
零、写在前面
这篇工作展示一个很简单的 prompting 形式如何在足够大的语言模型上激发多步推理能力。
一、标题
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
作者来自 Google Research, Brain Team
即,思维链提示能够在大语言模型中激发推理能力
标题里有三个关键词:
Chain-of-Thought Prompting:论文提出并系统评估的方法,即在 few-shot exemplars 中加入中间推理步骤。Elicits:不是训练出、不是微调出,而是“诱发/激发”已有模型表现出某种能力。Large Language Models:这篇论文反复强调 CoT 的收益高度依赖模型规模,小模型通常不能稳定受益。
这个标题的核心判断是:大模型可能已经具备某些潜在的多步推理能力,但标准 prompting 没有把它们充分调动出来;CoT prompting 提供了一种简单的“解锁方式”。
二、摘要
论文的摘要可以拆成四点理解。
第一,作者研究的是让模型生成一串中间推理步骤,也就是 chain of thought。这些步骤不是最终答案本身,而是从问题到答案之间的自然语言推理过程。
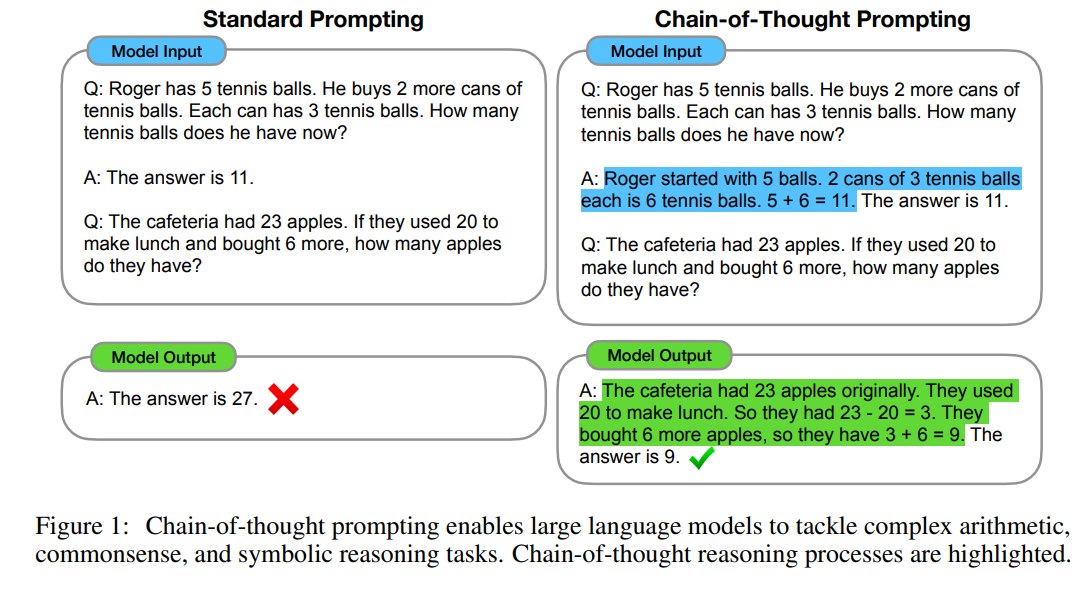
第二,方法非常简单:在 few-shot prompt 中,不只给 input -> output,而是给:
input -> chain of thought -> output
也就是说,模型在测试时看到的示例不是直接回答,而是先展示“怎么想”,再给答案。
第三,实验覆盖三类任务:
- arithmetic reasoning:算术/数学文字题。
- commonsense reasoning:常识推理。
- symbolic reasoning:符号操作和状态追踪。
第四,最亮眼的结果是 PaLM 540B 只用 8 个 CoT exemplars,就在 GSM8K 数学文字题上达到当时很强的效果,并超过带 verifier 的 finetuned GPT-3。
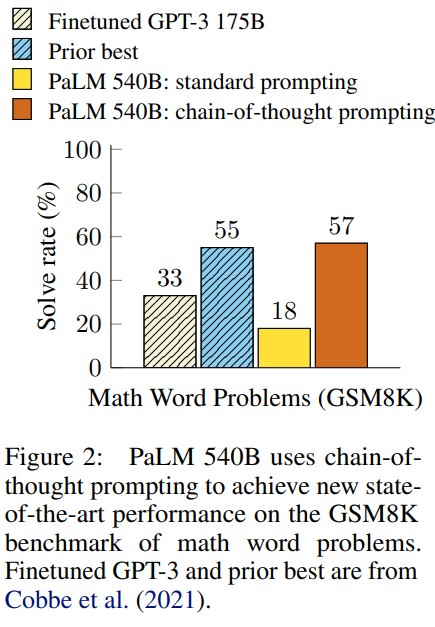
总的来说就是,CoT prompting 通过在 few-shot 示例中显式展示中间推理步骤,让足够大的语言模型在多步推理任务上显著优于标准 prompting。
这篇论文的摘要非常典型:先定义现象,再给方法,再给实验范围,最后给一个高冲击结果。它没有急着解释 CoT 为什么有效,而是先让读者看到“一个简单方法带来很大收益”。对于 NeurIPS 这类论文,这种写法很有效,因为贡献点不在技术复杂度,而在发现和系统验证。
三、引言
3.1 背景:大模型很强,但推理仍然困难
论文从当时 NLP 的主线切入:预训练语言模型规模不断增大,带来了更好的性能和样本效率。但作者指出,仅仅扩大模型规模,并不能自动保证模型在复杂推理任务上表现好。
这里的复杂推理主要包括:
- 多步数学文字题。
- 需要背景知识和多跳推理的常识问题。
- 对符号进行规则化操作的任务。
标准 few-shot prompting 通常给模型几个输入输出例子,例如:
Q: Roger has 5 tennis balls...
A: The answer is 11.
这种格式对简单问答很有效,但对多步推理不够。模型只看到最终答案,没有看到从问题到答案的路径。
3.2 两条前人路线
