<!--more--> ## 零、写在前面 ## 一、摘要 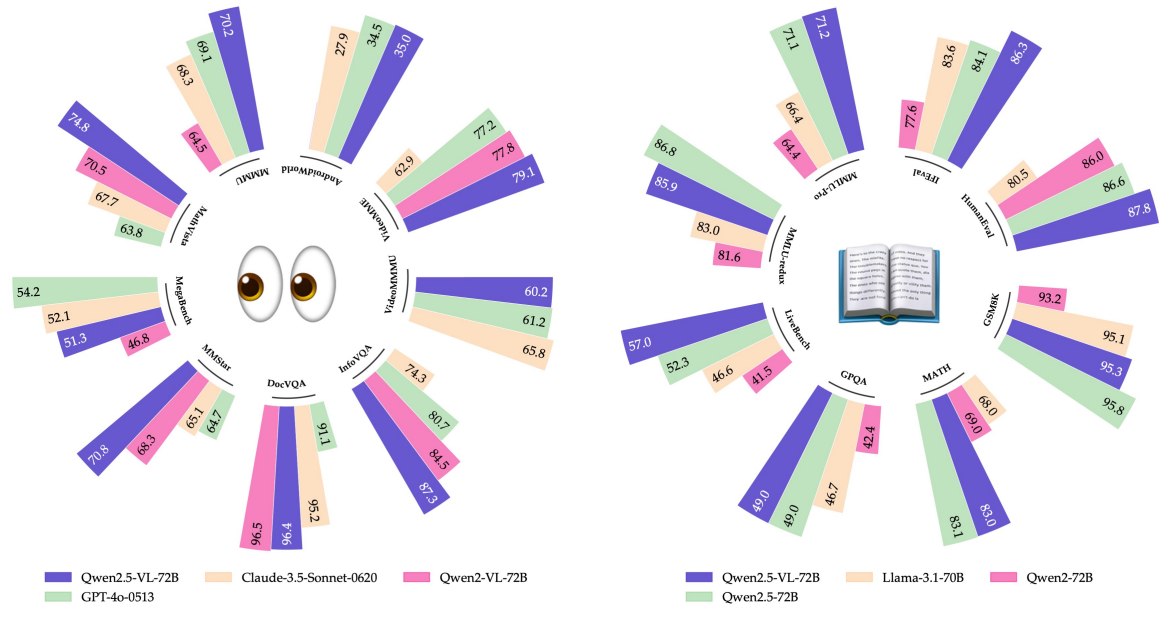 摘要把 Qwen2.5-VL 定位为 Qwen vision-language 系列的最新旗舰模型,强调它在基础能力和新功能上都有提升。核心能力包括: - 更强的视觉识别与细粒度感知; - 使用 bounding boxes 或 points 进行精确 object localization; - …
<!--more--> ## 零、写在前面 Qwen2-VL做了以下升级:动态分辨率、跨模态位置编码、视频统一建模和 scaling。 ## 一、摘要 Qwen2-VL 被定义为 Qwen-VL 系列的升级版,**核心目标是突破传统视觉处理中的固定分辨率范式**。摘要中强调了三个主要技术点: 1. **Naive Dynamic Resolution**:模型可以根据图像原始分辨率动态生成不同数量的 visual tokens,而不是把所有图像强制缩放到同一固定尺寸。 2. **Multimodal Rotary Position Embedding, …
<!--more--> ## 零、写在前面 这篇主要就是在 LLaVA 框架下,通过少量但关键的设计改动,可以得到一个更强、更简单、数据效率更高的 Large Multimodal Model baseline,即 **LLaVA-1.5**。 ## 一、摘要 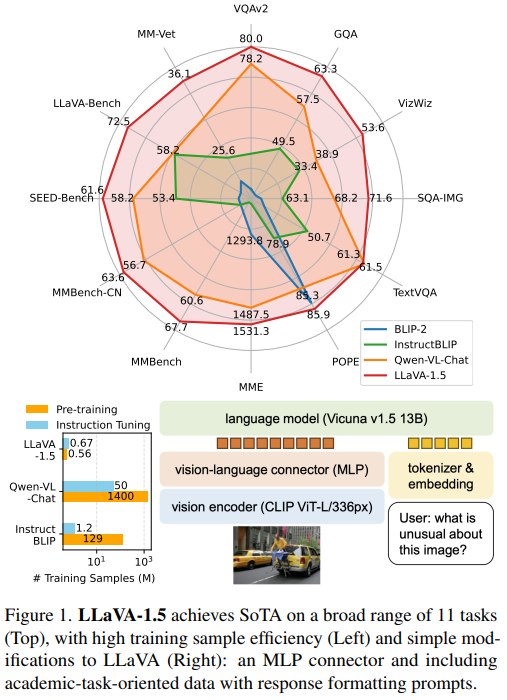 Abstract 针对 LMM 研究中的一个关键问题:现有方法越来越复杂,训练数据和算力规模越来越大,但哪些设计因素真正重要并不清楚。 …
<!--more--> ## 零、写在前面 > 无端联想:[【硬核科普】从零开始认识显卡](https://www.bilibili.com/video/BV1xE421j7Uv/?spm_id_from=333.337.search-card.all.click&vd_source=a7ce6b38365a0cb2ad96f0668de0bc51) lecture05 主要就是讲了讲GPU的架构,以及一些性能敏感的计算技巧。 ## 一、GPUs、TPUs ### 1.1 为什么 LLM 时代必须理解 GPU? > ** …












