
零、前言
BLIP 将ALBEF 和 VLMO进行结合,做了个多模态 encoder 和 decoder 的混合架构。
比较有趣的是本文提出的CapFilt,可以对noisy 的 web img-text 数据过滤,并且生成高质量的caption从而得到更好的数据集,这些数据集可以拿来继续训练BLIP或者其他的模型,引发了一系列工作。
一、标题
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
标题中的关键词 Bootstrapping、Unified分别点出了本文的两个贡献点:
- Bootstrapping:针对 web image-text pairs 的嘈杂数据集,BLIP认为让模型来参与数据改造,来产生更干净数据从而更好地训练模型。
- Unified:用一个预训练框架同时覆盖两类任务:
- VQA、NLVR、retrieval这类understanding task
- captioning 这类 generation task
作者团队来自ALBEF原班人马,自然也用了很多ALBEF的训练技巧。
二、引言
引言上来就介绍了本文的研究动机。
第一个动机从现有框架出发:
Vision-language tasks 可以粗略分成两类:
- Understanding tasks
- Generation tasks
已有 VLP 模型往往只擅长其中一类。Encoder-based 模型适合理解任务,但不天然支持自回归生成;encoder-decoder 或 decoder-based 模型适合生成任务,但未必在 retrieval 和 matching 上最高效。BLIP 的目标是构造一个可以同时服务 understanding 和 generation 的统一框架。
这个动机和VLMO是一样的,都是说A可以干嘛不能干嘛,B可以干嘛不能干嘛。
另一个动机从数据集出发:
与其只被动接受 noisy web text,不如让模型主动改造数据。
作者提出 Captioner 和 Filter Module:
- Captioner:为 web images 生成 synthetic captions
- Filter Module:删除不匹配的 original web captions 和 synthetic captions

BLIP 的引言还隐含地连接了前序模型:
- 与 ALBEF 一样,BLIP 使用 ITC 和 ITM 处理 alignment 与 matching;
