 byte 一个 byte 读取,而是以较大连续块读取。这叫 burst mode(计组里面的突发传输)。
如果一个 warp 中 32 个 threads 访问连续地址,GPU 可以合并成少量内存事务。
这就是:coalesced memory access
2.2.5.2 矩阵存储布局的影响
大多数矩阵是 row-major:连续内存对应同一行的连续元素。
如果 threads 沿行方向访问:A[row, col + thread_id]
通常 coalesced。
如果 threads 沿列方向访问:A[row + thread_id, col]
在 row-major 中地址相隔一个 row stride,可能不 coalesced。
这就是矩阵乘法 kernel 设计需要考虑数据布局的原因。
2.2.6 Tiling
Tiling 是大招。
这是高性能矩阵乘法和 FlashAttention 的核心。
2.2.6.1 非 tiled matmul 的问题
矩阵乘法:
P = M × N
每个输出元素:
P[i, j] = Σ_k M[i, k] N[k, j]
朴素做法会反复从 global memory 读取同一批 M 和 N 元素。
例如 M[i, k] 会被用于多个不同 j。
如果每次都从 global memory 读,就浪费。
2.2.6.2 Tiling 的核心思想
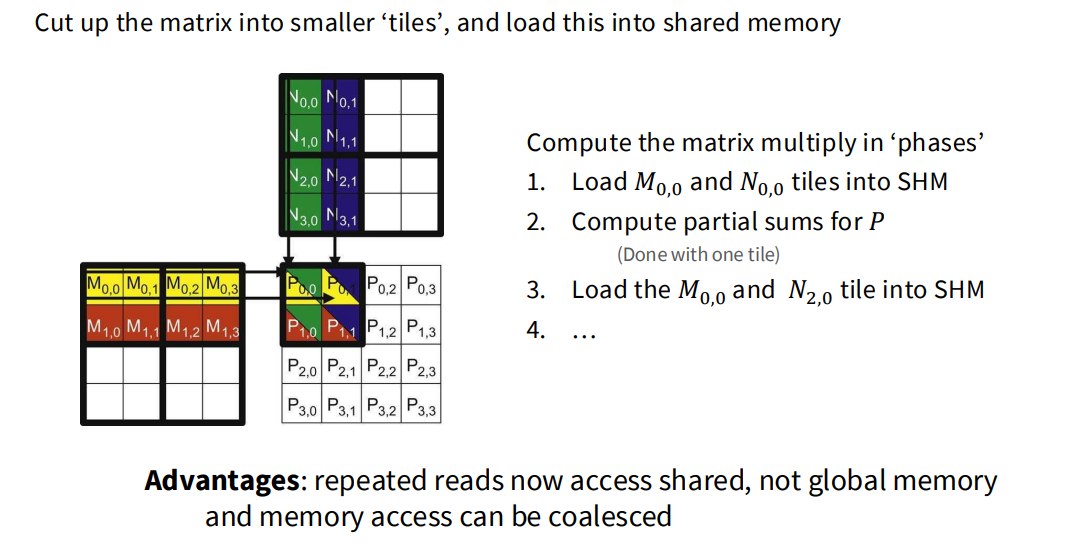
把矩阵切成小块:tile
每个 block 负责计算输出矩阵的一小块。
流程:
- 从 global memory 读取 M 的一个 tile;
- 从 global memory 读取 N 的一个 tile;
- 放进 shared memory;
- block 内 threads 多次复用 shared memory 中的数据;
- 计算 partial sums;
- 继续加载下一个 tile;
- 最后写回输出。
2.2.6.3 Tiling 为什么快?
因为:
- global memory 访问减少 shared memory 访问增加
shared memory 比 global memory 快很多。
讲义中的数学直觉:
- 非 tiled matmul:每个输入可能从 global memory 读
N次; - tiled matmul:每个输入从 global memory 读
N/T次; - global memory 访问减少约
T倍。
这就是矩阵乘法能高效利用 GPU 的重要原因。
2.2.6.4 Tiling 的复杂性
Tiling 很强,但实现复杂:
- Tile size 不整除矩阵尺寸,就会有边界 tile。
- 即使理论上访问连续,如果矩阵维度和内存对齐不好,也可能导致 memory coalescing 差。
2.2.7 Matrix Mystery:为什么更大的矩阵有时更快?
有些更大的矩阵反而更快,或者性能呈周期性变化。
原因包括:
- tiling 对齐;
- wave quantization;
- SM 数量匹配。
什么是wave quantization?
