
零、写在前面
如何做 Zero-shot 的 CoT?——Let’s think step by step。
一、标题
Large Language Models are Zero-Shot Reasoners
这个标题很有野心,因为它把研究重点从 “LLM 是 few-shot learner” 推到了 “LLM 本身就可能有可被触发的 zero-shot reasoning 能力”。这不是说 few-shot examples 没用了,而是提醒我们:在构造复杂示例、微调数据集之前,应该先认真检查模型的原生 zero-shot 能力。
二、摘要
摘要大概讲了五点。
第一,论文承认已有 CoT prompting 的重要性。Few-shot-CoT 通过给模型 step-by-step answer examples,在 arithmetic 和 symbolic reasoning 等多步任务上取得了很强效果。
第二,作者指出一个容易被忽略的问题:这些成功通常被解释为 LLM 的 few-shot learning 能力,但也许模型本身已经有相当多的 zero-shot reasoning 能力,只是普通 zero-shot prompt 没有触发出来。
第三,论文提出一个极简方法:Let’s think step by step.
把这句话放在答案前,模型会更倾向于先生成中间推理过程,再给出答案。作者称之为 Zero-shot-CoT。
第四,实验覆盖多类推理任务:
- arithmetic reasoning:MultiArith、GSM8K、AQUA-RAT、SVAMP 等。
- symbolic reasoning:Last Letter、Coin Flip。
- logical reasoning:Date Understanding、Tracking Shuffled Objects。
- commonsense reasoning:CommonsenseQA、StrategyQA。
第五,最重要的数字是:在 text-davinci-002 上,Zero-shot-CoT 将 MultiArith 从 17.7% 提升到 78.7%,将 GSM8K 从 10.4% 提升到 40.7%。在 PaLM 540B 上也观察到类似趋势。
Zero-shot-CoT 用一句通用触发语让大模型先生成中间推理步骤,从而在多个多步推理任务上显著超过标准 zero-shot prompting。
到这里基本确定,这篇工作主要就是发现了Zero-shot-CoT,贡献主要来自系统验证。
三、背景和相关工作

3.1 LLM prompting
传统 NLP 常用的是:
pre-train -> fine-tune
GPT-3 之后,LLM 展示了强大的 in-context learning,于是出现:
pre-train -> prompt
prompting 可以粗略分成:
| 类型 | 输入形式 | 是否提供示例 |
|---|---|---|
| Zero-shot | task instruction / template | 否 |
| Few-shot | task instruction + examples | 是 |
| Few-shot-CoT | examples 中包含 step-by-step reasoning | 是 |
| Zero-shot-CoT | 通用 reasoning trigger | 否 |
本论文主要比较的是 Zero-shot 和 Zero-shot-CoT,同时也和 Few-shot、Few-shot-CoT 做对照。
3.2 Chain-of-Thought prompting
Few-shot-CoT 是这篇论文的直接前作。它把 few-shot examples 的答案从:
The answer is 11.
改成:
Roger started with 5 balls...
5 + 6 = 11. The answer is 11.
也就是在输出中加入自然语言中间步骤。它说明多步推理任务中,模型需要的不只是答案格式,还需要“如何展开推理”的示范。
但 Few-shot-CoT 的问题是:它要求人类为每个任务设计示例。这篇 Zero-shot-CoT 论文把这个要求降到最低。
3.3 Reasoning ability of LLMs
论文把相关工作分成几类:
- Fine-tuning with rationale:用带推理过程的数据训练或微调模型,例如数学题 rationale。
- Few-shot CoT:不训练模型,但在 prompt 中给 step-by-step examples。
- Zero-shot reasoning prompts:不用示例,只通过 prompt 模板激发推理。
Zero-shot-CoT 的定位是:
不 fine-tune,不写 few-shot examples,只用一个通用触发语激发 reasoning。
3.4 Zero-shot abilities of LLMs
GPT-2、GPT-3、InstructGPT、PaLM 等工作都展示了 LLM 的 zero-shot 能力。但这些能力主要体现在 system-1 任务,例如摘要、翻译、阅读理解、简单 QA。
这篇论文的不同点在于,它关注的是 system-2 任务。也就是:需要拆解、计算、追踪状态、处理多个中间步骤的任务。
3.5 Narrow prompting 与 broad prompting
作者借用了 narrow / broad 的区分。
Narrow prompting:为某个具体任务设计 prompt,例如某个数据集的专用模板。Broad prompting:一个 prompt 能跨任务激发更通用的能力。
Zero-shot-CoT 属于 broad prompting。它不是告诉模型“这是 MultiArith 任务”或“这是 Coin Flip 任务”,而是告诉模型“按步骤想”。
四、Zero-shot-CoT
4.1 核心思想
最核心的方法是:
在答案前加上:Let’s think step by step.
