
零、写在前面
不同于之前读的ViLT从优化推理速度出发,ALBEF的出发点是,直接把text token 和 image token 扔给transformer做多模态融合的时候,图像特征和文本特征还没align(对齐),所以它提出在多模态融合之前我们就做图文align,然后还对web上的noise数据提出了一个解决策略,和MoCo那篇文章有点像,用一个momentum model来生成pseudo target,来达到自训练的结果。
一、标题
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
标题可以拆成两个层次:
- Align before Fuse:结构和训练顺序上的主张;
- Momentum Distillation:面对 noisy web data 时的学习目标设计。
二、摘要

摘要首先指出,vision-language representation learning 通常依赖大规模 image-text pairs,但 web 图文对天然带有噪声。已有 VLP 方法往往直接把图像和文本表示输入 multimodal encoder 做融合,而没有显式保证两种模态在融合前已经语义对齐。作者认为,这会增加跨模态学习难度:multimodal encoder 既要建立全局语义匹配,又要学习细粒度 token-level interaction。
ALBEF 的解决方案可以概括为三步:
- 用 unimodal encoders 分别编码图像和文本。 图像由 ViT-style image encoder 表示,文本由 BERT-style text encoder 表示。
- 用 Image-Text Contrastive Learning 对齐图文表示。 ITC 让匹配的 image-text pair 在共享表示空间中更接近,不匹配的 pair 更远。
- 在对齐后用 multimodal encoder 融合。 融合阶段再执行 Image-Text Matching(ITM)和 Masked Language Modeling(MLM)等跨模态目标。
摘要还强调 Momentum Distillation。
传统 contrastive learning 会把 batch 或 queue 中所有未配对样本当成 negative,但在 noisy web data 中,有些 “negative” 可能与图像语义相关。
例如一张狗在草地上的图像,原始 caption 是 “a dog playing outside”,另一个 caption “a brown dog on grass” 虽然不是标注正例,但语义上也合理。Momentum model 生成的 soft target 可以为这些潜在合理匹配分配非零概率,从而降低 hard label 的噪声。
摘要中的实验主张包括:
- ALBEF 在 image-text retrieval、VQA、NLVR2、SNLI-VE、weakly supervised visual grounding 等任务上取得强结果;
- 相比 VILLA,ALBEF 在 VQA 上提升约 2.37 个百分点,在 NLVR2 上提升约 3.84 个百分点;
