
零、写在前面
ViLT 的工作比较简单,就是在ViT的基础上,把图像patch得到的embedding和文本token拼接直接扔给transformer做多模态融合,效果还可以。然后还挖了一些坑,因为当时比如说MAE哪些它还没来得及用,不过这些坑很快就填上了。
这篇写的有点综述的意思,对以前的 vision-language 的工作做了很详细的总结。
一、标题
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
ViLT 就是一个Vision-and-Language Transformer,但不依赖 convolution,也不依赖 region supervision。
因为在 ViLT 之前,主流 vision-and-language pre-training(VLP)模型通常依赖两类视觉特征:
- Region feature:例如 ViLBERT、LXMERT、UNITER、OSCAR、VinVL 等,通常使用 Faster R-CNN 或类似 object detector,从 Visual Genome 等带 region/object 标注的数据中提取 RoI 特征。
- Grid feature:例如 Pixel-BERT,直接使用 CNN backbone 的 feature map,避免 region proposal,但仍然依赖深层 convolutional visual backbone。
ViLT 的标题强调它同时移除了这两种重型视觉嵌入路径:既不使用 object detection / region feature,也不使用深层 CNN visual embedder,而是把图像切成 patch 后做 linear projection,再和文本 token 一起送入 Transformer。
二、摘要

摘要首先指出,Vision-and-Language Pre-training 已经提升了多个视觉语言下游任务的表现,但现有方法严重依赖图像特征提取过程,而这些过程通常包含 region supervision 和 convolutional architecture。作者认为这种依赖存在两个问题:
- 效率问题: 在很多已有 VLP 模型中,单纯提取视觉特征的计算量和耗时远大于后续 multimodal interaction。也就是说,模型真正做跨模态交互之前,已经在视觉特征提取上付出了很大成本。
- 表达能力问题: 如果视觉特征由预训练 detector 或 CNN backbone 预先决定,那么整个 VLP 模型的视觉理解上限会受到 visual embedder 和预定义视觉词表的限制。
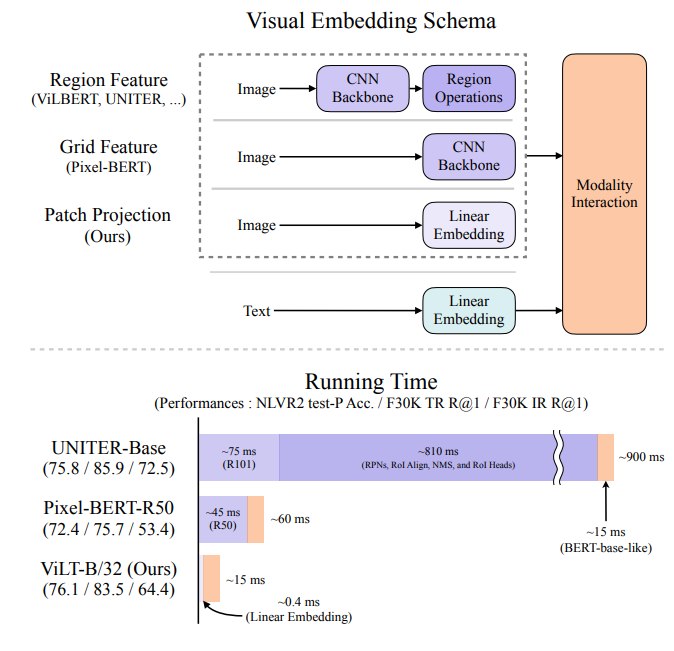
为了解决这个问题,论文提出 ViLT。ViLT 的核心思想是极简化视觉输入处理:图像像文本一样被浅层嵌入,不再经过 CNN 或 object detector。具体来说,图像被切成 patch,然后通过 linear projection 得到 patch embedding,再和 text embedding 拼接输入单流 Transformer。
摘要强调 ViLT 的两个主要结果:
- 速度比以前的 VLP 模型快数倍到数十倍;
- 在下游任务上仍然达到 competitive 或更好的表现。
competitive 这个表述还挺有趣的。
三、引言
引言从 pre-train-and-fine-tune 范式扩展到 vision-language domain 开始,指出 VLP 模型通常在 image-text pairs 上用 image-text matching(ITM)和 masked language modeling(MLM)等目标预训练,然后迁移到 VQA、NLVR2、retrieval 等下游任务。