标准 zero-shot 可能是:
Q: A juggler can juggle 16 balls. Half of the balls are golf balls,
and half of the golf balls are blue. How many blue golf balls are there?
A: The answer is
Zero-shot-CoT 改成:
Q: A juggler can juggle 16 balls. Half of the balls are golf balls,
and half of the golf balls are blue. How many blue golf balls are there?
A: Let's think step by step.
模型更可能输出:
There are 16 balls in total.
Half of the balls are golf balls, so there are 8 golf balls.
Half of the golf balls are blue, so there are 4 blue golf balls.
这个中间过程再帮助模型得到最终答案。
4.2 Two-stage prompting
论文里的完整 Zero-shot-CoT 实际上是 two-stage prompting。也就是说,它不只是让模型生成推理过程,还要再用一次 prompt 抽取最终答案。
原因是:模型第一阶段生成的文本可能很长,可能没有固定答案格式。为了统一评测,需要第二阶段把答案从 reasoning text 中抽出来。
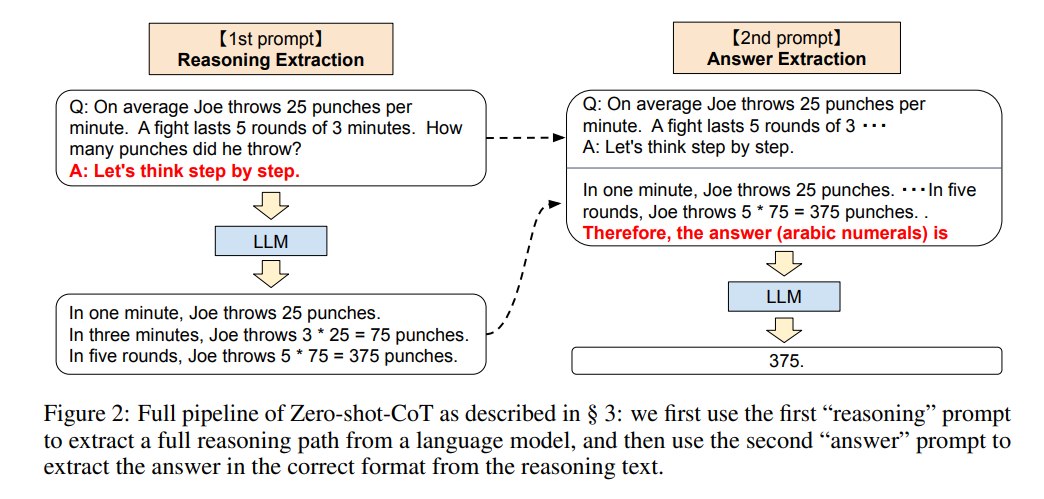
4.2.1 Stage 1:reasoning extraction
第一阶段的模板是:
Q: [X]
A: [T]
其中:
[X]是原始问题。[T]是 reasoning trigger,默认是Let's think step by step.
于是得到:
Q: [question]
A: Let's think step by step.
语言模型根据这个 prompt 生成 reasoning text,论文中记为 z。
4.2.2 Stage 2:answer extraction
第二阶段把问题、第一阶段 prompt、第一阶段生成的 reasoning text 和 answer trigger 拼起来:
[X'] [Z] [A]
其中:
[X']是第一阶段 prompt。[Z]是模型生成的 reasoning text。[A]是答案抽取触发语。
不同任务使用不同 answer trigger:
Therefore, the answer (arabic numerals) is
用于数学题。
Therefore, among A through E, the answer is
用于多选题。
论文还做了 answer cleansing,也就是从模型输出中解析最终答案。
例如数学题中,如果模型输出:
probably 375 and 376
评测脚本会抽取第一个满足格式的数字:
375
多选题则抽取第一个大写选项字母。这个细节很重要,因为不同 answer trigger 会显著影响最终 metric,尤其是 StrategyQA 这类任务。
4.3 对比其他 prompting 方式
| 方法 | 是否给 examples | 是否显式生成 reasoning | 主要成本 |
|---|---|---|---|
| Zero-shot | 否 | 否 | 需要任务说明或答案触发语 |
| Zero-shot-CoT | 否 | 是 | 需要两阶段 prompting 和答案解析 |
| Few-shot | 是 | 否 | 需要输入输出示例 |
| Few-shot-CoT | 是 | 是 | 需要人工构造 step-by-step exemplars |
| Zero-shot-CoT + self-consistency | 否 | 是,多条路径 | 需要多次采样和答案聚合 |
五、实验
5.1 实验设置
论文评估 12 个数据集,分成四类。
| 类别 | 数据集 |
|---|---|
| Arithmetic reasoning | SingleEq、AddSub、MultiArith、AQUA-RAT、GSM8K、SVAMP |
| Commonsense reasoning | CommonsenseQA、StrategyQA |
| Symbolic reasoning | Last Letter、Coin Flip |
| Other logical reasoning | Date Understanding、Tracking Shuffled Objects |
主要模型包括:
- InstructGPT3:
