
零、写在前面
翻李沐老师视频翻到的他们的工作,过来读一下hh
一、标题
Automatic Chain of Thought Prompting in Large Language Models
作者都是 d2l 的熟人hh
看到标题就知道本文的工作是去掉了人工设计 CoT demonstrations 的成本。
二、摘要
CoT prompting 在当时主要有两个范式:
Zero-Shot-CoT:不提供示例,只在问题后加一句类似Let's think step by step的 trigger,让模型先推理再回答。Manual-CoT:人工写若干 demonstrations,每个 demonstration 都由 question、rationale、answer 组成。
**论文指出:Manual-CoT 通常比 Zero-Shot-CoT 更强,但它的强依赖人工构造。**人工不只要挑问题,还要写出高质量 reasoning chains;不同任务还需要不同风格的 demonstrations。
为此,作者提出 Auto-CoT:利用 LLM 自己在 Let's think step by step prompt 下生成 reasoning chains,从而自动构造 demonstrations。但这里有一个麻烦:自动生成的 chains 经常包含错误。为缓解这些错误的影响,作者发现 demonstration questions 的 diversity 很重要。
然后作者提了一下实验结果:在十个公开 reasoning benchmarks 上,使用 GPT-3 的 Auto-CoT 能够稳定匹配或超过需要人工 demonstrations 的 Manual-CoT。
三、引言
3.1 为什么要研究 Auto-CoT?
前面的 CoT 论文已经说明:如果在 few-shot prompt 里给模型几个带推理过程的 examples,模型在数学、常识、符号推理任务上会明显变强。形式大概是:
Q: 问题 1
A: 中间推理步骤... The answer is ...
Q: 问题 2
A: 中间推理步骤... The answer is ...
Q: 测试问题
A:
这就是 Manual-CoT。它的问题是人工成本高:
- 要为每个任务挑合适的问题。
- 要为每个问题写合理的 rationale。
- 要保证 rationale 和 final answer 一致。
- 不同任务的 demonstration 风格不一样,比如 arithmetic reasoning、commonsense reasoning、symbolic reasoning 需要的推理过程差异很大。
- prompt 长度有限,人工示例一旦写得不好,还会浪费上下文窗口。
因此,Auto-CoT 的问题意识是:
- 既然 LLM 已经能用 Zero-Shot-CoT 自己生成 reasoning chain,
- 能不能让它先为若干问题生成 rationale,
- 再把这些自动生成的 examples 作为 few-shot CoT demonstrations?
3.2 为什么“直接自动生成”不够?
最朴素的想法是:从数据集中随机选几个问题,然后让模型用 Let's think step by step 生成推理链,最后拼成 demonstrations。