- ALBEF 不依赖 bounding-box annotation 或 high-resolution object detector features,仍然能达到甚至超过 detector-based VLP 方法。
三、方法
3.1 模型总览
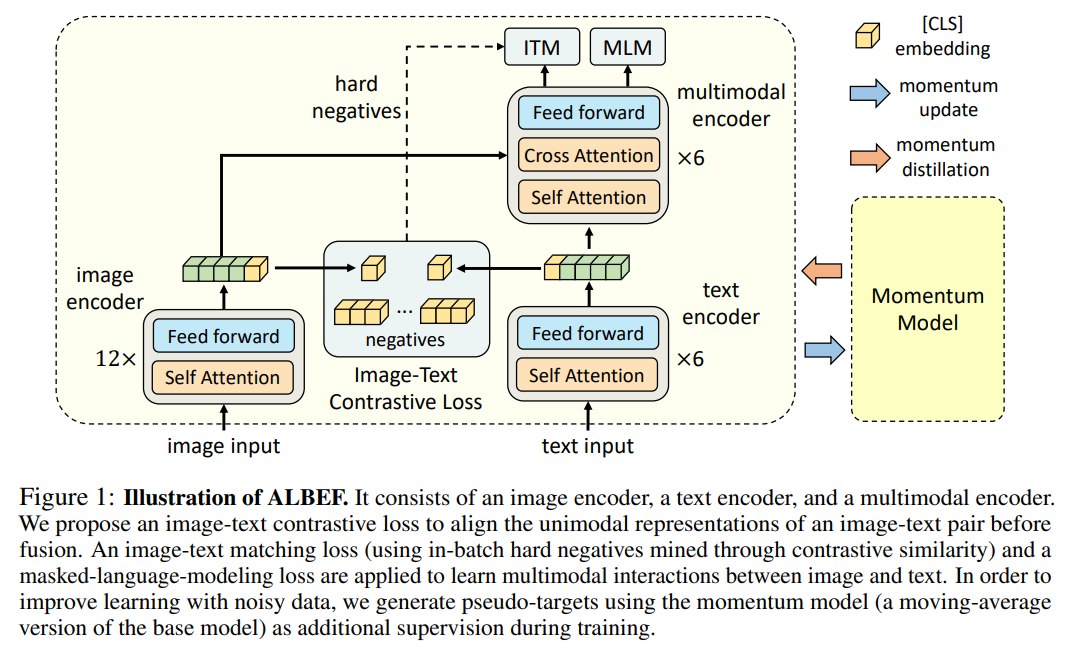
ALBEF 包含三个主要编码模块:
| 模块 | 结构 | 作用 |
|---|---|---|
| Image encoder | 12-layer ViT-B/16 | 将图像切成 patch 并编码为视觉表示 |
| Text encoder | 6-layer Transformer,初始化自 BERT-base 前 6 层 | 编码文本 token,得到单模态文本表示 |
| Multimodal encoder | 6-layer Transformer,初始化自 BERT-base 后 6 层 | 通过 cross-attention 融合图像和文本表示 |
上图左边的部分:
- 图像那边用了完整的12层encoder,然后文本那边只用了六层,这样可以让图像的encoder比文本那边大一些,这是之前VLP任务得出的经验。
- 然后在这个地方,计算了一个图文对比的loss。
- 然后文本那边剩下的六层去做图文多模态融合。计算了ITM 和 MLM loss
这个结构的关键点是:text encoder 和 multimodal encoder 是分开的。 前 6 层 BERT-like Transformer 负责单模态文本编码,后 6 层负责跨模态融合。这样模型可以在 fusion 之前先得到 text-only representation,用于 ITC 对齐;也可以在 fusion 之后得到 multimodal representation,用于 ITM、MLM 和下游任务。
然后右边采用了一个和MoCo有点像的 Momentum Model:
这个model的参数是根据左边的model 参数的动量更新得到的。和MoCo很想,这个动量参数设置的很高,论文中用的0.995.
产生的特征可以在左边作为negative sample,计算ITC,然后还可以在右边做momentum distillation。
小结一下就是,ALBEF 中每个模块的功能可以对应到不同目标:
- Image encoder + text encoder: 用于 ITC,学习全局 image-text alignment。
- Multimodal encoder: 用于 ITM 和 MLM,学习细粒度图文交互。
- Momentum model: 为 ITC 和 MLM 等目标提供 soft pseudo-targets。
3.2 Image-Text Contrastive Learning, ITC
ITC 是 ALBEF 中 “align before fuse” 的核心目标。模型分别取 image encoder 的 [CLS] 表示和 text encoder 的 [CLS] 表示,通过 projection 映射到同一个 256-dimensional normalized embedding space,然后计算 image-text similarity。