text-ada/babbage/curie/davinci-001和text-davinci-002。 - GPT-3:ada、babbage、curie、davinci。
- PaLM:8B、62B、540B。
- 额外 scaling study:GPT-2、GPT-Neo、GPT-J、T0、OPT。
默认主实验使用 text-davinci-002,并使用 greedy decoding。
5.2 Zero-shot-CoT vs Zero-shot
核心结果如下。
| 任务 | Zero-shot | Zero-shot-CoT | 解读 |
|---|---|---|---|
| MultiArith | 17.7 | 78.7 | 多步数学题,大幅提升 |
| GSM8K | 10.4 | 40.7 | 难数学文字题,明显提升 |
| AQUA-RAT | 22.4 | 33.5 | 多选代数题,有提升 |
| SVAMP | 58.8 | 62.1 | 提升较小但为正 |
| Date Understanding | 49.3 | 67.5 | 日期逻辑推理,明显提升 |
| Tracking Shuffled Objects | 31.3 | 52.4 | 状态追踪,明显提升 |
| Last Letter | 0.2 | 57.6 | 符号操作,巨大提升 |
| Coin Flip | 12.8 | 91.4 | 状态追踪,巨大提升 |
这些结果说明,Zero-shot-CoT 对需要中间步骤的任务非常有效。尤其是 Last Letter 和 Coin Flip,它们不是知识题,而是规则执行题;这说明 prompt 触发的是某种“分步操作模式”。
5.3 简单任务提升小
SingleEq 和 AddSub 是较简单的数学题,不太需要复杂多步推理。论文中它们提升不明显,甚至 AddSub 在默认 answer trigger 下略降:
| 任务 | Zero-shot | Zero-shot-CoT |
|---|---|---|
| SingleEq | 74.6 | 78.0 |
| AddSub | 72.2 | 69.6 |
这和前一篇 CoT 论文的发现一致:CoT 不是所有任务都更好,它最适合多步、困难、标准 prompt scaling curve 较平的任务。
5.4 CommonsenseQA 和 StrategyQA 要谨慎解释
论文明确指出,commonsense reasoning 上 Zero-shot-CoT 并没有稳定带来性能提升。
| 任务 | Zero-shot | Zero-shot-CoT |
|---|---|---|
| CommonsenseQA | 68.8 | 64.6 |
| StrategyQA | 12.7 | 54.8 |
但 StrategyQA 有一个重要细节:Table 1 同时报告了另一种 answer extraction 设置。如果使用标准 answer prompt "The answer is",StrategyQA 的 zero-shot 是 54.3,Zero-shot-CoT 是 52.3。这说明 StrategyQA 的提升高度受 answer extraction 影响,不能简单解读为 CoT 让 StrategyQA 大幅提升。
更稳妥的说法是:
- Zero-shot-CoT 在 CommonsenseQA 上没有提升;
- StrategyQA 的数字依赖答案抽取方式,需要谨慎解释;
- 但模型生成的 reasoning text 有时仍然是合理的,metric 不一定完全反映 reasoning quality。
论文也给了 CommonsenseQA 错误分析:模型可能生成合理推理,但最终选项错;或者它认为多个选项都合理,导致无法只选一个。
5.5 与 Few-shot 和 Few-shot-CoT 对比
在 MultiArith 和 GSM8K 上:
| 方法 | MultiArith | GSM8K |
|---|---|---|
| Zero-shot | 17.7 | 10.4 |
| Few-shot 2 samples | 33.7 | 15.6 |
| Few-shot 8 samples | 33.8 | 15.6 |
| Zero-shot-CoT | 78.7 | 40.7 |
| Few-shot-CoT 2 samples | 84.8 | 41.3 |
| Few-shot-CoT 8 samples | 93.0 | 48.7 |
结论:
- Zero-shot-CoT 明显强于普通 Few-shot。
- Zero-shot-CoT 仍低于精心构造的 Few-shot-CoT。
- 这说明 CoT 的关键不是 examples 本身,而是让模型产生 reasoning path;但高质量 examples 仍然能进一步提升。
5.6 PaLM 540B 结果
论文也在 PaLM 540B 上验证了核心结论:
| 方法 | MultiArith | GSM8K |
|---|---|---|