但论文发现,这样会碰到两个问题:
第一,Zero-Shot-CoT 不完美。模型生成的 rationale 可能逻辑不对,或者 rationale 看起来像在推理但最后 answer 错了。
第二,如果用余弦相似度检索选 demonstration questions,错误可能被放大。
直觉上,ICL 里常用 retrieval:给测试问题找最相似的 examples,通常会更有帮助。但在 Auto-CoT 场景中,类似问题可能犯类似错误。如果你给模型一串“和当前问题很像、但都错了”的 demonstrations,模型反而会学习这些错误模式。
作者把这个现象叫做:misleading by similarity
可以理解为“相似性误导”:相似 examples 本来应该帮助模型理解任务,但如果这些 examples 的 reasoning chains 是模型自动生成且带错的,相似性会让错误更有传染性。
3.3 Auto-CoT 的出发点
论文的解决思路是:不要只追求和测试问题相似,而要保证 demonstrations 足够多样。
作者认为,不同 clusters 代表不同问题模式。每个 cluster 选一个代表问题,可以避免所有 demonstrations 都来自同一种问题类型,也降低所有错误 demonstrations 集中在同一个 frequent-error cluster 的风险。
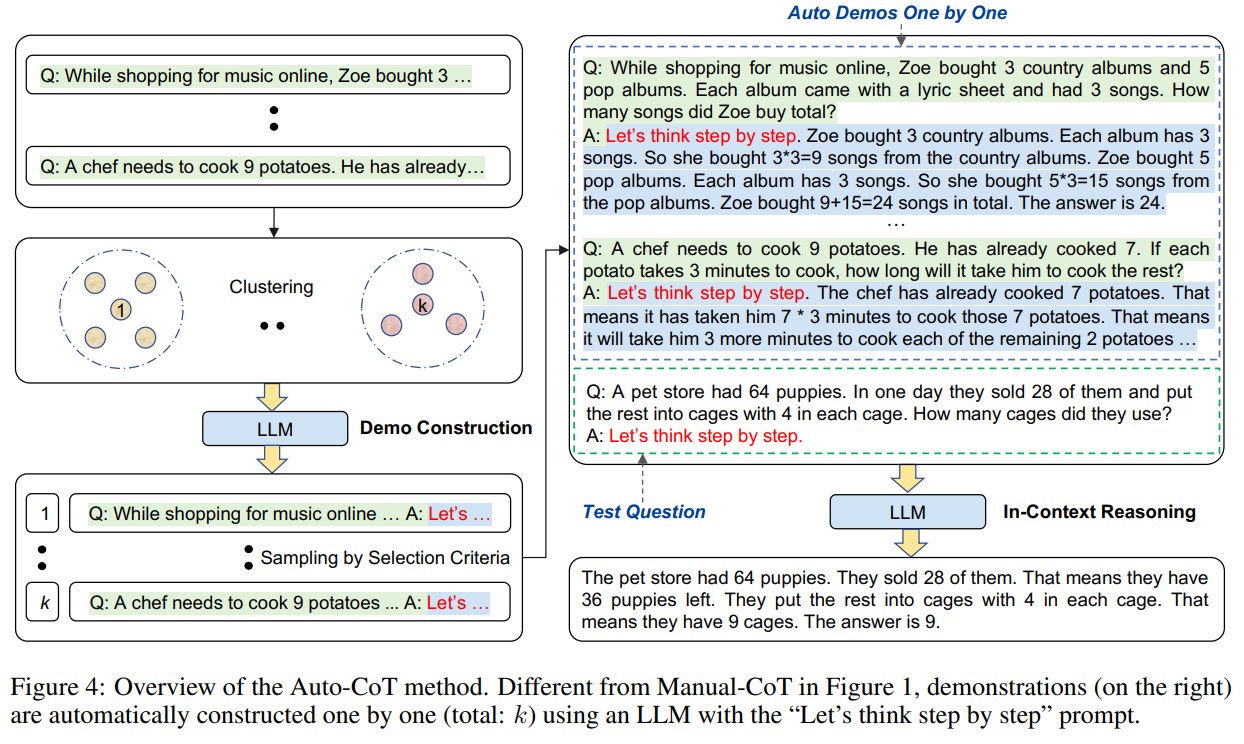
这就得到 Auto-CoT 的两步方法:
Step 1: Question clustering
Step 2: Demonstration sampling
四、背景和相关工作
4.1 Chain-of-Thought Prompting
Chain-of-Thought prompting 是一种不更新模型参数的 prompting 方法。它让 LLM 输出一串中间推理步骤,再给出最终答案。
普通 prompting 通常是:
Q: Roger has 5 tennis balls...
A: 11
CoT prompting 则是:
Q: Roger has 5 tennis balls...
A: Roger starts with 5 balls. He buys 2 cans of 3 balls each...
The answer is 11.
这类中间推理步骤被称为:
rationalereasoning chainintermediate reasoning stepschain of thought
论文把 CoT prompting 分成两个主要范式。

4.2 Zero-Shot-CoT
4.3 Manual-CoT
见:CoT精读
4.4 In-Context Learning
In-Context Learning 指的是不更新模型参数,只通过 prompt 中的 examples 让模型适应任务。GPT-3 的 Language Models are Few-Shot Learners 让这个范式变得很重要。
ICL 研究中一个常见问题是:如何选择 demonstrations?