**论文随后指出一个关键事实:为了把图像输入 VLP 模型,图像像素必须先被转成 dense feature。长期以来,深层 CNN 或 object detector 被视为视觉嵌入的默认选择。**大多数 VLP 模型使用基于 Visual Genome 预训练的 object detector,得到 region features;少数模型如 Pixel-BERT 使用 ResNet / ResNeXt 的 grid features。
作者认为,已有研究过于关注增强 visual embedder,却忽略了重型视觉嵌入器的成本。虽然训练时可以缓存 region features,减轻预训练阶段的负担,但真实推理时用户上传的新图像仍然必须经过慢速 detector 或 CNN backbone。因此,缓存不能解决部署时的速度问题。
在此基础上,论文提出把注意力转向更轻量、更快速的视觉输入嵌入。受 ViT 启发,作者认为图像 patch 的 simple linear projection 已经足以作为 Transformer 的输入表示。既然 Transformer 可以在 NLP 中处理 token,也可以在 ViT 中处理 patch,那么 VLP 中用于 modality interaction 的 Transformer 也有可能同时承担视觉特征处理和跨模态交互。
ViLT 因此采用一个非常简洁的设计:
- 图像被切成 patch;
- patch 通过 linear projection 得到 visual embedding;
- 文本通过 word embedding 得到 textual embedding;
- 图文 token 加上 position embedding 和 modality type embedding 后拼接;
- 单流 Transformer 统一建模 intra-modal 与 inter-modal interaction。
引言中作者总结了三点本文工作的三点贡献:
- 极简架构: ViLT 把视觉特征提取交给 Transformer,而不是单独使用深层 visual embedder,因此显著提升运行效率和参数效率。
- 首次证明可行性: 在不使用 region features 或深层 convolutional visual embedder 的情况下,ViLT 仍能在 vision-language tasks 上取得有竞争力的表现。
- 训练技巧发现: whole word masking 和 image augmentation 在 VLP 中有效,而此前这些技巧没有被充分用于 VLP training schemes。
四、背景知识
论文的背景部分主要完成两件事:第一,提出一个 vision-and-language models 的 taxonomy(分类体系);第二,梳理不同 visual embedding schema 的代价与局限。
4.1 Vision-and-Language Models 的四类范式
论文根据两个维度对视觉语言模型分类:
- 两个模态是否具有相近的 dedicated parameters / computation;
- 两个模态是否在深层网络中发生充分交互。
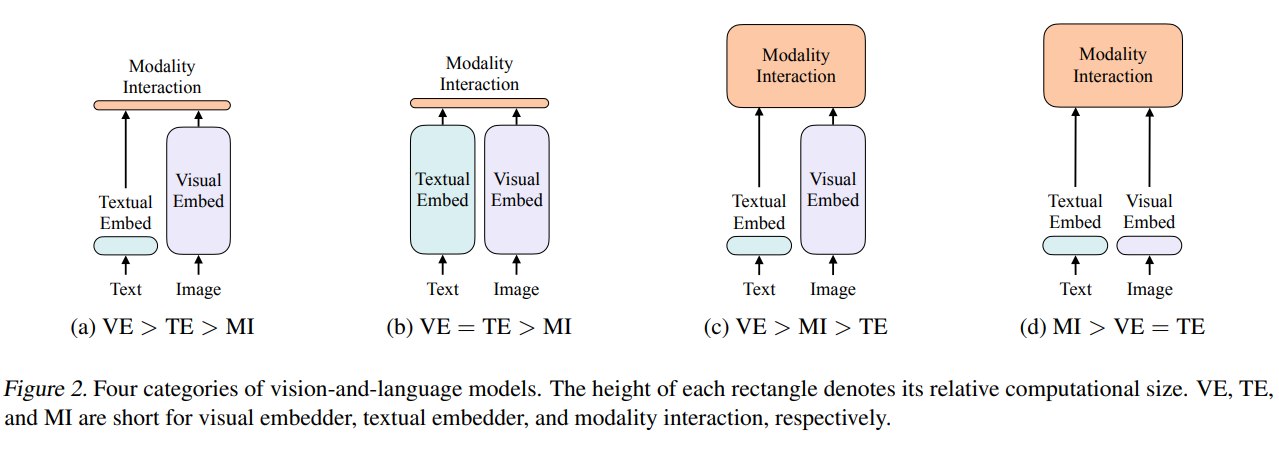
作者把 vision-language model 的方法总结为上面四种范式,ViLT为第四种。
由此形成四类模型:
4.1.1 VE > TE > MI
这里 VE 表示 visual embedder,TE 表示 textual embedder,MI 表示 modality interaction。这类模型中视觉编码器最重,文本编码器次之,跨模态交互较浅。
典型例子是 Visual Semantic Embedding(VSE)类模型,如 VSE++、SCAN。它们通常分别编码图像和文本,然后用 dot product 或 shallow attention 计算相似度。这类模型适合 retrieval,但对需要复杂跨模态推理的任务能力有限。
4.1.2 VE = TE > MI
这类模型中图像和文本都有较强的单模态 encoder,但跨模态交互仍然较浅。CLIP 是典型代表:image encoder 和 text encoder 都很强,但两者主要通过 pooled representation 的 dot product 交互。