| PaLM 540B Zero-shot | 25.5 | 12.5 |
| PaLM 540B Zero-shot-CoT | 66.1 | 43.0 |
| PaLM 540B Zero-shot-CoT + self-consistency | 89.0 | 70.1 |
| PaLM 540B Few-shot | - | 17.9 |
| PaLM 540B Few-shot-CoT | - | 56.9 |
| PaLM 540B Few-shot-CoT + self-consistency | - | 74.4 |
这里最值得注意的是 self-consistency。Zero-shot-CoT + self-consistency 在 PaLM 540B 上把 GSM8K 提到 70.1,接近 Few-shot-CoT + self-consistency 的 74.4。
这说明:
Zero-shot-CoT 负责触发推理路径;
self-consistency 负责从多条推理路径中聚合更稳定的最终答案。
5.7 模型规模影响
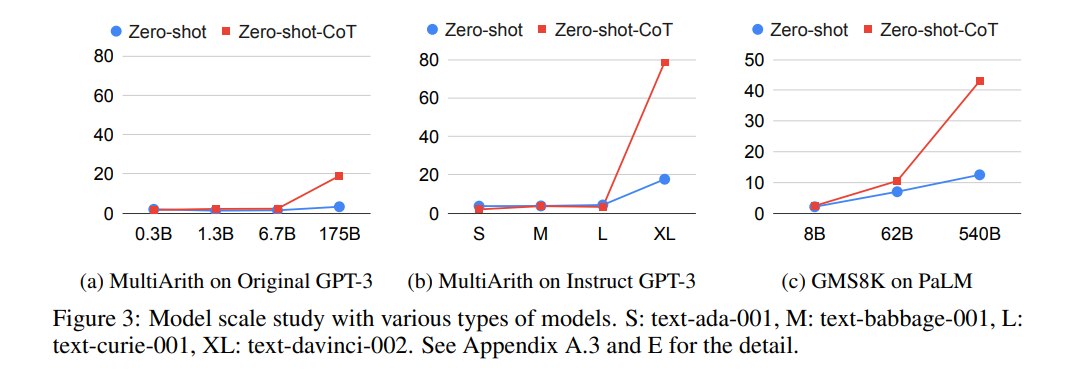
论文 Figure 3 做了 scaling study。核心结论是:
- 标准 Zero-shot 下,随着模型变大,推理任务表现提升很慢,曲线较平。
- 加入 Zero-shot-CoT 后,大模型的性能明显随规模上升。
- 小模型上 CoT 不稳定,甚至可能没有帮助。
这和 Few-shot-CoT 论文的结论一致:CoT-style reasoning 是一种大模型上更明显的 emergent ability。
5.8 Prompt template robustness
论文用 MultiArith 测试了 16 种 trigger,结果显示 prompt wording 很重要。
| Template | 类别 | Accuracy |
|---|---|---|
Let's think step by step. |
instructive | 78.7 |
First, |
instructive | 77.3 |
Let's think about this logically. |
instructive | 74.5 |
Let's solve this problem by splitting it into steps. |
instructive | 72.2 |
Don't think. Just feel. |
misleading | 18.8 |
Let's think step by step but reach an incorrect answer. |
misleading | 18.7 |
By the way, I found a good restaurant nearby. |
irrelevant | 17.5 |
It's a beautiful day. |
irrelevant | 13.1 |
| Zero-shot baseline | - | 17.7 |
结论:
- 鼓励 step-by-step reasoning 的 instructive prompts 有效。
- misleading / irrelevant templates 基本无效,甚至会低于 baseline。
Let's think step by step.在这组实验中最强。
这说明 Zero-shot-CoT 不是魔法咒语,而是一类“推理姿态触发语”。但具体措辞仍然影响很大。
5.9 Few-shot-CoT 对 examples 的敏感性
论文还测试了 Few-shot-CoT 使用不匹配任务示例时的表现。
| 任务 | Zero-shot | 不匹配 Few-shot-CoT | Zero-shot-CoT | 匹配 Few-shot-CoT |
|---|---|---|---|---|
| AQUA-RAT | 22.4 | 31.9 | 33.5 | 39.0 |
| MultiArith | 17.7 | 27.0 | 78.7 | 88.2 |
这里“不匹配 Few-shot-CoT”指用 CommonsenseQA examples 去提示 arithmetic tasks。
结果说明:
- 如果 answer format 相近,例如 CommonsenseQA 和 AQUA-RAT 都是多选题,不匹配 examples 仍有一些帮助。
- 如果 answer format 不同,例如 CommonsenseQA 到 MultiArith,帮助很有限。
- 这支持一个观点:few-shot examples 很大程度也在提供 repeated format / answer format,而不只是“教会任务本身”。
这也是 Zero-shot-CoT 的亮点:它不用任务示例,却在 MultiArith 上远强于不匹配的 Few-shot-CoT。