作者把自己的工作放在两条路线的交汇处。
第一条路线是 rationale / explanation / intermediate steps。很多数学推理系统发现,如果让模型学习中间推理步骤,性能会更好。但这类方法通常需要训练或微调,需要大量带 reasoning rationale 的数据,标注成本高。
第二条路线是 in-context few-shot learning。GPT-3 展示了只靠 prompt 示例就能让模型做新任务的能力。但标准 few-shot prompting 对复杂推理任务效果不稳定。
CoT prompting 的漂亮之处在于,它试图结合二者优点:
- 既利用自然语言中间步骤,又不需要对模型做 finetuning。
3.3 本文核心主张
作者提出:对推理任务,不应只给 input-output 示例,而应给 input-chain-of-thought-output 示例。模型在生成时也会先输出中间步骤,再输出最终答案。
这个主张背后有一个很重要的思路:推理能力不一定只来自参数更新,也可能通过上下文中的示范被激活。
这就是 CoT 与 in-context learning 的关系。CoT 不是替代 ICL,而是 ICL 的一种特殊形式:它改变了 in-context exemplars 的输出格式。
3.4 为什么 CoT 可能有用
论文列出 CoT 的几个吸引人之处:
- 它允许模型把复杂问题拆成中间步骤。
- 它让模型可以为难题分配更多生成 token,相当于增加推理过程中的计算。
- 它提供了一个可观察的中间窗口,方便人类检查模型哪里推错。
- 它的适用范围广,只要人类能用语言分步解决,就原则上可以尝试 CoT。
- 它不需要训练新模型,只需要改 prompt。
这里要小心一点:论文说 CoT 给了一个 interpretable window,但并没有证明这些文本步骤就是模型内部真实因果机制。后来的研究也反复讨论这个问题:CoT 可能是解释,也可能只是模型生成答案时的外显轨迹。
四、相关工作
4.1 Prompting 与 in-context learning
CoT 属于 prompting 方法的一种。GPT-3 的 few-shot learning 展示了模型可以通过上下文示例学习任务格式。后续 work 包括:
- 自动学习 prompt。
- instruction prompting。
- prompt tuning / prefix tuning。
- instruction tuning。
这些方法大多是在增强输入侧,例如给任务说明、学习软提示、优化 prompt 模板。CoT 的不同之处在于,它主要增强输出侧:
- 不是只告诉模型“任务是什么”,而是展示“解决任务时应该如何展开中间过程”。
4.2 Natural Language Explanations
自然语言解释相关工作通常关心模型解释性,尤其是在 NLI 或分类任务中,让模型同时生成预测和解释,或在答案后生成解释。
CoT 和 explanation 很像,但目标不同:
- Natural Language Explanation:重点常是解释模型为什么给出某个答案。
- Chain of Thought:重点是让模型通过中间步骤得到答案。
论文特别强调,CoT 发生在最终答案之前,而很多 explanation 工作发生在答案之后。这个顺序差异很关键,因为 CoT 的中间文本会影响后续答案生成。