论文指出,CLIP 虽然在 zero-shot image-text retrieval 上非常强,但简单把图文 pooled vector 融合并不能很好解决 NLVR2 这类复杂视觉语言推理任务。这说明强 unimodal representation 不等于强 multimodal reasoning。
NLVR2(Natural Language for Visual Reasoning for Real),即 真实图像上的自然语言视觉推理数据集。
它是一个经典的 视觉-语言推理任务,常用于评估多模态模型是否能同时理解:
- 图像内容;
- 自然语言描述;
- 多张图之间的关系;
- 逻辑组合与数量关系。
NLVR2 的输入通常是:一条自然语言句子 + 两张图片。模型要判断:这句话是否正确描述了这两张图片?
一个直观例子:
There are two dogs in the left image and one cat in the right image.两张图片分别是:
左图:两只狗 右图:一只猫那么标签是:True
对于文中指出的CLIP 不能很好地去做文图推理任务,个人理解是这样的:
CLIP的工作,是图文各自编码后,然后做了个对比学习的loss。这样模型可以学习到很强的图文匹配能力,但是模型失去了细粒度的图文融合(因为图文是各自编码的),也就丧失精细比较能力,模型可能大概知道图中有猫有狗,但猫在哪边,狗有几只?就比较难了。
或许后续可以读一些CLIP改进工作的文章。
4.1.3 VE > MI > TE
这是 ViLT 之前主流 VLP 模型所在类别。它们使用深层 visual embedder,例如 Faster R-CNN、ResNet、ResNeXt,然后用 Transformer 建模图文交互。
ViLBERT、LXMERT、VisualBERT、UNITER、OSCAR、VinVL、Pixel-BERT 等都可以放在这一类。它们的共同问题是 visual embedder 很重,甚至比后续 Transformer interaction 更耗时。
4.1.4 MI > VE = TE
ViLT 属于这一类。它让 visual embedding 和 textual embedding 都保持浅层、轻量,主要计算集中在 Transformer 的 modality interaction 中。也就是说,模型的计算预算从“视觉特征提取”转移到“跨模态交互”。
这也是 ViLT 的核心思想:VLP 的重点应该是 multimodal interaction,而不是不断堆更重的 unimodal visual embedder。
4.2 Modality Interaction Schema
论文沿用已有分类,把 VLP 的 interaction schema 分成两类:
- Single-stream approach:例如 VisualBERT、UNITER。图像 token 和文本 token 在输入层拼接,然后送入同一个 Transformer。
- Dual-stream approach:例如 ViLBERT、LXMERT。图像和文本先分别编码,再通过 cross-modal layers 交互。
ViLT 选择 single-stream approach,原因是 dual-stream 会引入额外参数,而 ViLT 的目标是极简和高效。
4.3 Visual Embedding Schema
论文重点讨论三类 visual embedding:
4.3.1 Region Feature
Region feature 来自 object detector,典型流程包括:
- CNN backbone 提取 feature map;
- Region Proposal Network 生成候选区域;
- NMS 筛选 RoI;
- RoI Align / RoI heads 生成 region feature;
- 再次 per-class NMS 得到最终少量 region features。
这种方式的优点是 object-centric,适合 VQA 等关注物体的任务;缺点是速度慢、依赖 region supervision、流程复杂,并且视觉词表受 detector 预训练类别限制。
4.3.2 Grid Feature