训练时,匹配的 image-text pair 被作为 positive pair,不匹配的 pair 被作为 negative pair。对每张图像,模型需要从一批文本中识别正确文本;对每段文本,模型也需要从一批图像中识别正确图像。因此 ITC 通常包含 image-to-text 和 text-to-image 两个方向的 contrastive loss。
ITC 的作用有三点:
- 全局对齐。 让 image representation 和 text representation 在 fusion 前已经具有语义可比性。
- 提升 retrieval 能力。 Retrieval 本质上依赖图文相似度排序,ITC 直接优化这一能力。
- 为 ITM 提供 hard negatives。 ITC similarity 可以识别与当前样本语义相近但不匹配的图文对,这些样本比随机 negative 更有训练价值。
在 ALBEF 中,如果去掉 ITC,模型会退化为更传统的 MLM + ITM fusion-based pretraining,实验也显示性能明显下降。
3.3 Image-Text Matching, ITM, 与 hard negative mining
**ITM 是一个二分类任务:给定一张图像和一段文本,判断它们是否匹配。**与 ITC 不同,ITM 在 multimodal encoder 之后执行,因此它可以利用 cross-attention 后的融合表示。
如果 negative pairs 完全随机采样,任务可能太容易。
例如一张狗的图片配上一段关于飞机的文字,模型很容易判断不匹配。
这类 easy negatives 对学习细粒度跨模态差异帮助有限。ALBEF 使用 ITC similarity 进行 hard negative mining:
- 先用 ITC similarity 找到与当前图像或文本语义相近的候选;
- 从这些高相似度但不匹配的 pair 中采样 hard negatives;
- 把 hard negatives 输入 multimodal encoder 做 ITM 训练。
这种设计非常自然:ITC 不仅是 alignment objective,也成为 ITM 的 negative sampler。这样 ITM 学到的不是粗糙的主题差异,而是更细的语义区分。例如图像和文本都涉及 “dog”,但颜色、动作、数量或场景不同,模型需要通过 fusion encoder 判断是否真正匹配。
3.4 Masked Language Modeling, MLM
MLM 是 VLP 中常见的 token-level 目标。ALBEF 随机 mask 文本 token,然后要求模型根据上下文和图像信息预测被 mask 的词。
与纯文本 BERT 的 MLM 不同,ALBEF 的 MLM 输入包含视觉信息。模型不能只利用语言上下文,还需要从图像中寻找证据。例如句子中 mask 掉颜色、物体类别、动作或空间关系时,正确预测往往依赖视觉内容。
MLM 在 ALBEF 中主要承担两类作用:
- 细粒度 grounding。 让文本 token 的预测依赖视觉 token,促进 word-level 和 region/patch-level 对齐。
- 补充 ITC 的全局对齐。 ITC 关注整图和整句匹配,MLM 关注局部语言单位与视觉上下文的关系。