4.3 数学推理与自然语言 rationale
数学文字题领域早就有人使用 intermediate steps。比如 Ling et al. 使用自然语言 rationale 训练模型解决数学题;Cobbe et al. 构建 GSM8K,并用带解释的数据微调模型。
CoT 的区别是:不用为目标任务训练一个新模型,而是在 prompt 中放少量带中间步骤的示例。
这让 CoT 更像一种通用激发方法,而不是任务专用训练方法。
4.4 Program synthesis / execution
程序合成和程序执行领域也长期使用中间步骤。例如让模型逐行预测程序执行结果,或生成可执行程序再运行。程序化推理很强,但通常依赖特定形式语言或执行器。
CoT 的路线更开放:它用自然语言作为中间表示,而不是固定的 formal language。
优点是适用范围广;缺点是自然语言不保证可执行、可验证,也容易出现表面合理但实际错误的推理。
4.5 Numeric and logical reasoning
数值推理和逻辑推理传统上会引入外部模块,例如计算器、符号系统、图神经网络或预定义操作。CoT 不直接引入外部工具,而是让语言模型用文本表达推理过程。
不过论文也在附录中提到,给 CoT 加 external calculator 可以进一步提升 arithmetic 任务。这其实预示了后来的一个重要方向:CoT + tools。
五、定义
5.1 Chain of Thought
论文给出的核心定义是:chain of thought 是一系列中间自然语言推理步骤,它们通向最终答案。
形式上,标准 prompting 是:
示例 1: input -> output
示例 2: input -> output
...
测试: input -> ?
CoT prompting 是:
示例 1: input -> chain of thought -> output
示例 2: input -> chain of thought -> output
...
测试: input -> chain of thought -> output
更紧凑地说,prompt 示例从二元组变成三元组:
<input, chain of thought, output>
5.2 Standard Prompting
Standard prompting 只展示问题和答案。例如:
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls.
Each can has 3 tennis balls. How many tennis balls does he have now?
A: The answer is 11.
模型学到的是输入到答案的映射,但没有看到推理过程。
5.3 Chain-of-Thought Prompting
CoT prompting 在答案前加入推理过程。例如:
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls.
Each can has 3 tennis balls. How many tennis balls does he have now?
A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls.
5 + 6 = 11. The answer is 11.