已有工作常用这些策略:
- retrieval:根据 test input 检索相似 examples。
- instruction augmentation:加入任务说明。
- calibration:调整输出概率或标签偏置。
- prompt ordering:研究 examples 顺序对结果的影响。
但 Auto-CoT 论文强调,传统 ICL 的很多结论主要来自简单的:
input -> output
而 CoT demonstrations 是更复杂的:
input -> rationale -> output
这就多了两个潜在错误点:
input -> rationale错:推理过程本身错。rationale -> output错:推理过程和最终答案不一致。
因此,不能简单把传统 ICL 的“相似 examples 更好”直接搬到 Auto-CoT 场景中。
4.5 STaR、Self-Consistency、Least-to-Most Prompting
论文还把自己和几条相关路线区分开。
STaR 会让模型生成 rationales,并筛选能得到正确答案的 rationales,再用于训练或迭代改进。它通常需要带 annotated answers 的训练数据。Auto-CoT 考虑的是更难的设定:只有一组问题,没有人工 rationale,也不依赖训练集答案来筛选。
Self-Consistency 通过采样多条 reasoning paths,然后对最终答案投票。它提高的是 inference-time decoding 的稳定性,通常仍以人工 demonstrations 为基础。
Least-to-Most Prompting 把复杂问题分解为子问题,再逐步解决。它关注 problem decomposition,而 Auto-CoT 关注 demonstrations 的自动构造。
五、方法
5.1 问题定义
给定一组问题:
Q = {q1, q2, ..., qn}
目标是自动构造 k 个 CoT demonstrations:
d(1), d(2), ..., d(k)
每个 demonstration 都包含:
Q: question
A: rationale + answer
然后把这些 demonstrations 拼在测试问题前面,让 LLM 进行 in-context reasoning:
Q: demo question 1
A: demo rationale 1 ... The answer is ...
Q: demo question 2
A: demo rationale 2 ... The answer is ...
...
Q: test question
A: Let's think step by step.
注意,Auto-CoT 不改变模型参数,也不训练一个新模型。它改变的是 prompt 中 demonstrations 的构造方式。
5.2 Challenge:为什么相似检索会失败?
作者先测试了一个直觉方案:Retrieval-Q-CoT。
流程是:
- 对测试问题
q_test,用 Sentence-BERT 找到最相似的k个问题。 - 对这些相似问题用 Zero-Shot-CoT 生成 reasoning chains。
- 把这些自动生成的 question-chain pairs 当作 demonstrations。
- 再让模型回答
q_test。
结果在 MultiArith 上反而不好:
| 方法 | MultiArith | GSM8K | AQuA |
|---|---|---|---|
Zero-Shot-CoT |
78.7 | 40.7 | 33.5 |
Manual-CoT |
91.7 | 46.9 | 35.8 |
Random-Q-CoT |
86.2 | 47.6 | 36.2 |
Retrieval-Q-CoT |
82.8 | 48.0 | 39.7 |
在 MultiArith 上,Retrieval-Q-CoT 是 82.8,低于 Random-Q-CoT 的 86.2。这说明:当 demonstrations 的 rationale 是自动生成而非人工标注时,相似检索不一定可靠。
作者进一步分析发现:
- Zero-Shot-CoT 在 MultiArith 上失败了
128/600 = 21.3%的问题。 - 对这些 Zero-Shot-CoT 已经失败的问题,
Retrieval-Q-CoT的 unresolved rate 是46.9%。 Random-Q-CoT的 unresolved rate 是25.8%。
unresolved rate 可以理解为:原来 Zero-Shot-CoT 做错的问题,在加了 demonstrations 后仍然做错的比例。比例越高,说明这个方法越没有把错误救回来。
为什么 Retrieval-Q-CoT 更糟?因为它找的是相似问题。如果相似问题本身都被 Zero-Shot-CoT 生成了错误 reasoning chains,测试问题就会被类似错误反复暗示。
论文给了一个很直观的例子:几个问题都在问 “how long will it take him to cook the rest?”,错误 demonstrations 把 “the rest” 理解成了总时间,模型看了这些相似错误后,也跟着犯同样错误。
这就是:
misleading by similarity
5.3 Frequent-Error Cluster:错误会聚集
作者用 Sentence-BERT 编码 MultiArith 的 600 个问题,再用 k-means 分成 k = 8 个 clusters。然后统计每个 cluster 中 Zero-Shot-CoT 的错误率。
结果发现,错误不是均匀分布的。有一个 cluster 的错误率达到 52.3%,论文称这种 cluster 为:frequent-error cluster