Grid feature 直接使用 CNN backbone 的 feature map,避免 region proposal 和 RoI operations。Pixel-BERT 是代表模型。
这种方式比 region feature 快,但仍然依赖深层 CNN backbone。论文认为,只去掉 detector 还不够,因为 CNN 本身仍然占据大量计算。
感觉和ViT 当时消融用的那个hybrid架构差不多
4.3.3 Patch Projection
**ViLT 采用 ViT 风格的 patch projection。**图像被分成固定大小 patch,每个 patch flatten 后通过 linear projection 映射到 hidden dimension。这种视觉嵌入和文本 word embedding 一样轻量。
ViLT-B/32 使用 32 x 32 patch projection,只有约 2.4M 参数。相比 ResNet-50、ResNet-101、ResNeXt-152 这类 backbone,参数量和计算量都显著减少。
五、Method
ViLT 的方法部分围绕三个核心问题展开:模型架构、预训练目标、训练增强策略。
5.1 模型总览
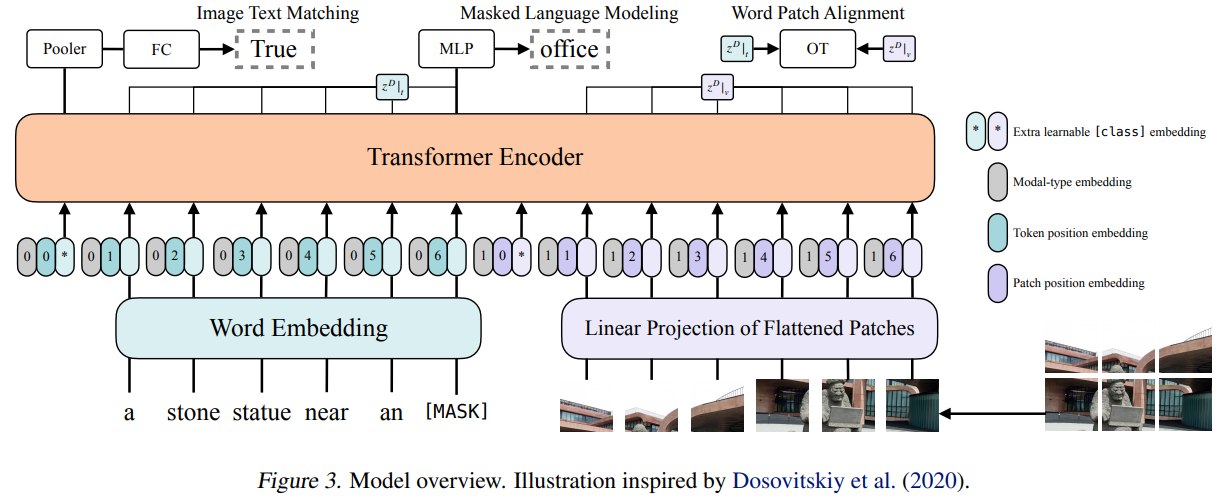
embedding进transformer之前的处理是,把文本embedding加上文本标识的embedding(就是图中的0),图像那边同理。
然后可以观察到还加了位置编码。
然后图文之间用了 [class] 的分隔开
ViLT 是一个 single-stream VLP 模型。它的输入由文本 token 和图像 patch token 拼接而成,然后送入同一个 Transformer Encoder。
- 文本输入经过 tokenizer 后,通过 word embedding 和 text position embedding 得到 textual embedding。
- 图像输入被切成 patch,每个 patch flatten 后通过 linear projection 得到 visual embedding,再加上 patch position embedding。
- 随后,文本和图像 embedding 分别加上 modality type embedding,并拼接成一个统一序列。
形式上,可以理解为:
- 文本:
word embedding + text position embedding + text type embedding - 图像:
patch projection + patch position embedding + image type embedding - 拼接:
[text tokens; image patch tokens] - Transformer:用多层 self-attention 同时建模图文内部关系和跨模态关系
- Pooler:取第一个位置的表示,经过 projection 和 tanh 得到整体 multimodal representation
ViLT 使用 ViT-B/32 初始化 Transformer 权重,而不是使用 BERT 初始化。这一点很重要,因为模型需要 Transformer 同时处理视觉 patch 和文本 token。论文提到,用 BERT 初始化 Transformer、再用 ViT 的 patch projection 初始化视觉部分的实验没有成功。
ViLT-B/32 的主要配置是:
- hidden size:768
- Transformer layers:12
- attention heads:12
- MLP size:3072
- patch size:32
- patch projection 初始化自 ViT-B/32
5.2 预训练目标
ViLT 主要使用两个 VLP 常见目标:ITM 和 MLM,并额外引入 word-patch alignment。
5.2.1 Image Text Matching(ITM)