这个例子里,中间步骤做了三件事:
- 抽取已知条件。
- 把自然语言关系转成数学关系。
- 计算并给出最终答案。
5.4 CoT 与 explanation 的区别
这篇论文有一个细微但重要的措辞:作者更愿意叫 chain of thought,而不是 solution 或 explanation。
原因是:
- solution/explanation 往往是在答案之后解释。
- chain of thought 是在答案之前展开。
- chain of thought 更像“模型生成答案时的中间过程”。
不过要注意,CoT 文本不一定等于模型内部真实推理。它是一个可见轨迹,但不必然是 faithful explanation。
5.5 CoT 的三个必要条件
根据论文实验和 FAQ,可以总结出 CoT 更可能有效的条件:
- 任务需要多步推理。
- 使用足够大的语言模型。
- 标准 prompting 的 scaling curve 比较平,仍有提升空间。
反过来,如果任务很简单、模型很小、标准 prompting 已经接近天花板,CoT 的收益就会很小,甚至可能负收益。
六、各种推理
论文系统评估了三类推理:算术推理、常识推理、符号推理。它们对应不同能力:数值计算、多跳常识、抽象规则操作。
6.1 算术推理
任务设置
算术推理主要是 math word problems。论文评估了五个数据集:
| 数据集 | 任务特点 |
|---|---|
| GSM8K | 小学数学文字题,多步推理,难度较高 |
| SVAMP | 结构变化更丰富的数学文字题 |
| ASDiv | 多样化数学文字题 |
| AQuA | 代数文字题,多选形式 |
| MAWPS | 数学文字题集合,包含不同难度子集 |
实验比较:
- standard prompting:只给问题和答案。
- chain-of-thought prompting:给问题、中间推理、答案。
作者手写了 8 个带 CoT 的 few-shot exemplars,并把同一组 exemplars 用在多数数学数据集上。
关键结果
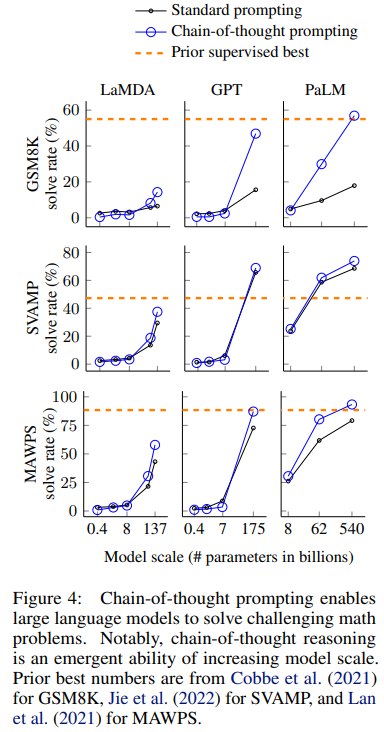
最重要的结论是:CoT 对大模型的提升非常明显,对小模型则不稳定。
以 PaLM 540B 为例:
| 数据集 | Standard | CoT | 提升 |
|---|---|---|---|
| GSM8K | 17.9 | 56.9 | +39.0 |
| SVAMP | 69.4 | 79.0 | +9.6 |
| ASDiv | 72.1 | 73.9 | +1.8 |
| AQuA | 25.2 | 35.8 | +10.6 |
| MAWPS | 79.2 | 93.3 | +14.2 |
GPT-3 175B 也有明显提升:
| 数据集 | Standard | CoT |
|---|---|---|
| GSM8K | 15.6 | 46.9 |
| MAWPS | 72.7 | 87.1 |
Codex 在 GSM8K 上更强:
- Codex standard: 19.7
- Codex CoT: 63.1
论文主文强调,PaLM 540B + CoT 在 GSM8K 上达到新的 state-of-the-art 水平,并超过带 verifier 的 finetuned GPT-3。
为什么复杂题更受益
论文进一步分析 MAWPS 的不同子集。对于 SingleOp、SingleEq、AddSub 这些一两步就能解决的问题,大模型 standard prompting 已经很强,CoT 提升很小。
但对于 MultiArith,多步结构更明显,CoT 提升很大。例如 PaLM 540B:
- MultiArith standard: 42.2
- MultiArith CoT: 94.7
这说明 CoT 的强项不是“让模型多说一点”,而是帮助模型在需要中间状态的复杂任务上分解问题。
消融实验
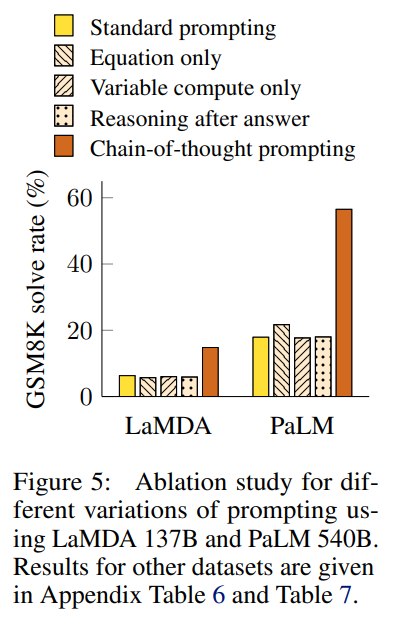
作者做了三个重要 ablation:
| 变体 | 目的 | 结论 |
|---|---|---|
| equation only | 只输出方程,不输出自然语言推理 | 对简单题有帮助,对 GSM8K 不够 |
| variable compute only | 输出一串点,控制生成 token 数 | 仅增加 token 数不是关键 |
| reasoning after answer | 先答,再解释 | 效果接近 baseline,说明答案前的顺序推理重要 |
其中 reasoning after answer 很关键。它说明 CoT 不是简单地“激活知识”或“多生成解释”,而是中间步骤参与了最终答案生成。
错误分析
作者人工分析 LaMDA 137B 在 GSM8K 上的生成:
- 对 50 个最终答案正确的样本,绝大多数 CoT 逻辑和数学也是正确的,只有少数是碰巧答对。
- 对 50 个最终答案错误的样本,约 46% 的 CoT 接近正确,只差计算器错误、符号映射错误或少一步推理。
- 约 54% 有更严重问题,通常涉及语义理解错误或推理不连贯。
这说明 CoT 虽然可读,但仍然可能错。错误可能发生在:
- 算术计算。
- 把文本中的量映射到变量。
- 漏掉一个中间步骤。
- 误解题意。
- 生成看似连贯但实际不成立的推理。
6.2 常识推理
任务设置
常识推理测试模型是否能利用背景知识和多跳推理。论文使用五类任务:
| 数据集 | 推理类型 |
|---|---|
| CSQA | 常识问答,通常需要世界知识 |
| StrategyQA | yes/no 问题,需要隐含多跳策略 |
| Date Understanding | 根据上下文推日期 |
| Sports Understanding | 判断体育相关句子是否合理 |
| SayCan | 将自然语言指令映射为机器人动作序列 |
这类任务的共同点是:答案不只是计算,还需要解释“为什么这个选项更合理”。
关键结果
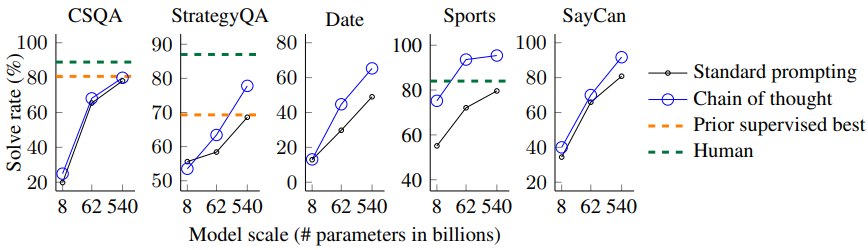
PaLM 540B 的结果如下:
| 数据集 | Standard | CoT | 提升 |
|---|---|---|---|
| CSQA | 78.1 | 79.9 | +1.8 |
| StrategyQA | 68.6 | 77.8 | +9.2 |
| Date | 49.0 | 65.3 | +16.3 |
| Sports | 80.5 | 95.4 | +14.9 |
| SayCan | 80.8 | 91.7 | +10.9 |
其中 StrategyQA 和 Sports Understanding 很突出:
- StrategyQA:PaLM 540B + CoT 达到 77.8,超过论文中提到的 prior supervised best 69.4。
- Sports Understanding:PaLM 540B + CoT 达到 95.4,超过 unaided sports enthusiast 的 84。
但 CSQA 提升很小。论文也明确指出 CoT 在 CSQA 上收益 minimal。
为什么 CSQA 提升小
一个合理解释是:CSQA 很多题更依赖直接常识匹配或选项偏好,而不一定需要展开长链条。CoT 对“需要多步推理”的任务更有效,对“检索式常识选择”帮助有限。