因此,ALBEF 的目标分工可以理解为:ITC 学全局语义空间,ITM 学 pair-level matching,MLM 学 token-level grounding。
值得注意的是,这里的 ITM 和 MLM 是做了两次前向过程计算出来的。
因为 ITM 的计算是原始的 image 和 text,而 MLM 的计算用的是原始的 image 和 mask后的 text
多模态任务很多时候要计算多种loss,往往要做多次前向,从而导致多模态任务的训练时间比较长。
3.5 Momentum Distillation
Momentum Distillation 是 ALBEF 面对 noisy web data 的关键机制。
模型维护一个 momentum version of ALBEF,它的参数由在线模型参数的 **exponential moving average (EMA)**更新。训练时,momentum model 对当前样本生成 pseudo-targets,在线模型则学习这些 soft targets。
作者认为,从网络上拿到的这些 img text pair,以 one-hot 的形式,直接认为这个img必须和这个text是一对,对于 ITC 和 MLM 是不太友好的。因为有的负样本也包含了很多的信息,一味的惩罚这些负样本,会使得模型的学习非常困难。
所以我们希望计算loss的时候不是以one-hot的形式,而是以multi-hot的形式。具体来说,我们用 momentum model来产生pseudo targets(这里最终是以 softmax score的形式),然后希望模型的预测不仅跟 ground truth 的 one-hot label接近,也希望和momentum model产生的pseudo targets也尽可能地接近。

作者用一张图来表明,pseudo target也可以描述图片信息,从而在直觉上说明Momentum Distillation的合理性。
但是 ITM 没有做这种动量版本,因为 ITM 的二分类就是基于 ground-truth的,而且还做了 hard negative,这和pseudo target就有点矛盾了,所以就没有动量版本。
3.5.1 MoD for ITC
在标准 ITC 中,每张图像只把 paired text 当成正例,其余文本都是负例。MoD for ITC 使用 momentum model 计算 image-to-text 和 text-to-image 的相似度分布,并将其与 one-hot label 混合作为目标。
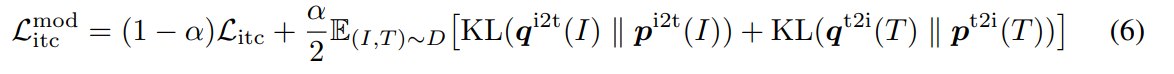
因为是multihot,所以这里用了 KL散度来计算。
3.5.2 MoD for MLM
在 MLM 中,被 mask 的 token 也可能存在多个合理预测。尤其是 caption 噪声较大或上下文不完整时,一个 hard token label 未必能表达全部语义可能性。Momentum model 输出的 token distribution 可以作为 soft target,使学生模型学习 teacher 对词汇分布的更平滑判断。