ITM 是二分类任务:判断图像和文本是否匹配。训练时以 0.5 的概率随机替换 aligned image,构造 negative pair。模型使用 pooled output 通过 linear head 预测 true / false。
ITM 的作用是让模型学习全局图文匹配关系,是 VLP 中最常用的预训练目标之一。
5.2.2 Word Patch Alignment(WPA)
论文受 UNITER 的 word-region alignment 启发,设计了 word-patch alignment。不同之处在于 ViLT 没有 region feature,所以只能在 word token 和 image patch token 之间建立 alignment。
具体做法是:从最终 Transformer 输出中取 textual subset 和 visual subset,使用 optimal transport / IPOT 方法计算两者之间的 alignment score,并把近似 Wasserstein distance 乘以 0.1 加到 ITM loss 中。
WPA 的作用是帮助模型建立细粒度 word-patch 对齐。论文还通过可视化展示,例如词 “flowers”“wall”“cottages”“cloudy” 能与对应图像 patch 形成较合理的 alignment heatmap。

5.2.3 Masked Language Modeling(MLM)
MLM 和 BERT 类似:随机 mask 15% 的文本 token,并根据最终 contextualized representation 预测原 token。
ViLT 的 MLM 特别强调跨模态信息。如果 mask 的词不能仅靠上下文猜出,模型就需要利用图像 patch 信息来预测。这是 VLP 中常见的语言侧预训练目标。
不过图像那边没做这个,因为当时 MAE 的工作还没出来(
5.3 Whole Word Masking
论文认为 whole word masking 对 VLP 特别重要。原因是 WordPiece tokenizer 会把一个词拆成多个 subword。例如 “giraffe” 可能被拆成 gi, ##raf, ##fe。如果只 mask 中间 subword,模型可能只靠周围 subword 猜出答案,而不需要看图像。
Whole word masking 会 mask 组成一个完整词的所有 subword,迫使模型更多依赖视觉信息或跨模态上下文。
因为文本信息缺失了,那么模型就不得不从视觉那边获取更多信息。
实验表明,whole word masking 对下游任务有稳定增益。
5.4 Image Augmentation
由于 ViLT 不缓存 region features,而是直接处理图像 patch,因此它可以在 fine-tuning 时使用 image augmentation。论文采用 RandAugment,但去掉了两个策略:
-
color inversion:因为文本和视觉任务中颜色信息可能很重要;
颜色变了,可能就跟文本语义对不上了。
-
cutout:因为小物体可能被直接遮掉。
实验表明,RandAugment 在 fine-tuning 中能提升性能。这一点对 ViLT 很重要,因为 region-feature-based VLP 模型由于缓存特征,很难自然使用图像增强。
5.5 方法的整体理解
ViLT 的技术贡献不在于提出复杂的新模块,而在于重新分配 VLP 模型的计算结构。它把视觉前端从 Faster R-CNN / ResNet 简化成 linear patch projection,让 Transformer 成为主要计算单元。
因此,ViLT 可以看作是下面这条路线的早期代表:
raw image patches -> lightweight visual embedding -> unified Transformer -> multimodal interaction
这条路线与后来的多模态大模型有一定联系。虽然后续 LVLM 往往仍会使用强视觉 encoder,但 ViLT 提前提出了一个重要问题:视觉语言模型的瓶颈是否一定在视觉特征提取器?是否可以让统一 Transformer 直接承担更多跨模态建模?