这和论文 FAQ 中的判断一致:CoT 最适合 challenging multi-step reasoning,而不是所有任务通吃。
SayCan 的意义
SayCan 是机器人规划任务,输入是自然语言指令,输出是动作序列。CoT 在这里通常会先解释用户需求,再生成 plan。
这说明 CoT 不只用于文本问答,也可用于“语言到行动序列”的中间规划。它和后来的 agent / planning / tool use 很接近。
6.3 符号推理
任务设置
符号推理部分用了两个合成任务:
- Last Letter Concatenation:取每个词的最后一个字母并拼接。
- Coin Flip:追踪硬币经过若干次翻转后是否仍然 heads up。
这些任务看起来简单,但对语言模型来说不一定自然。它们考察的是:
- 是否能按规则逐步操作符号。
- 是否能追踪状态。
- 是否能泛化到比 exemplars 更长的输入。
论文设计了 in-domain 和 OOD 两种设置:
- in-domain:测试样本的步骤数和 few-shot exemplars 相同。
- OOD:测试样本比 exemplars 更长,例如名字从 2 个词扩展到 3 或 4 个词,硬币翻转步骤更多。
关键结果
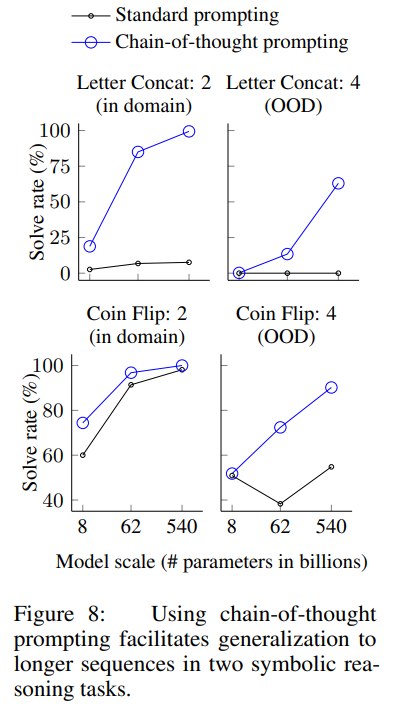
PaLM 540B 在符号任务上的结果很强:
| 任务 | Standard | CoT |
|---|---|---|
| Last Letter 2 words | 7.6 | 99.4 |
| Last Letter 3 words OOD | 0.2 | 94.8 |
| Last Letter 4 words OOD | 0.0 | 63.0 |
| Coin Flip 2 steps | 98.1 | 100.0 |
| Coin Flip 3 steps OOD | 49.3 | 98.6 |
| Coin Flip 4 steps OOD | 54.8 | 90.2 |
这组结果非常有启发:
- 对 Last Letter,standard prompting 几乎不会做,但 CoT 可以把任务拆成“逐词取最后字母 -> 拼接”。
- 对 Coin Flip,PaLM 540B standard 在 2 steps 已经很强,但 OOD 长度泛化接近随机;CoT 能显著维持泛化。
为什么符号推理能体现 CoT 的价值
符号任务不像数学题那样依赖世界知识,也不像常识题那样依赖语义背景。它更像一个规则执行测试。
CoT 在这里的作用是给模型一个可复用的操作模板:
- 先识别每个符号或状态变化;
- 再逐步更新中间状态;
- 最后汇总得到答案。
这说明 CoT 可以帮助模型把“隐式模式匹配”变成“显式步骤执行”。
不过论文也提醒,in-domain toy tasks 中 few-shot 示例已经提供了很完整的解题结构,模型只需要复用这个结构。真正困难的是 OOD 长度泛化,而这部分 CoT 也明显有帮助,但不是完美解决。
6.4 鲁棒性与 prompt engineering
论文还测试了 CoT 对不同 prompt 的敏感性:
- 不同标注者写的 CoT。
- 更简洁的 CoT 风格。
- 从 GSM8K 随机采样的不同 exemplars。
- 不同 exemplar 顺序。
- 不同 exemplar 数量。
- 不同模型族:LaMDA、GPT-3、PaLM。
结论是:CoT 一般比 standard prompting 强,但仍有方差。prompt engineering 仍然重要。