这件事很关键。它说明模型不是随机犯错,而是在某些问题模式上系统性薄弱。如果 retrieval 方法总是从相似问题里取 demonstrations,就可能一次取到多个来自同一 frequent-error cluster 的错误 demonstrations。
用更直观的话说:
- 如果模型不会某类题,那么和这类题最像的 examples 很可能也被模型写错。
- 这些相似的错例被一起放进 prompt,就会让模型更确信错误模式。
5.4 Diversity 的作用
Auto-CoT 的核心洞察是:既然错误可能集中在某些 cluster 中,那就不要让 demonstrations 全部来自一个局部区域,而要让 demonstrations 覆盖多个 clusters。
假设要构造 8 个 demonstrations,并且错误主要集中在一个 frequent-error cluster。如果每个 cluster 只选一个问题,那么最多只会从这个高风险 cluster 里拿一个 demonstration。即使这个 demonstration 错了,其他 clusters 的 demonstrations 仍然可能是对的。
论文中的直觉是:少量错误 demonstrations 不一定会明显伤害性能;真正危险的是大量相似错误 demonstrations 一起出现。
因此,Auto-CoT 采用:diversity-based sampling
具体实现就是先聚类,再每个 cluster 取一个代表问题。
5.5 Stage 1:Question Clustering
Auto-CoT 第一阶段是 Question clustering。
输入是一组问题 Q 和要构造的 demonstration 数量 k。
算法步骤:
- 对每个 question 用
Sentence-BERT编码。 - 得到每个问题的向量表示。
- 用
k-means把所有问题分成k个 clusters。 - 对每个 cluster 内的问题,按到 cluster center 的距离从近到远排序。
可以写成伪代码:
for each question q in Q:
encode q by Sentence-BERT
cluster all question embeddings into k clusters
for each cluster i:
sort questions by distance to cluster center
这里的 cluster center 可以理解为这个 cluster 的“平均问题模式”。离 center 越近的问题,越像这个 cluster 的代表样本。
一个小例子:
假设数学题被分成 3 类:
- Cluster 1:购物、价格、总价问题。
- Cluster 2:剩余数量、卖出多少、还剩多少问题。
- Cluster 3:时间、速度、每个单位耗时问题。
Auto-CoT 会从每类里选一个代表问题,而不是都选“和测试题最像”的问题。这样 demonstrations 覆盖的问题模式更宽。
5.6 Stage 2:Demonstration Sampling
第二阶段是 Demonstration sampling。
对每个 cluster i:
- 从离 cluster center 最近的问题开始尝试。
- 把问题输入 LLM,并附加:
Let's think step by step.
- 让模型生成 rationale 和 answer。
- 把 question、rationale、answer 拼成 candidate demonstration。
- 检查是否满足 selection criteria。
- 如果满足,就选为该 cluster 的 demonstration;否则尝试 cluster 中下一个问题。
伪代码:
for each cluster i:
for each question q_j in sorted cluster i:
generate rationale r_j and answer a_j using Zero-Shot-CoT
if q_j and r_j satisfy selection criteria:
d(i) = [Q: q_j, A: r_j + a_j]
break
5.7 Simple Heuristics
论文使用一些简单但有效的 heuristics 来过滤候选 demonstrations。
主要规则是:
question <= 60 tokens
rationale <= 5 reasoning steps
对算术推理任务,除了 AQuA 这类 multiple-choice task,论文还要求:
extracted answer is not empty
extracted answer appears in the rationale
为什么这些规则有用?
第一,短问题通常更简单,模型更可能生成正确 rationale。
第二,短 rationale 更不容易发散,也更不容易出现自相矛盾。
第三,如果答案没有出现在 rationale 中,说明 rationale 和 answer 可能脱节,也就是 rationale-answer mismatch。
例如一个错误 demonstration 可能是:
推理过程中算出 63,但最后写 The answer is 78.
这种示例非常危险,因为模型可能学到“看起来像推理,但最终答案没有依据”的模式。
5.8 最终 Prompt 如何使用?
当 Auto-CoT 选出 k 个 demonstrations 后,会把它们按如下形式拼接:
Q: demo question 1
A: demo rationale 1. The answer is answer 1.
Q: demo question 2
A: demo rationale 2. The answer is answer 2.
...
Q: test question
A: Let's think step by step.