六、实验
实验部分主要验证两件事:第一,ViLT 是否在速度和复杂度上显著优于传统 VLP;第二,在去掉 heavy visual embedder 后,ViLT 是否仍能保持有竞争力的下游性能。
6.1 预训练数据与设置
ViLT 使用四个数据集进行预训练:
| Dataset | Images | Captions | 说明 |
|---|---|---|---|
| MSCOCO | 113K | 567K | 常用图文数据集 |
| Visual Genome | 108K | 5.41M | dense captions / region descriptions 丰富 |
| GCC | 3.01M | 3.01M | Conceptual Captions,作者重新收集仍可访问图片 |
| SBU | 867K | 867K | SBU Captions,作者重新收集仍可访问图片 |
训练使用 AdamW,base learning rate 为 1e-4,weight decay 为 1e-2,学习率 warmup 10%,之后线性衰减。预训练在 64 张 NVIDIA V100 上进行,batch size 为 4096,训练 100K 或 200K steps。
图像处理方面,较短边 resize 到 384,较长边限制在 640 以内,保持宽高比。ViLT-B/32 在 384 x 640 图像上最多产生 12 x 20 = 240 个 patch,预训练时最多采样 200 个 patch。
6.2 下游任务
论文评估两类任务:
-
Classification tasks
- VQAv2
- NLVR2
-
Retrieval tasks
- Flickr30K text retrieval / image retrieval
- MSCOCO text retrieval / image retrieval
- 包括 zero-shot retrieval 和 fine-tuned retrieval
6.3 Classification Results
在 VQAv2 和 NLVR2 上,ViLT 的结果显示出明显的效率优势和一定的性能折中。
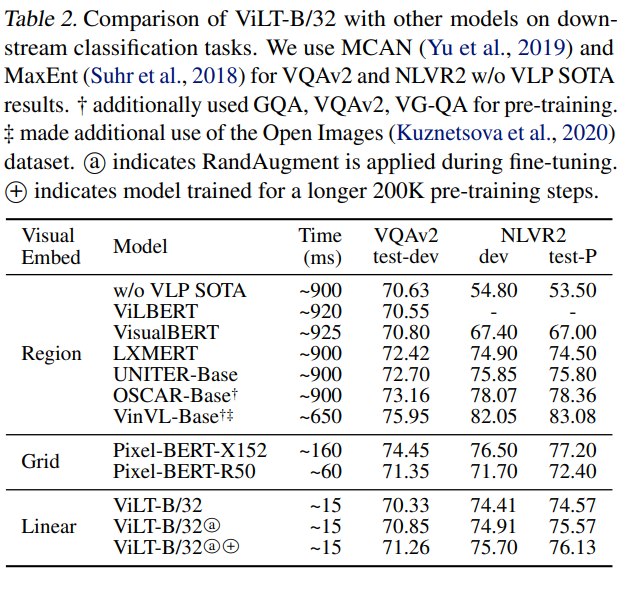
- ViLT-B/32 推理耗时约
15 ms,远快于 region-feature models 的约900 ms,也快于 Pixel-BERT-R50 的约60 ms。 - ViLT-B/32 在 NLVR2 上表现有竞争力:test-P 约 74.57,使用 RandAugment 和更长训练后可到 76.13。
- 在 VQAv2 上,ViLT-B/32 约 70.33,增强后约 71.26,低于 LXMERT、UNITER、OSCAR、VinVL 等 region-feature models。
这说明 ViLT 的极简视觉嵌入在某些跨模态推理任务上可行,但在 VQA 这类强 object-centric 任务上,region feature 仍然有优势。作者也承认,detector 生成的 detached object representation 可能使 VQA 更容易训练,因为 VQA 问题常常直接询问物体。
6.4 Retrieval Results
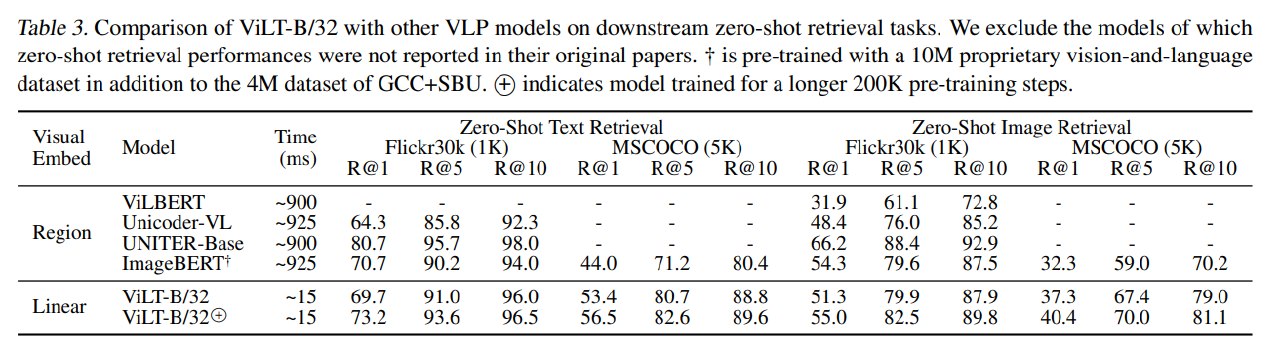
在 retrieval 任务上,ViLT 表现相对更强。
Zero-shot retrieval 中,ViLT-B/32 在 Flickr30K 和 MSCOCO 上通常优于 ImageBERT,尽管 ImageBERT 使用了更大的预训练数据。训练更长的 ViLT-B/32+ 进一步提升 zero-shot retrieval 表现。
Fine-tuned retrieval 中,ViLT-B/32 相比速度第二快的 Pixel-BERT-R50 有明显优势。例如在 Flickr30K text retrieval / image retrieval 上,ViLT 的 R@1 明显高于 Pixel-BERT-R50,同时速度约为后者的四分之一。