5.10 错误模式
论文指出 Zero-shot-CoT 有一些典型错误:
- 有时已经得到正确答案,但继续生成不必要推理,最后把答案改错。
- 有时没有真正开始推理,只是复述问题。
- 在 commonsense multiple-choice 任务中,模型可能觉得多个选项都合理,输出多个答案。
- 生成的 reasoning text 可能看起来合理,但最终答案不符合评测格式。
这些错误提醒我们:Zero-shot-CoT 不是可靠推理器,只是一个强 baseline 和能力探针。
六、总结和展望
6.1 论文主要贡献
这篇论文的贡献可以总结为四点。
- 提出
Zero-shot-CoT:只用一句Let's think step by step.触发 LLM 生成中间推理。 - 系统验证它在 arithmetic、symbolic、logical reasoning 上显著超过标准 Zero-shot。
- 提出 two-stage prompting,使 reasoning generation 和 answer extraction 分离。
- 证明 CoT-style reasoning 不一定依赖 few-shot examples,大模型存在可被简单触发的 zero-shot reasoning 能力。
6.2 与前一篇 CoT 论文的关系
前一篇 CoT 论文回答的是:如果给模型 step-by-step examples,模型会不会更会推理?
这篇论文回答的是:如果不给 examples,只给 step-by-step 指令,模型会不会自己推理?
两篇论文合起来构成了 CoT 学习的主线:
| 方法 | 核心输入 | 意义 |
|---|---|---|
| Few-shot-CoT | 人工示例中的 reasoning chains | 证明分步示范能激发推理 |
| Zero-shot-CoT | Let's think step by step. |
证明通用推理触发语也有效 |
| Self-consistency | 多条 sampled reasoning paths | 提升推理输出稳定性 |
6.3 局限
第一,Zero-shot-CoT 对小模型不稳定。它和 Few-shot-CoT 一样,更像大模型涌现能力。
第二,prompt wording 很敏感。同样是鼓励思考,不同模板表现不同;misleading / irrelevant prompt 几乎无效。
第三,answer extraction 会影响指标。尤其是 StrategyQA 这类任务,不同 answer trigger 可能让结论发生变化。
第四,reasoning text 不保证正确。它可能是合理解释,也可能是错误推理,还可能在得到正确答案后继续生成导致答案变错。
第五,训练数据不可完全透明。论文承认,InstructGPT、GPT-3、PaLM 的训练数据细节并不完全公开,所以很难彻底排除数据污染或记忆影响。不过跨模型、跨任务的一致提升说明,它更可能反映一种通用的 prompt-elicited reasoning 能力。
6.4 对后续研究的启发
方向一:Prompt as capability probe
Zero-shot-CoT 提醒我们,prompt 不只是任务接口,也可以是能力探针。一个简单 prompt 可能暴露模型内部尚未被充分研究的能力。
方向二:Self-consistency
Zero-shot-CoT 生成单条推理链,仍然容易出错。Self-consistency 通过采样多条 reasoning paths 并聚合答案,提高稳定性。论文中 PaLM 540B + Zero-shot-CoT + self-consistency 在 GSM8K 达到 70.1,就是很直接的例子。
方向三:ReAct 和 tool use
Zero-shot-CoT 只让模型“想”。ReAct 进一步让模型在 reasoning 和 action 之间交替:
think -> act -> observe -> think -> answer
回顾之前读过的 Qwen3-VL 的 Thinking with Images,可以把它理解为多模态场景里的 ReAct/CoT 延伸:模型不只是写推理,还要看图、定位、调用工具或利用视觉反馈。
方向四:Multimodal CoT
文本 Zero-shot-CoT 的 trigger 是 “按步骤想”。多模态 CoT 还需要解决“看哪里”和“视觉证据如何进入推理链”的问题。对 Qwen3-VL 来说,推理链中可能包含:
- 视觉定位。
- 图表读取。
- OCR。
- spatial relationship reasoning。
- grounding 到 bbox 或 point。
方向五:自动发现更好的 trigger
论文已经发现 prompt template 差异很大。未来可以研究如何自动搜索、优化或学习更稳定的 reasoning triggers。

说些什么吧!