LLM 看到前面的自动 demonstrations 后,会继续按同样格式生成测试问题的 rationale 和 answer。
六、实验
6.1 实验设置
论文在十个公开 reasoning benchmarks 上评估 Auto-CoT,覆盖三类任务。
| 类型 | 数据集 |
|---|---|
| Arithmetic reasoning | MultiArith, GSM8K, AddSub, AQuA, SingleEq, SVAMP |
| Commonsense reasoning | CSQA, StrategyQA |
| Symbolic reasoning | Last Letter Concatenation, Coin Flip |
主要模型是 GPT-3 text-davinci-002,参数规模 175B。默认使用 greedy decoding:
temperature = 0
max_tokens = 256
demonstrations 数量一般是 k = 8,但有几个例外:
- AQuA:
k = 4 - Last Letter Concatenation:
k = 4 - CSQA:
k = 7 - StrategyQA:
k = 6
对比方法包括:
Zero-ShotZero-Shot-CoTFew-ShotManual-CoTAuto-CoT
6.2 主结果:Auto-CoT 匹配或超过 Manual-CoT
Table 3 是论文最核心的结果。
| 方法 | MultiArith | GSM8K | AddSub | AQuA | SingleEq | SVAMP | CSQA | Strategy | Letter | Coin |
|---|---|---|---|---|---|---|---|---|---|---|
Zero-Shot |
22.7 | 12.5 | 77.0 | 22.4 | 78.7 | 58.8 | 72.6 | 54.3 | 0.2 | 53.8 |
Zero-Shot-CoT |
78.7 | 40.7 | 74.7 | 33.5 | 78.7 | 63.7 | 64.6 | 54.8 | 57.6 | 91.4 |
Few-Shot |
33.8 | 15.6 | 83.3 | 24.8 | 82.7 | 65.7 | 79.5 | 65.9 | 0.2 | 57.2 |
Manual-CoT |
91.7 | 46.9 | 81.3 | 35.8 | 86.6 | 68.9 | 73.5 | 65.4 | 59.0 | 97.2 |
Auto-CoT |
92.0 | 47.9 | 84.8 | 36.5 | 87.0 | 69.5 | 74.4 | 65.4 | 59.7 | 99.9 |
几个关键对比:
- MultiArith:Auto-CoT
92.0 vs 91.7,略高于 Manual-CoT。 - GSM8K:Auto-CoT
47.9 vs 46.9。 - AQuA:Auto-CoT
36.5 vs 35.8。 - Coin Flip:Auto-CoT
99.9 vs 97.2。
这说明,自动构造的 demonstrations 不只是能用,而且在这些 benchmark 上可以达到与人工 demonstrations 相当甚至更好的结果。
但要注意,这不代表自动示例永远比人工示例好。论文中 Manual-CoT 的 demonstrations 有时被多个 arithmetic datasets 复用,而 Auto-CoT 是为每个 dataset 单独自动构造的,所以它更 task-adaptive。
6.3 不同 LLM:Codex 上也有效
论文还用 Codex code-davinci-002 做了额外实验。
| 方法 | MultiArith | GSM8K | AddSub |
|---|---|---|---|
Zero-Shot-CoT |
64.8 | 31.8 | 65.6 |
Manual-CoT |
96.8 | 59.4 | 84.6 |
Auto-CoT |
93.2 | 62.8 | 91.9 |
这里可以看到:
- MultiArith 上 Auto-CoT
93.2,低于 Manual-CoT96.8,但仍然很接近。 - GSM8K 上 Auto-CoT
62.8,高于 Manual-CoT59.4。 - AddSub 上 Auto-CoT