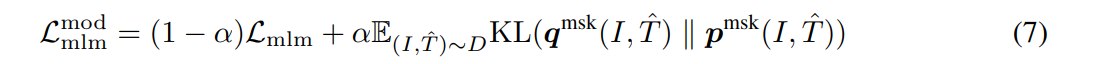
因为是multihot,所以这里用了 KL散度来计算。
3.5.3 Downstream Momentum Distillation
论文还将 Momentum Distillation 用于 downstream fine-tuning。实验中 “Full + downstream MoD” 相比只做 full pretraining 继续带来小幅提升,说明 distillation 不只对预训练有用,也可以在任务适配阶段稳定学习。
需要注意的是,Momentum Distillation 并不等于自动清洗数据。它只是用模型自身的平滑预测降低 hard label 噪声,对系统性 bias、隐私问题或错误网页关联并不能根本解决。
3.6 Mutual Information 视角
论文提供了一个 Mutual Information Maximization 的解释框架。这个部分的作用不是提出一个全新的理论模型,而是说明 ALBEF 的几个训练目标都可以被理解为在不同视图之间最大化 mutual information。
可以简化理解为:
- ITC: 图像和文本是同一语义内容的两个 view,contrastive learning 提高 image representation 和 text representation 之间的 mutual information。
- MLM: masked token 和 multimodal context 是两个 view,预测 masked token 可以提高局部语言单位与图文上下文之间的信息关联。
- Momentum Distillation: momentum model 生成的 pseudo-targets 可以被看作语义保持的 alternative views,让模型学习更丰富的样本关系。
四、实验
ALBEF 的实验重点不是只证明单个 benchmark 上的 SOTA,而是验证三个问题:
- Align before Fuse 是否有效?
- Momentum Distillation 是否能提升 noisy data 下的学习?
- Detector-free ViT-based VLP 是否能在多类任务上超过 detector-based 方法?
4.1 下游任务
- Image-Text Retrieval:图文检索
- Visual Entailment(视觉蕴含):**给定一张图像作为“前提”,再给一句文本作为“假设”,让模型判断这句话从图像来看是否一定成立。**能推出来,就是 entailment,推不出来前后矛盾就是contradictary,否则就是neutral(中立)。
- Visual Question Answering(VQA):
- 一种是闭集VQA:给定图片和answer,去找一个合适的answer,就变成分类问题了。
- 一种是开集VQA:给定图片,让模型生成一个答案,然后评测答案怎么样。
- Natural Language for Visual Reasoning(论文用的是 $NLVR^2$):让模型预测一段文本是否可以描述一对图片。
- Visual Grounding:让模型在一张图片中定位文本所描述的部分。
4.2 消融实验
