
零、写在前面
VLMo主要就是试图 dual encoder 和 多模态融合的 fusion encoder 到一个架构里面,然后基于此又提出一个预训练策略,取得了很好的效果。
一、标题
VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
VLMO有两点改进:
- 模型结构上的改进:Mixture-of-Modality-Experts
- 训练方式上的改进:分阶段的模型预训练
二、引言

在之前的工作中,主要是两种架构:
- Dual encoder:CLIP、ALIGN 等。它们分别编码图像和文本,然后通过 dot product 计算相似度。这种结构非常适合 image-text retrieval,因为每张图像和每段文本都可以预先编码,检索时只需要向量匹配。但它的缺点也明显:图像 token 和文本 token 没有经过深层交互,因此在 VQA、NLVR2 这类需要细粒度推理的任务上能力有限。
- Fusion encoder:UNITER、OSCAR、VinVL、ALBEF 等。它们将 image tokens 和 text tokens 输入同一个 multimodal Transformer,学习 token-level cross-modal interaction。这类模型在分类、匹配和推理任务上更强,但检索时成本很高。因为如果要判断一张图和大量文本是否匹配,模型必须对大量 image-text pairs 分别做 fusion encoding。
VLMO 的动机就是统一这两种范式:
- 像 dual encoder 一样,可以独立编码图像和文本,用于高效 retrieval;
- 像 fusion encoder 一样,可以联合编码图文,用于 VQA、NLVR2 等需要深层交互的任务;
- 同时尽量共享参数,避免为不同任务维护完全独立的模型。
引言中另一个重要动机是模态差异。图像、文本和图文联合输入虽然可以共用 Transformer 的某些能力,例如 attention-based token interaction,但它们也有不同的分布和建模需求。如果所有模态完全共享 FFN,模型可能难以同时捕获视觉特定、语言特定和跨模态特定信息;如果所有模块完全分开,又失去统一模型的参数共享优势。
MoME(Mixture-of-Modality-Experts) Transformer 的设计正是折中方案:
- 共享 self-attention:促进不同模态在同一注意力机制下对齐和交互;
- 分离 FFN experts:为视觉、语言和图文融合保留各自的非线性变换能力。
引言最后强调 stagewise pre-training:
- VLMO 先从 image-only 和 text-only 数据中学习单模态表示;
- 再用 image-text pairs 学习跨模态对齐与融合。
这种训练顺序可以看作对 ViLT、ALBEF 之后问题的进一步推进:不仅要 align before fuse,还要让同一模型能够在单模态和多模态场景中复用。
三、Method
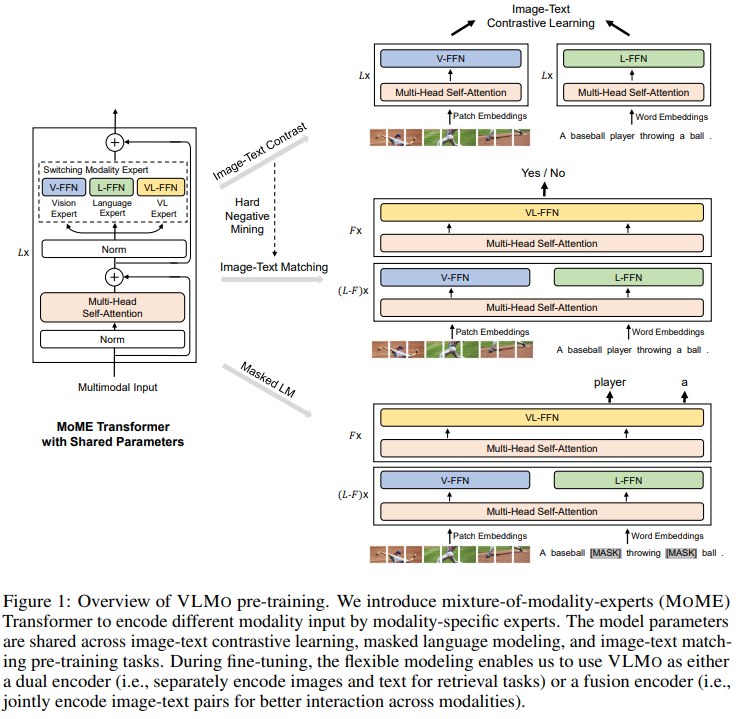
3.1 输入表示
VLMO 支持三类输入:image-only、text-only 和 image-text。
3.1.1 Image representations
图像被切成 16 x 16 patches,每个 patch 通过 linear projection 映射到 hidden dimension。模型还加入 [I_CLS] token、position embedding 和 image type embedding。
这一路径使 VLMO 可以像 ViT/BEIT 一样作为 image encoder 使用,也可以在 image-text retrieval 中作为 dual encoder 的 image branch。
3.1.2 Text representations
文本使用 BERT WordPiece tokenizer。输入包含 [T_CLS]、文本 tokens 和 [T_SEP],并加入 word embedding、position embedding 和 text type embedding。
这一路径使 VLMO 可以独立编码文本,作为 retrieval 中的 text branch。
3.1.3 Image-text representations
对于 image-text 输入,VLMO 将 text input vectors 和 image input vectors 拼接后输入 MOME Transformer。此时模型可以使用 shared self-attention 在视觉 token 和文本 token 之间建立交互,并在顶层使用 vision-language expert 学习融合表示。
Q:img token 和 text token 拼接后embedding 维度不会增加吗?