这说明 ViLT 的 patch-level unified Transformer 对图文匹配和检索任务尤其适合,因为 retrieval 更强调全局图文语义对齐,不一定像 VQA 那样依赖显式 object detector。
6.5 Ablation Study
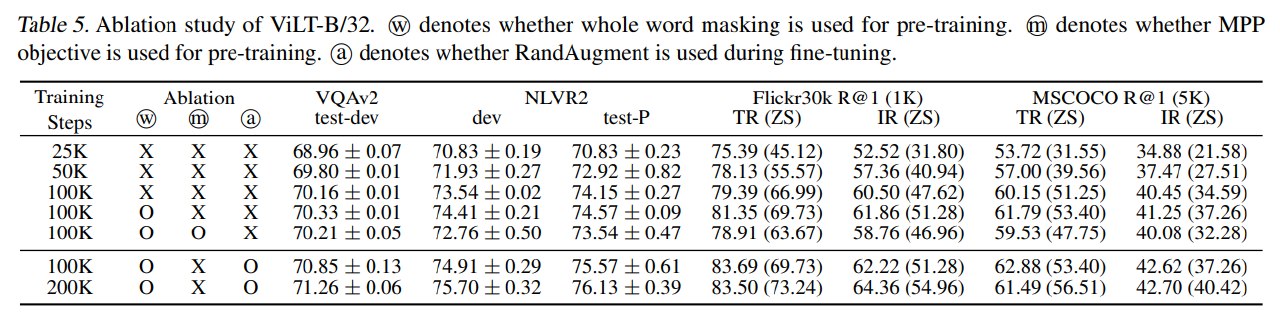
消融实验主要考察训练步数、whole word masking、masked patch prediction 和 RandAugment。
关键结论:
- 训练更久有效。 从 25K 到 50K 到 100K,VQAv2、NLVR2 和 retrieval 指标基本持续提升。200K 进一步提升 VQAv2、NLVR2 和 zero-shot retrieval,但 fine-tuned text retrieval 后续可能下降。
- Whole word masking 有效。 在 100K steps 下加入 whole word masking 后,NLVR2 和 retrieval 有明显提升。
- Masked patch prediction 无效。 作者尝试让模型预测 masked patch 的 mean RGB value,但这个 MPP 目标没有带来增益,反而降低多个指标。
- RandAugment 有效。 Fine-tuning 时加入 RandAugment 能提升 VQAv2、NLVR2 和 retrieval。
这个消融很有价值,因为它说明 ViLT 的性能不是只靠结构简化,还依赖适配 patch-based VLP 的训练技巧。尤其是 MPP 失败说明:把 BERT-style masking 直接迁移到视觉 patch 上并不简单,视觉侧 masked modeling 需要更合适的目标设计。
6.6 Complexity Analysis
复杂度分析是论文最有说服力的部分之一。
Table 6 对比了参数量、FLOPs 和推理延迟:
- ViLT-B/32 参数量约 87.4M;
- FLOPs 约 55.9G;
- 推理延迟约 15ms;
- Region-feature models 通常延迟约 650-925ms;
- Pixel-BERT-R50 延迟约 60ms,Pixel-BERT-X152 约 160ms。
论文还指出,per-class NMS 这类操作不一定完全体现在 FLOPs 和参数量中,但会显著增加实际 latency。这一点很重要,因为它提醒读者不能只看 FLOPs,还要看真实系统中的非张量操作开销。
ViLT 的主要优势来自:
- 不使用 Faster R-CNN;
- 不使用 ResNet / ResNeXt visual backbone;
- 不使用 region proposal、RoI Align、RoI heads、per-class NMS;
- visual embedding 只是 linear projection;
- 主要计算集中在 BERT-base-like Transformer 中。
6.7 Visualization
论文用 WPA 的 transportation plan 做可视化,展示词和图像 patch 的 alignment。例如 “flowers”“wall”“cottages”“cloudy”等词能与对应图像区域形成较清晰的热力图。
这个可视化的作用是证明:即使没有 region feature,ViLT 也能在 patch 层面形成一定的词-图像区域对应关系。
不过,这种可视化更多是 qualitative evidence,不能完全证明模型具有强 grounding 能力。它更适合作为辅助解释,而不是核心实验结论。
七、 结论和未来工作
论文结论重申 ViLT 是一个 minimal VLP architecture。它在不使用 Faster R-CNN、ResNet 等 convolutional visual embedding networks 的情况下,仍然能在多个 vision-language tasks 上与强基线竞争。