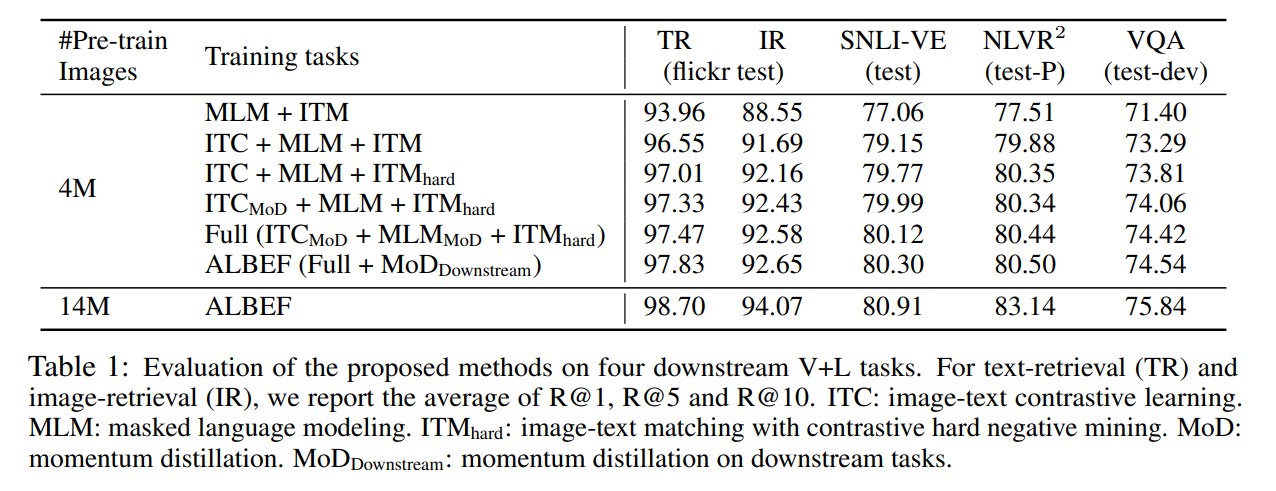
效 果 拔 群
本文所采用的那些ITC、MLM、ITM(以及ITM hard)的效果非常好。不过加上 Momentum Distillation的效果提升不太明显其实。
然后是在下游任务的表现。
首先是图文检索:
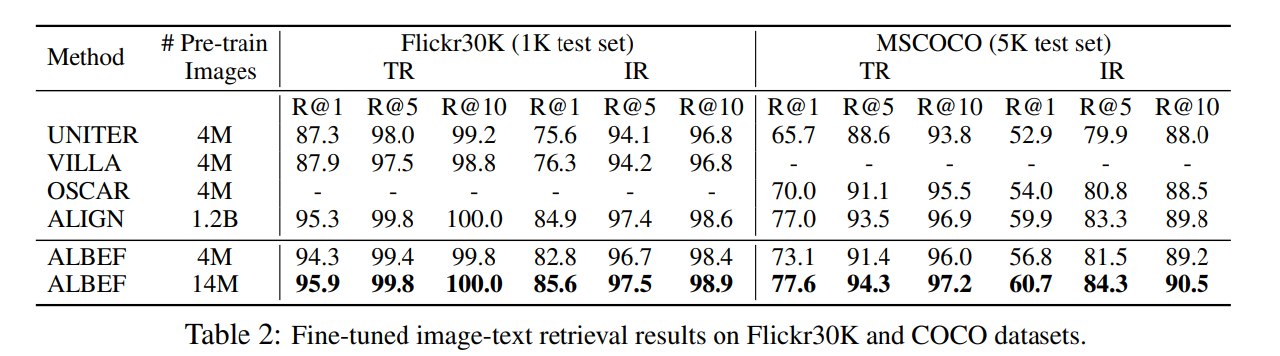
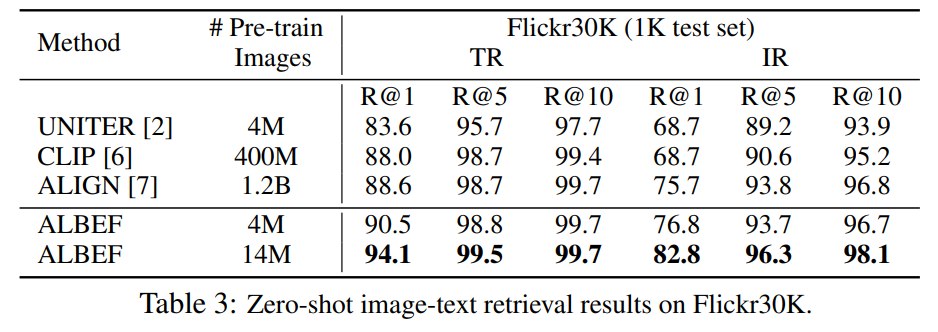
跪了(
然后是 三个任务放一块了:
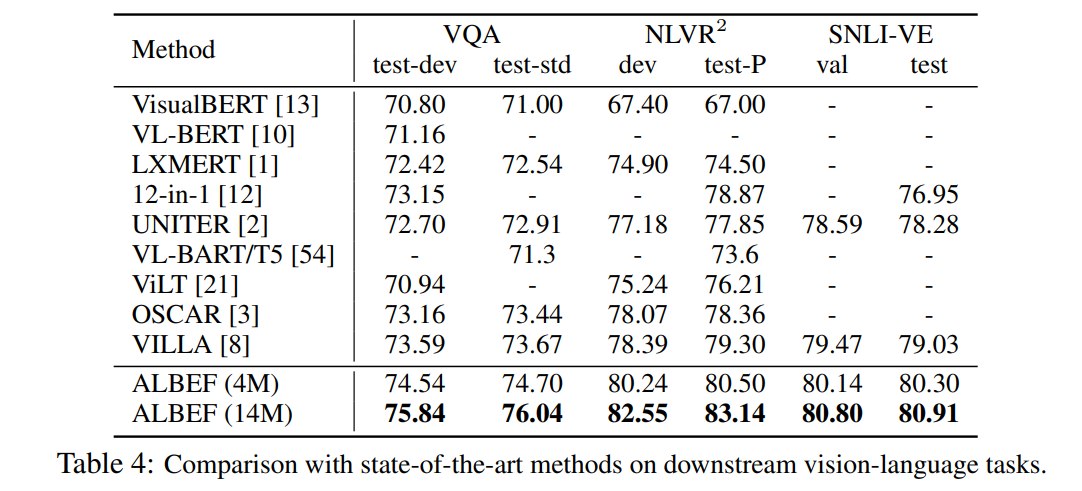
五、总结
ALBEF 的一句话总结是:
ALBEF 将 contrastive image-text alignment、multimodal fusion 和 momentum distillation 组合成一个统一的 VLP 框架,主张在融合图文 token 之前先对齐图文表示。
有三个核心贡献:
-
Representation order:Align before Fuse
- 先用 ITC 对齐 image encoder 和 text encoder 的全局表示;
- 再用 multimodal encoder 做 ITM、MLM 和下游推理;
- 减轻 fusion encoder 同时学习 alignment 和 reasoning 的负担。
-
Training objectives:ITC + ITM + MLM 的互补性
- ITC 负责全局图文匹配;
- ITM 负责融合后的 pair-level 判断;
- MLM 负责 token-level visual grounding;
- hard negative mining 让 ITM 学到更细的语义区分。
-
Noisy data handling:Momentum Distillation
- 使用 momentum teacher 生成 soft pseudo-targets;
- 缓解 one-hot contrastive targets 对 false negatives 的过度惩罚;
- 在预训练和下游 fine-tuning 中都带来稳定增益。
和之前读的 ViLT 的关系:
| 论文 | 核心问题 | 主要回答 |
|---|---|---|
| ViLT | VLP 是否必须依赖 heavy visual embedder / region supervision? | 不一定,可以用 patch projection + Transformer 简化视觉输入路径 |
| ALBEF | VLP 是否应该直接 fuse 未对齐的图文表示? | 不应该,应该先用 contrastive learning 对齐,再做 multimodal fusion |
ViLT 更关注视觉输入管线的轻量化,ALBEF 更关注跨模态表示学习的顺序和 noisy supervision。两者共同反映了 2021 年左右 VLP 的转向:从 detector-based region features 逐渐走向 ViT-based image encoding、contrastive alignment 和更统一的 multimodal pretraining。

说些什么吧!