A:
不会,这里的拼接不是在特征维度拼接,拼接后只会增加序列数量,特征维度不变。
3.2 MoME Transformer
MOME Transformer 是 VLMO 的核心结构。一个标准 Transformer block 通常包含:
- Multi-Head Self-Attention;
- Feed-Forward Network;
- residual connection 与 layer normalization。
VLMO 保留 shared self-attention,但将 FFN 替换为 modality experts:
| 输入类型 | 使用的 FFN expert |
|---|---|
| Image-only | V-FFN |
| Text-only | L-FFN |
| Image-text 中的底层 token | 按 token modality 使用 V-FFN 或 L-FFN |
| Image-text 顶层融合 | VL-FFN |
- shared self-attention 让不同模态使用同一套 attention 参数,有助于模态对齐;
- modality-specific FFN 允许图像、文本和图文融合分别学习不同的非线性表示。
3.3 预训练目标
VLMO 使用三个 VLP 常见目标:ITC、ITM、MLM。
在前面的架构图中可以看出,VLMO采用了和ALBEF一样的策略,利用ITC来给ITM找 hard negative。
VLMO 的训练分三阶段:
| 阶段 | 数据 | 训练内容 | 作用 |
|---|---|---|---|
| 1. Vision pre-training | image-only data | self-attention + vision expert | 建立视觉表示,采用 BEIT 风格 masked image modeling |
| 2. Language pre-training | text-only data | language expert | 建立语言表示,使用 MLM |
| 3. Vision-language pre-training | image-text pairs | 全模型 + ITC/ITM/MLM | 学习图文对齐、检索和融合能力 |
这种训练顺序有两个好处:
- 避免从弱图文监督中学习全部能力。 图像和文本单模态能力先从更适合的数据中建立。
- 匹配 MOME 的结构。 Vision expert 和 language expert 先分别具备能力,再在 vision-language pretraining 中学习统一。
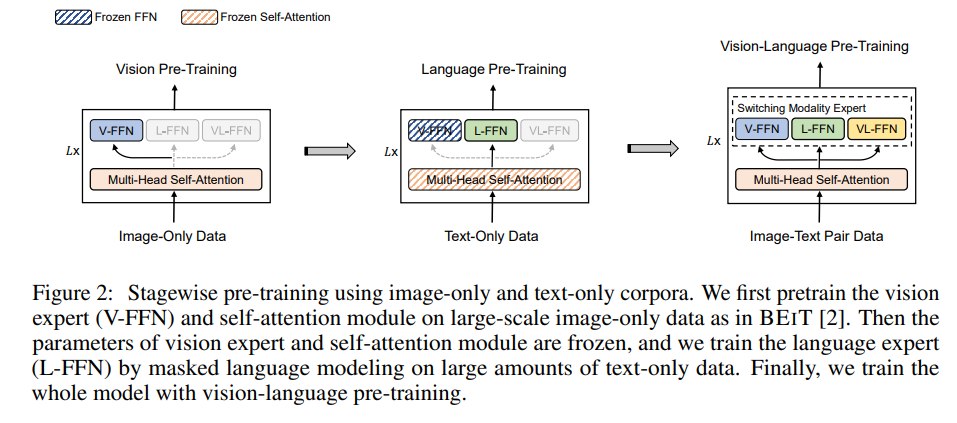
比较有趣的是,第二阶段冻住V-FFN是理所当然的,因为用不到,但是把自注意力层也冻住了,这个就有点奇怪了。
更有趣的是,如果反过来,第一阶段做文本,第二阶段冻住自注意力层和L-FFN,效果反而变差。
四、实验
VLMO的训练成本还是比较高的,基本又回到ViLT那个水平了。
VLMO-Base 和 VLMO-Large 使用常见 4M image 数据组合进行 vision-language pretraining,包括 Conceptual Captions(CC)、SBU Captions、COCO 和 Visual Genome(VG),约 4M images / 10M image-text pairs。