91.9,高于 Manual-CoT84.6。
这个实验说明 Auto-CoT 不只是对 text-davinci-002 有效,在另一个强 LLM 上也有竞争力。
6.4 Demonstration 元素消融:rationale 和 answer 很关键
论文在 Appendix A.1 中分析 demonstration 的组成元素。一个 CoT demonstration 可以看成:
<question, rationale, answer>
作者分别打乱 question、rationale、answer,观察性能变化。
| 方法 | Accuracy |
|---|---|
Manual-CoT |
91.7 |
Shuffle Questions |
73.8 |
Shuffle Rationales |
43.8 |
Shuffle Answers |
17.0 |
结果说明:
- 打乱 questions 后,性能从
91.7降到73.8,仍然保留不少能力。 - 打乱 rationales 后,性能从
91.7降到43.8。 - 打乱 answers 后,性能从
91.7降到17.0。
也就是说,破坏 rationale 或 answer 会造成非常明显的下降:91.7 -> 43.8 / 17.0。
这说明在 CoT demonstrations 中,rationale-answer consistency 非常关键。模型不是只看问题表面,也会学习 rationale 如何导向 answer。如果 rationale 和 answer 不一致,prompt 会教给模型一种错误模式。
这也解释了为什么 Auto-CoT 需要 heuristics 检查 answer 是否出现在 rationale 中。
6.5 Sampling 消融:选 cluster center 附近的问题更好
论文比较了 cluster 内不同选样策略。
| 方法 | MultiArith |
|---|---|
Auto-CoT |
93.7 |
In-Cluster Min Dist |
93.7 |
In-Cluster Random |
89.2 |
In-Cluster Max Dist |
88.7 |
这里的 In-Cluster Min Dist 指选离 cluster center 最近的问题,也就是 Auto-CoT 的策略。结果显示,越接近 cluster center 的问题通常越适合当 demonstration。
直觉上,cluster center 附近的问题更“典型”,不太像离群点;典型问题更容易生成短、清晰、稳定的 rationale,也更适合作为 prompt 示例。
6.6 Simple Heuristics 的效果
Table 9 比较了使用 simple heuristics 前后,自动构造 demonstrations 中错误 rationales 的平均数量。
| 数据集 | Num. of Demos | Simple heuristics | w/o heuristics |
|---|---|---|---|
| MultiArith | 8 | 0.3 | 1.3 |
| AddSub | 8 | 1.7 | 5.0 |
| GSM8K | 8 | 1.7 | 3.0 |
| AQuA | 4 | 1.0 | 2.7 |
| SingleEq | 8 | 1.0 | 2.0 |
| SVAMP | 8 | 0.7 | 3.3 |
| CSQA | 7 | 2.7 | 3.3 |
| StrategyQA | 6 | 2.3 | 2.3 |
| Letter | 4 | 0.0 | 3.0 |
| Coin | 8 | 0.0 | 1.0 |
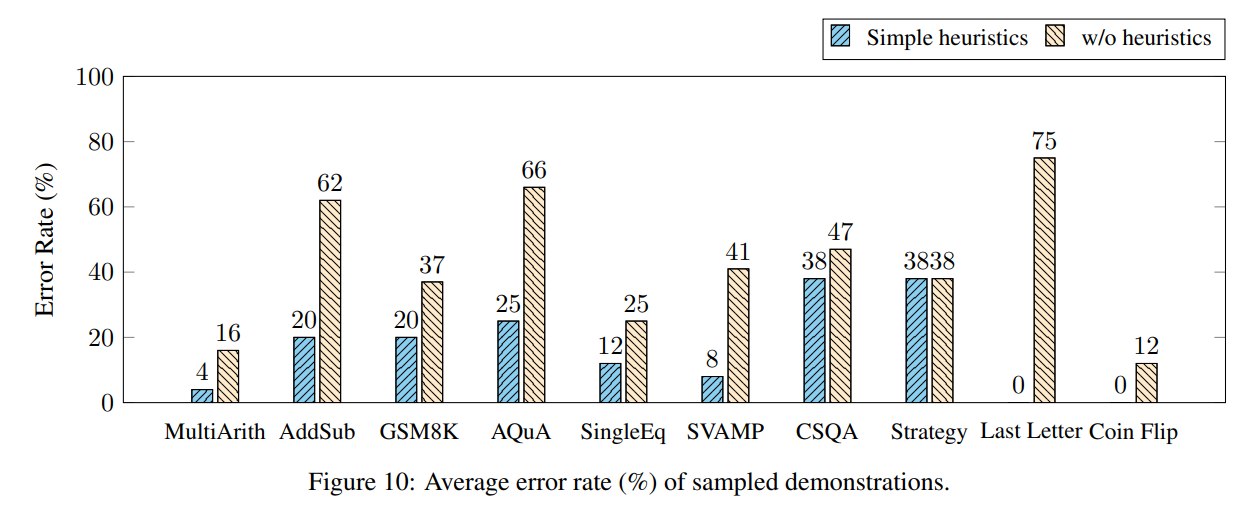
Figure 10 进一步显示,使用 simple heuristics 后,10 个任务中有 7 个任务的 sampled demonstrations error rate 低于 20%。
这个结果说明,虽然 heuristics 很简单,但确实能过滤掉一批坏 demonstrations。尤其是对于 Last Letter 和 Coin Flip,heuristics 后错误 rationales 数量降到 0.0。
6.7 Wrong Demonstrations:Auto-CoT 对错误示例更鲁棒