作者希望未来 VLP 研究把更多注意力放到 Transformer 内部的 modality interaction,而不是陷入不断增强 unimodal visual embedder 的军备竞赛。
论文也明确指出,ViLT-B/32 更像是一个 proof of concept:它证明了没有 convolution 和 region supervision 的高效 VLP 是可行的,但并不意味着当前版本已经达到极限。
未来工作主要包括三个方向:
7.1 Scalability
作者认为,类似 BERT 和 ViT,Transformer 模型性能通常会随模型规模和数据规模提升。因此未来可以训练更大的 ViLT-L / ViLT-H。
不过,作者也指出 aligned vision-and-language datasets 仍然稀缺,因此扩大 ViLT 家族需要更多高质量图文数据。
7.2 更好的视觉侧 masked modeling
论文尝试的 masked patch prediction 没有效果,但作者并不认为视觉侧 masked modeling 不重要。相反,他们认为 MRM 的成功可能来自让视觉信息保留到 Transformer 最后层。
问题在于:对于 trainable visual embedder,固定视觉词表或一次性 clustering 不一定合适。作者建议可以参考视觉无监督学习中的 alternating clustering 或 simultaneous clustering,设计更合适的视觉 masked objective。
7.3 更合适的 augmentation strategy
论文使用 RandAugment 并观察到收益,但作者认为仍有空间探索更适合 VLP 的 augmentation。例如视觉对比学习中 gaussian blur 有明显效果,但 RandAugment 中没有使用。未来可以研究同时适配文本和图像输入的增强策略。
有趣的是,future work 挖的坑在ViLT 之后被迅速地填上了
八、总结
ViLT 的核心可以概括为一句话:
ViLT 证明了在 vision-language pre-training 中,可以去掉昂贵的 CNN / detector visual embedding pipeline,只用 patch projection + single-stream Transformer 也能获得高效且有竞争力的多模态表示。
从技术上看,它的关键设计包括:
- Patch projection visual embedding:图像 patch 通过 linear projection 得到视觉 token。
- Single-stream Transformer:文本 token 和图像 patch token 拼接后统一建模。
- ViT initialization:Transformer 从 ViT-B/32 初始化,而不是 BERT。
- ITM + MLM + WPA:使用常见 VLP 目标,并通过 word-patch alignment 增强细粒度对齐。
- Whole word masking:避免模型只靠 subword 上下文完成 MLM,促使其使用视觉信息。
- RandAugment fine-tuning:利用不缓存视觉特征的优势引入图像增强。
- 端到端效率优势:显著降低 visual embedding 的 latency,使主要计算集中在 Transformer interaction 中。
对后续阅读 Qwen-VL、LLaVA、MiniGPT 等模型时,ViLT 可以作为一个重要参照:
- LLaVA / MiniGPT / Qwen-VL 更强调如何把视觉表示接入 LLM;
- ViLT 更强调是否可以取消重型视觉前端,让统一 Transformer 直接承担图文建模;
- 后续模型虽然通常回到强视觉 encoder,但它们仍然继承了 ViLT 所代表的思想:图像可以被 token 化,视觉 token 可以和文本 token 在 Transformer 中统一处理。

说些什么吧!