| 项目 | VLMO-Base | VLMO-Large |
|---|---|---|
| Layers | 12 | 24 |
| Hidden size | 768 | 1024 |
| Attention heads | 12 | 16 |
| FFN intermediate size | 3072 | 4096 |
| VL expert layers | top 2 layers | top 3 layers |
| VL pretraining steps | 200k | 200k |
| Batch size | 1024 | 1024 |
| Training cost | 64 V100 约 2 天 | 128 V100 约 3 天 |
论文还训练了 VLMO-Large++,使用 1B noisy web image-text pairs,先用 batch 16k 训练 200k steps,再用 batch 32k 训练 100k steps。这说明 VLMO 可以扩展到更大数据,但也带来显著资源成本。
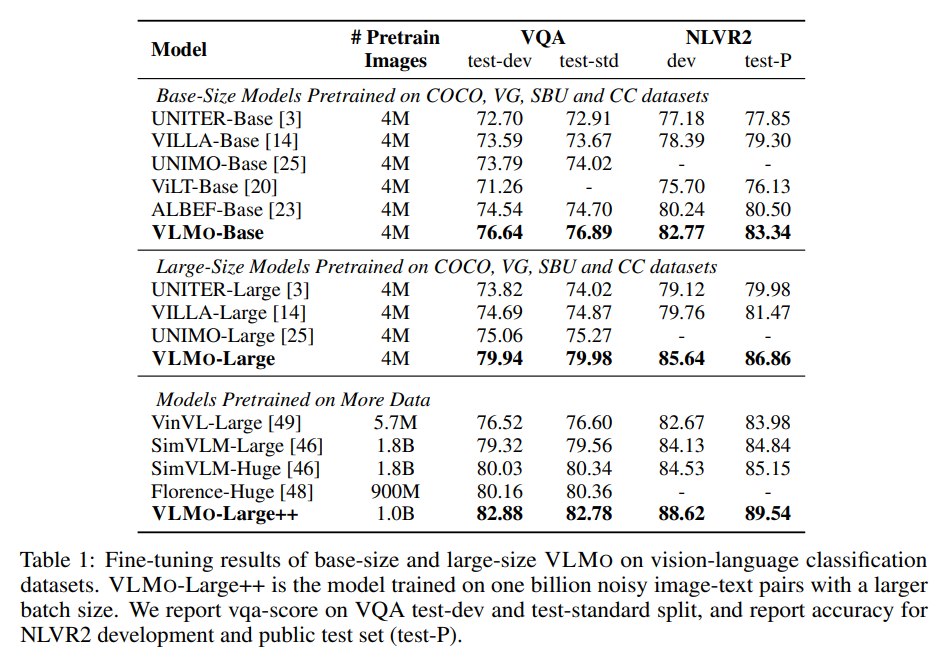
- 同样 4M 数据下,VLMO-Base 明显超过 ALBEF-Base。 这说明 MOME + stagewise pre-training 带来的增益不只是数据规模造成的。
- VLMO-Large 在 4M 数据下已经非常强。 它在 NLVR2 test-P 上达到 86.86,超过 SimVLM-Huge 的 85.15,尽管后者使用更大规模数据。
- VLMO-Large++ 受益于 1B noisy pairs。 大规模数据进一步提升 VQA 和 NLVR2,但这部分结果需要与资源成本一起理解。
VLMO还有很多的实验,比如分阶段预训练的效果很有效、模型很灵活(在单独的视觉数据集上也取得了很好的效果),在做图文检索的时候也取得了很好的效果和推理时间。
就不再讨论了。
五、结论
VLMO 的主要结论是:dual encoder 和 fusion encoder 不必由完全不同的模型承担。通过 MOME Transformer,一个模型可以同时支持 image-only、text-only 和 image-text 输入,在 retrieval efficiency 和 deep multimodal fusion 之间取得更好平衡。
相比 ALBEF,VLMO 更强调统一架构。ALBEF 的核心是 align before fuse,VLMO 的核心则是:同一模型既能作为 dual encoder,又能作为 fusion encoder。
论文结论中列出几个未来方向:
-
继续扩大 VLMO 预训练模型规模;
-
将 VLMO fine-tune 到 vision-language generation,例如 image captioning;
该团队的后续工作:VL-BeiT 和 BeiT v3
-
探索 vision-language pretraining 对单模态模型之间的相互促进;
-
扩展到 speech、video、structured knowledge 等更多模态。
这些方向说明 VLMO 的定位不仅是一个 VLP benchmark 模型,也试图成为更通用的 multimodal foundation model 雏形。

说些什么吧!