GPU 有固定数量 SM。
假设一个 kernel 产生若干 tiles,每个 tile 分配给一个 block,block 在 SM 上执行。
如果 tile 数量刚好是 SM 数量的整数倍,利用率较高。
如果 tile 数量略多一点,会多出一波执行,但最后一波 SM 没有填满,效率下降。
例子:
-
tile size:256 × 128
-
矩阵大小 1792 时:
1792 / 256 = 7 1792 / 128 = 14 tiles = 7 × 14 = 98 -
A100 有 108 SM,98 tiles 一波可以跑完,虽然还有一些 SM 闲置。
-
但如果矩阵大小变成 1793:
ceil(1793/256) = 8 ceil(1793/128) = 15 tiles = 8 × 15 = 120 -
120 tiles 超过 108 SM,需要第二波。第二波只有 12 个 tiles,很多 SM 闲置。所以性能可能突然变差。
这就是 wave quantization。
三、FlashAttention
3.1 核心思想
FlashAttention 是 IO-aware attention。
也就是说,它关注的不只是 FLOPs,还有HBM 读写次数。
核心思想:
- 把 Q/K/V 切成 tiles;
- 每次把一小块 Q/K/V 载入 shared memory;
- 在 SRAM/shared memory 中计算局部 attention;
- 用 online softmax 逐 tile 更新结果;
- 不显式存储完整
n × nattention matrix。
第一步:Tiling Q/K/V
类似矩阵乘法 tiling。
把 Q 分成 query blocks:$Q_i$
把 K/V 分成 key-value blocks:$K_j, V_j$
对于每个 $Q_i$,遍历所有 $K_j, V_j$ blocks。
计算局部 score:$S_ij = Q_i K_j^T$
这个 S_ij 是一个小 tile,放在 shared memory/register 中处理。
关键是:不把完整 S 写到 HBM。
比较麻烦的是 softmax 需要全行归一化,而且为了数值稳定,往往要对所有值先减去最大值在做幂运算
3.2 Online Softmax
这是 FlashAttention 的关键数学技巧。
Tile-by-tile 的问题:
如果 logits 分成多个 block:
block 1
block 2
block 3
...
每次只看到一个 block。
我们需要维护:
- 当前看到的最大值 m
- 当前归一化分母 l
- 当前输出累积 o
当新 block 到来时,更新最大值:
$$ m_{new} = max(m_{old}, max(block)) $$由于 max 变了,旧的 exp 累积需要重新缩放。
假设旧分母是:
$$ l_{old} = Σ_{old} exp(x_j - m_{old}) $$
新 block 的局部最大是 m_block,新全局最大:
旧分母要转换到以 m_new 为基准:
新 block 分母:
$$ l_{block} = Σ_{block} exp(x_j - m_{new}) $$更新:
$$ l_{new} = l_{old_{rescaled}} + l_{block} $$输出累积也类似重缩放。这样就能 tile-by-tile 精确计算 softmax。
3.3 前向过程
对每个 Q block:
-
加载 $Q_i$ 到 SRAM;
-
初始化:
$$ m_i = -\infty \\ l_i = 0\\ O_i = 0 $$ -
遍历 K/V blocks:
-
加载 $K_j, V_j$ 到 SRAM;
-
计算局部分数:
$$ S_{ij} = Q_i K_j^T $$ -
更新 online softmax 的 max:$m_{new}$
-
计算局部概率;
-
更新分母 $l_i$;
-
更新输出 $O_i$;
-
-
最后把 $O_i$ 写回 HBM。
整个过程避免存储:
- 完整 S = QK^T
- 完整 P = softmax(S)
3.4 FlashAttention 为什么快?
- 减少 HBM 读写
- 使用 tiling 提高数据复用
- 融合多个操作
3.5 反向传播重计算
讲义说不讲 backward,但提到:
they recompute tile-by-tile.
反向传播需要 softmax probabilities 等中间量。
FlashAttention 选择:
不保存完整 P
backward 时重新计算需要的 tile
它用额外计算换更少内存。
由于 attention 是 memory-bound,减少 HBM 访问常常比多算一点更划算。

说些什么吧!