论文专门研究了 wrong demonstrations 的影响。
作者设计了 In-Cluster Sampling baseline:从包含测试问题的同一个 cluster 中随机采样 demonstrations。这样做会增加相似错误集中出现的风险。
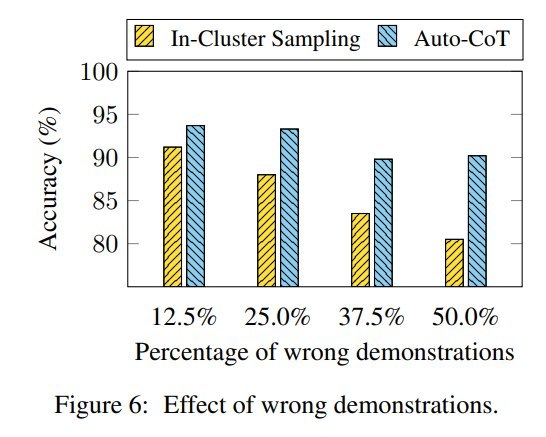
Figure 6 比较了不同 wrong demonstrations 比例下的性能。结论是:
相比 In-Cluster Sampling,Auto-CoT 对 wrong demonstrations 更鲁棒;
即使 50% demonstrations 是 wrong demonstrations,Auto-CoT 的性能也没有显著下降。
这个实验支持了论文前面的核心判断:少量错误不可怕,可怕的是相似错误集中出现。Auto-CoT 的 diversity-based clustering 能把风险摊开。
6.8 Streaming Setting:Auto-CoT*
前面的 Auto-CoT 默认可以看到一整批 test questions,并从中聚类选 demonstrations。但现实中,有时问题是 stream 形式来的:每次只来一小批。
论文提出了 Auto-CoT*,也就是 bootstrapping version。
流程是:
- 初始化空集合
M0。 - 第 1 个 batch 到来时,由于问题太少,不做 clustering,直接对每个问题用 Zero-Shot-CoT 生成 reasoning chain,并存入 memory。
- 从第 2 个 batch 开始,用已经积累的问题和 chains 构造 demonstrations。
- 对当前 batch 做 in-context reasoning。
- 把当前 batch 的 question-chain pairs 继续加入 memory。
论文在 MultiArith 上用 batch size m = 30 测试。结果显示:
- 第 1 batch:Auto-CoT* 和 Zero-Shot-CoT 一样。
- 从第 2 batch 开始:Auto-CoT* 很快接近 Manual-CoT。
这个实验说明,Auto-CoT 不一定要求一开始就拥有完整测试集;它也可以在 streaming 场景中逐步积累 demonstrations。
七、总结和展望
7.1 论文贡献
这篇论文的主要贡献可以总结为四点。
第一,提出 Auto-CoT,自动构造 CoT demonstrations,减少 Manual-CoT 的人工设计成本。
第二,指出自动生成 reasoning chains 会带来 wrong demonstrations,因此示例选择不能只追求 similarity。
第三,提出并验证 misleading by similarity:相似问题上的错误 chains 会诱导模型在测试问题上重复同类错误。
第四,用 question clustering + demonstration sampling + simple heuristics 的简单流程,在十个 reasoning benchmarks 上匹配或超过 Manual-CoT。
7.2 局限
Auto-CoT 的局限也比较明显。
第一,它依赖 LLM 已经具备一定 Zero-Shot-CoT 能力。如果基础模型太弱,自动生成的 rationales 质量会很差,后续 clustering 和 heuristics 也救不回来。
**第二,simple heuristics 只能过滤明显坏例子,不能真正验证推理是否正确。**比如一个 rationale 可以短、答案也出现在 rationale 中,但逻辑仍然错误。
第三,Auto-CoT 默认从同一任务的一组问题中采样 demonstrations。如果任务问题很少,或者问题分布不稳定,clustering 的效果会受影响。
第四,论文主要关注 prompting,不涉及模型训练。因此它不能从根本上提升模型推理能力,只是在 inference-time 更好地组织上下文。
第五,自动 demonstrations 的质量可能受 LLM 版本、解码参数、answer extraction 规则影响。论文使用 temperature = 0 和 greedy decoding,但不同模型时代的表现可能不同。

说些什么吧!