一个典型例子是 coin flip:不同 annotator 的 prompt 可以让表现从 99.6 降到 71.4,虽然仍高于 standard prompting 的 50.0。
这说明 CoT 不是一个完全免调参的方法。它简单、强大,但 prompt 写法仍会显著影响结果。
七、总结与展望
7.1 论文主要贡献
这篇论文的贡献可以总结为四点:
- 提出并命名
chain-of-thought prompting,即在 few-shot exemplars 中加入中间自然语言推理步骤。 - 系统证明 CoT 在 arithmetic、commonsense、symbolic reasoning 上能显著提升大模型表现。
- 发现 CoT 是一种 emergent ability:小模型通常不能稳定受益,足够大的模型才出现明显提升。
- 通过消融和鲁棒性实验说明,CoT 的收益不只是多生成 token,也不是答案后的解释,而是答案前的中间推理过程发挥了作用。
7.2 最重要的认识
这篇论文最值得带走的认识是:
- Prompt 不只是任务描述,也可以是“思考格式”的示范。
标准 prompting 示范的是答案格式;CoT 示范的是解题过程格式。对于大模型来说,这个差异足以显著改变生成行为。
7.3 局限
论文本身也指出了几个局限。
第一,CoT 看起来像人类思考,但不能证明模型内部真的在“推理”。生成的推理文本和模型内部因果机制之间是什么关系,仍然是开放问题。
第二,CoT 不保证推理路径正确。模型可能:
- 最终答案对,但中间推理错。
- 中间推理看似合理,但某一步违反题意。
- 计算出错。
- 多选或二分类任务中靠猜测碰巧答对。
第三,CoT 依赖大模型。论文多次强调,CoT 的收益通常要到百亿甚至千亿参数级别才明显。这意味着服务成本高,也限制了实际应用。
第四,prompt engineering 仍然重要。不同 exemplars、不同写法、不同顺序都会影响结果。
7.4 后续研究方向
这篇论文之后的 CoT 研究可以沿几个方向展开。
方向一:从 few-shot CoT 到 zero-shot CoT
后续研究发现,只加一句类似 “Let’s think step by step” 的指令,也能诱导模型分步推理。这说明模型可能在 instruction 层面也能被激发,而不一定总要 few-shot exemplars。
方向二:从单条 CoT 到多条采样
Self-consistency 方法会采样多条 reasoning paths,再通过多数投票或答案聚合提升稳定性。这是对 CoT 不稳定性的自然修正。
方向三:CoT + tools
论文附录中已经显示 external calculator 能提升 arithmetic 结果。后续 Program-of-Thought、Toolformer、ReAct 等方法进一步把推理步骤和工具调用结合起来。
方向四:faithfulness 与可解释性
CoT 文本是否忠实反映模型内部推理,是一个重要问题。未来需要区分:
- CoT as reasoning process:中间文本真的参与求解。
- CoT as rationalization:模型先有答案,再生成看似合理的解释。
方向五:小模型推理能力
论文指出 CoT 在大模型上才明显涌现。后续可以研究如何通过 distillation、finetuning、RL 或合成数据,把 CoT 能力迁移到小模型。
方向六:多模态 CoT
多模态场景下,CoT 不再只是文本步骤,还可能包含视觉定位、区域引用、图表解析、空间关系推理等。理解这篇 CoT 论文,有助于读后续的 Multimodal CoT、Vision-R1、Qwen3-VL thinking with images 等工作。

说些什么吧!