- 与 VLMO 一样,BLIP 追求 unified architecture;
- 与传统 captioning 模型相比,BLIP 把 caption generation 纳入 VLP pretraining,而不是只作为下游任务。
三、Method
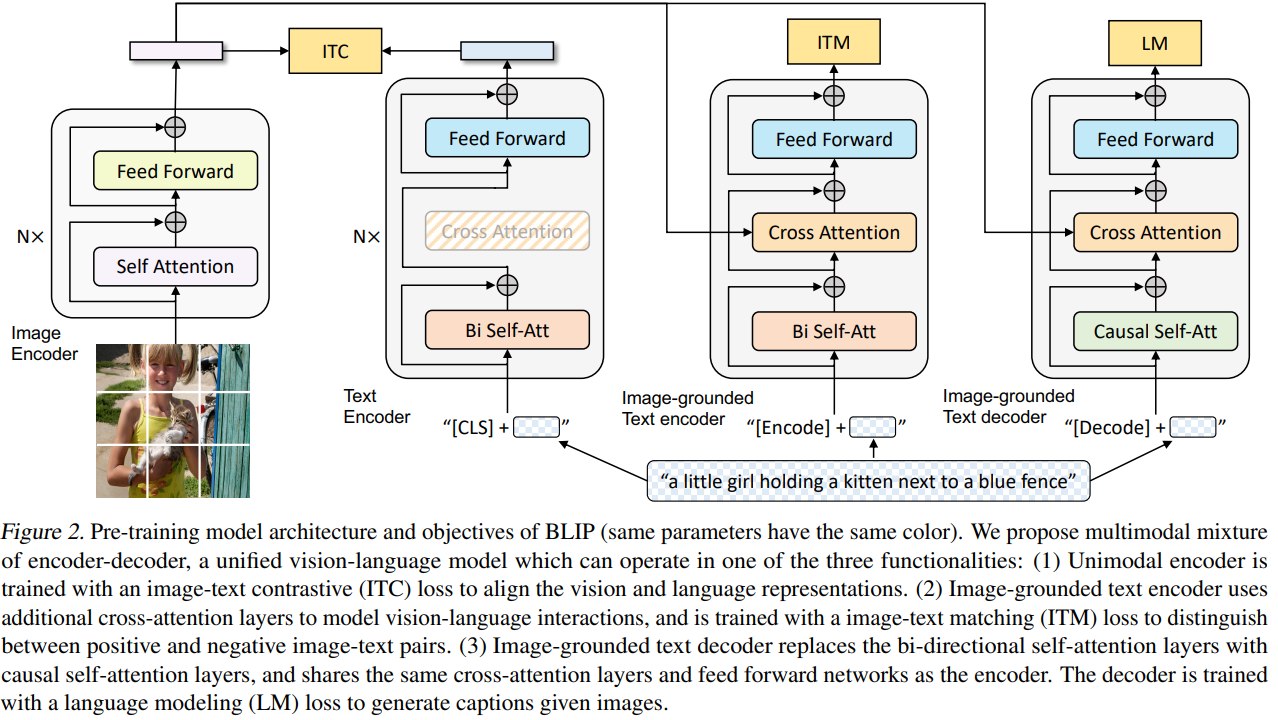
BLIP 的方法由两部分组成:MED architecture 和 CapFilt data bootstrapping。
3.1 MED:Multimodal Mixture of Encoder-Decoder
MED 是 BLIP 的核心架构。它让同一模型在三种模式下工作:
| 模式 | 功能 | 对应任务 / 目标 |
|---|---|---|
| Unimodal encoder | 分别编码 image 和 text | ITC、image-text retrieval |
| Image-grounded text encoder | 图文融合编码 | ITM、VQA、NLVR2、VisDial understanding |
| Image-grounded text decoder | 根据图像自回归生成文本 | LM、image captioning |
图像编码器使用 ViT。图像被切成 patches,输入 Transformer 后用 [CLS] 表示全局图像特征。文本侧使用 BERT-style Transformer,文本前加入 [CLS]。
Image-grounded text encoder 在 text transformer block 中插入 cross-attention,使文本 token 可以关注图像表示。Image-grounded text decoder 则把 bidirectional self-attention 替换为 causal self-attention,用于自回归生成 caption。
其实单看Unimodal encoder 和 Image-grounded text encoder,这就是一个 ALBEF。只不过结合了VLMO的共享参数的思想。
3.2 Encoder 与 Decoder 的参数共享
MED 的一个关键问题是 encoder 和 decoder 应该共享哪些参数。论文比较了多种共享策略,结果显示:除 self-attention 外共享参数效果最好。
原因是 encoder 和 decoder 对 self-attention 的需求冲突:
- encoder 需要 bidirectional self-attention,以便同时利用左右上下文;
- decoder 需要 causal self-attention,以保证生成时不能看见未来 token。
因此,如果强行共享 self-attention,会损害两种模式的能力。相反,embedding、cross-attention 和 FFN 等部分可以共享,从而提升参数效率并促进理解/生成之间的信息共享。
3.3 CapFilt:Captioning and Filtering
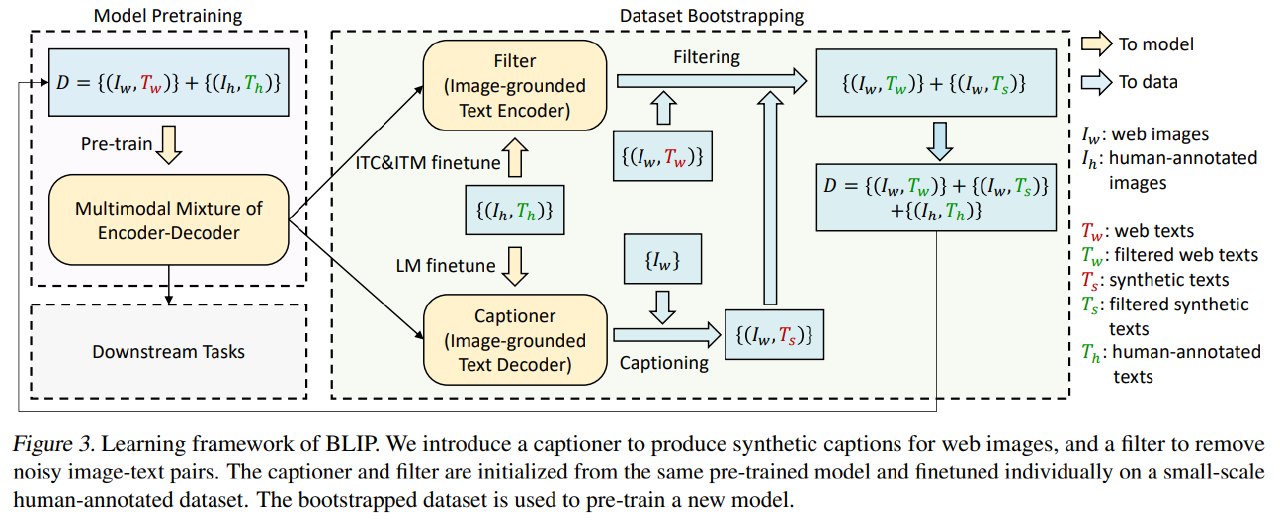
先用 noisy 的 web img-text 和 干净的数据集(如COCO)来对MED做预训练。
然后用encoder来作为filter,decoder来作为captioner。
Captioner(标注器)它以自回归(LM)方式工作:输入图像特征,逐词生成全新的描述句子。它会为每一张网络图像生成一个合成的干净 Caption。
**Filter(过滤器)**使用的是 BLIP 的ITC/ITM 能力。它接收一个图文对,输出该对是否匹配的置信度分数。 Filter 会对两种文本来源打分:
- 原始的网络 alt-text(原始 web 文本)
- Captioner 生成的合成 Caption
CapFilt 的训练流程包含四步:
- Initial pre-training。 先在原始 image-text data 上预训练 MED。
- Fine-tune captioner and filter。 在 COCO 上轻量微调 captioner 和 filter。
- Generate and filter captions。 Captioner 为 web images 生成 synthetic captions;filter 同时过滤 original web captions 和 synthetic captions。
- Re-pretrain new model。 将 filtered captions 与 human-annotated data 合并,用 bootstrapped dataset 重新预训练新模型。
四、Evaluation
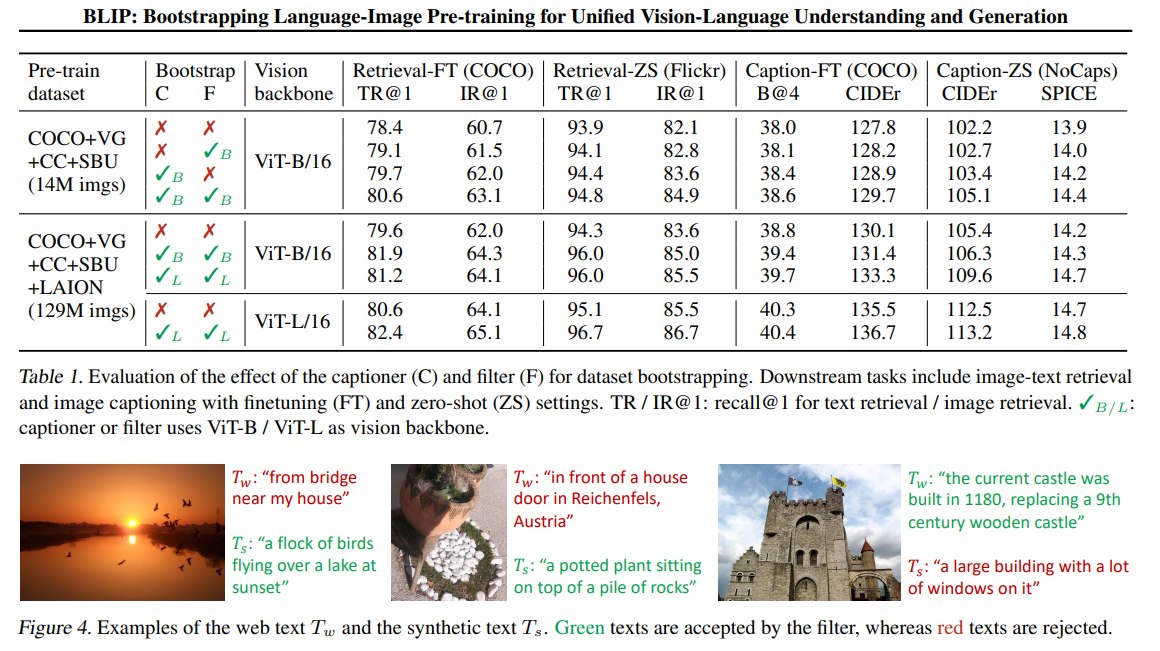
4.1 CapFilt 效果
4.2 BLIP 应用于下游任务

把图像扔给BLIP生成caption然后对模型做微调,训练出来效果拔群hh:

说些什么吧!