
零、写在前面
Qwen-VL官方源码:Qwen/Qwen-VL
论文基本没什么图,感觉Method也没有介绍的很细,对比源码看看会好一些。
一、标题
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL:一个多功能的视觉语言模型,用于理解、定位、文本阅读及其他任务
标题直接给出模型名、能力范围和任务定位,没有把 Qwen-VL 描述成单一的 image captioning 或 VQA 模型,而是强调 versatile vision-language model,并用 “Understanding, Localization, Text Reading, and Beyond” 展开能力边界。这说明论文的核心目标是把 Qwen 系列语言模型扩展为通用视觉语言基础模型,而不是只解决一个 benchmark。
二、摘要

摘要首先指出本文提出 Qwen-VL series,即一组大规模 vision-language models,目标是同时感知和理解文本与图像。模型从 Qwen-LM 出发,通过四个关键设计获得视觉能力:
- visual receptor:视觉接收器,包括视觉编码器与视觉语言适配器;
- input-output interface:统一图像、文本、bounding box 等输入输出格式;
- 3-stage training pipeline:三阶段训练流程;
- multilingual multimodal cleaned corpus:多语言、多模态清洗语料。
强调 Qwen-VL 不只处理常规图像描述和视觉问答,还通过对齐 image-caption-box tuples 实现 grounding 和 text-reading 能力。
最终模型包括 Qwen-VL 与 Qwen-VL-Chat:前者是预训练/多任务训练后的基础视觉语言模型,后者是 instruction-tuned chatbot。论文声称在 image captioning、question answering、visual grounding 等 benchmark 上,相比同规模 generalist models 取得新纪录,并且 Qwen-VL-Chat 在真实对话 benchmark 上优于已有 vision-language chatbots。
摘要的信息密度还是比较高的,贡献点排列地很清楚,尤其是把 architecture、interface、training pipeline、data corpus 四个组成部分并列列出,方便读者快速建立论文结构。
三、引言
引言从 LLM 的成功写起:大语言模型在文本生成、理解和 instruction following 中表现突出,但原生 LLM 只能处理纯文本,无法直接理解图像、语音、视频等常见模态。这构成了发展 LVLM 的动机。
随后论文指出,已有 LVLM 虽然展示了潜力,但开放模型仍面临两个关键问题:
- 训练和优化不足:开源 LVLM 与 proprietary models(GPT-4等) 仍有明显差距,限制了开源社区的进一步探索和应用。
- 细粒度视觉理解不足:现实场景复杂,模型如果只能粗粒度看图,就难以完成定位、文字读取、细节识别等任务。已有少数模型如 Kosmos-2、Shikra 关注 grounding,但多数开源 LVLM 仍缺少 fine-grained perception。
在这个背景下,论文提出 Qwen-VL 系列。Qwen-VL 基于 Qwen-7B,通过 language-aligned visual encoder 和 position-aware adapter 为 LLM 引入视觉能力。论文强调整体 architecture 和 input-output interface 保持简洁,同时依赖三阶段训练流程和大规模图文语料获得多任务能力。
引言明确列出 Qwen-VL 系列的四个特征:
- Leading performance:在同规模 generalist models 中取得强结果,覆盖 captioning、VQA、grounding 和 dialogue benchmarks。
- Multi-lingual:训练数据包含英文和中文图文语料,因此天然支持中英文和多语言指令。
- Multi-image:训练阶段允许 interleaved image-text inputs,使 Qwen-VL-Chat 能处理多图比较、理解和分析。
- Fine-grained visual understanding:更高输入分辨率和细粒度训练语料增强 grounding、text-reading、text-oriented QA 和细粒度对话能力。
四、结论

论文结论部分比较简短,主要重申 Qwen-VL 是一组大规模多语言 vision-language models,目标是促进多模态研究。作者总结模型在多个 benchmark 上超过同类模型,并支持多语言对话、多图 interleaved conversation、中文 grounding 和细粒度识别。
未来工作提出三个方向:
- 引入更多模态:例如 speech 和 video;
- 扩大模型规模、训练数据和输入分辨率:增强模型处理复杂多模态关系的能力;
- 扩展多模态生成能力:例如生成高保真图像和流畅语音。
总结就是:Qwen-VL 当前主要是视觉理解与视觉语言对话模型,下一步希望走向更多模态、更大规模和生成式多模态能力。
五、相关工作
相关工作先回顾 vision-language learning 的传统脉络,包括 VLBERT、UNITER、OSCAR、VinVL、ViLT、ALBEF、BLIP 等;随后讨论 multi-task generalist models,如 CoCa、OFA、Unified-IO。论文指出这些方法尝试统一图文理解与生成任务,或者把多种任务转成 sequence-to-sequence 格式。
第二类相关工作是 vision-language representation models,如 CLIP、ALIGN、Florence、Chinese-CLIP。CLIP 通过大规模对比学习对齐图像和语言语义空间,具有很强的迁移能力。BEIT-3、ImageBind、ONE-PEACE 等进一步把统一表示扩展到更多任务或更多模态。
第三类是基于 LLM 的 LVLM。论文列举 Flamingo、PaLI、BLIP-2、InstructBLIP、Kosmos、Kosmos-2、MiniGPT-4、LLaVA、mPLUG-Owl、mPLUG-DocOwl、Shikra、Otter、VideoLLaMA、Emu 等。这里的重点是说明 LVLM 已经从“图文表示学习”走向“以 LLM 为核心的多模态通用助手”。
论文特别强调几个与 Qwen-VL 直接相关的方向:
- BLIP-2:用 Q-Former 对齐 frozen vision foundation model 和 LLM;
- LLaVA / MiniGPT-4:通过 visual instruction tuning 增强 LVLM 的 instruction following;
- mPLUG-DocOwl:通过 digital documents data 引入文档理解能力;
- Kosmos-2 / Shikra / BuboGPT:通过 grounding 使模型具备区域描述和定位能力。
Qwen-VL 的定位是把 image captioning、VQA、OCR、document understanding、visual grounding 等能力整合进一个模型,并在多个任务上取得较强表现。
六、Method
Qwen-VL 以 Qwen-7B为语言基座,然后加入了视觉编码器和语言适配器,把图像特征压缩成固定长度序列后,和文本token拼接送入 LLM。
6.1 模型架构
Qwen-VL 包含三个主要组件:
-
Large Language Model
使用 Qwen-7B 作为基础语言模型。论文中的参数表显示,LLM 部分约 7.7B,总模型约 9.6B。 -
Visual Encoder
视觉编码器采用 ViT 架构,初始化自 OpenCLIP 的 ViT-bigG。输入图像被 resize 到指定分辨率,并以 stride 14 做卷积切分成 patch,输出图像特征序列。 -
Position-aware Vision-Language Adapter
为了避免直接把过长视觉特征序列输入 LLM,Qwen-VL 使用一个单层 cross-attention adapter。它用一组可训练 query 向量从视觉编码器输出中抽取信息,把视觉序列压缩到固定长度 256。为了减少压缩过程中的空间信息损失,adapter 在 query-key 交互中加入 2D absolute positional encodings。
这个 adapter 是方法部分的关键。它与 BLIP-2 的 Q-Former 在动机上相似,都是为了在视觉编码器和 LLM 之间建立信息瓶颈和跨模态对齐;但 Qwen-VL 特别强调 position-aware,以服务 grounding 和 text-reading 等细粒度任务。
6.2 输入输出接口
Qwen-VL 的接口设计非常重要,因为它决定了模型如何统一图像、文本和定位信息。
- 图像输入:图像经 visual encoder 和 adapter 后变成固定长度视觉特征序列,并用
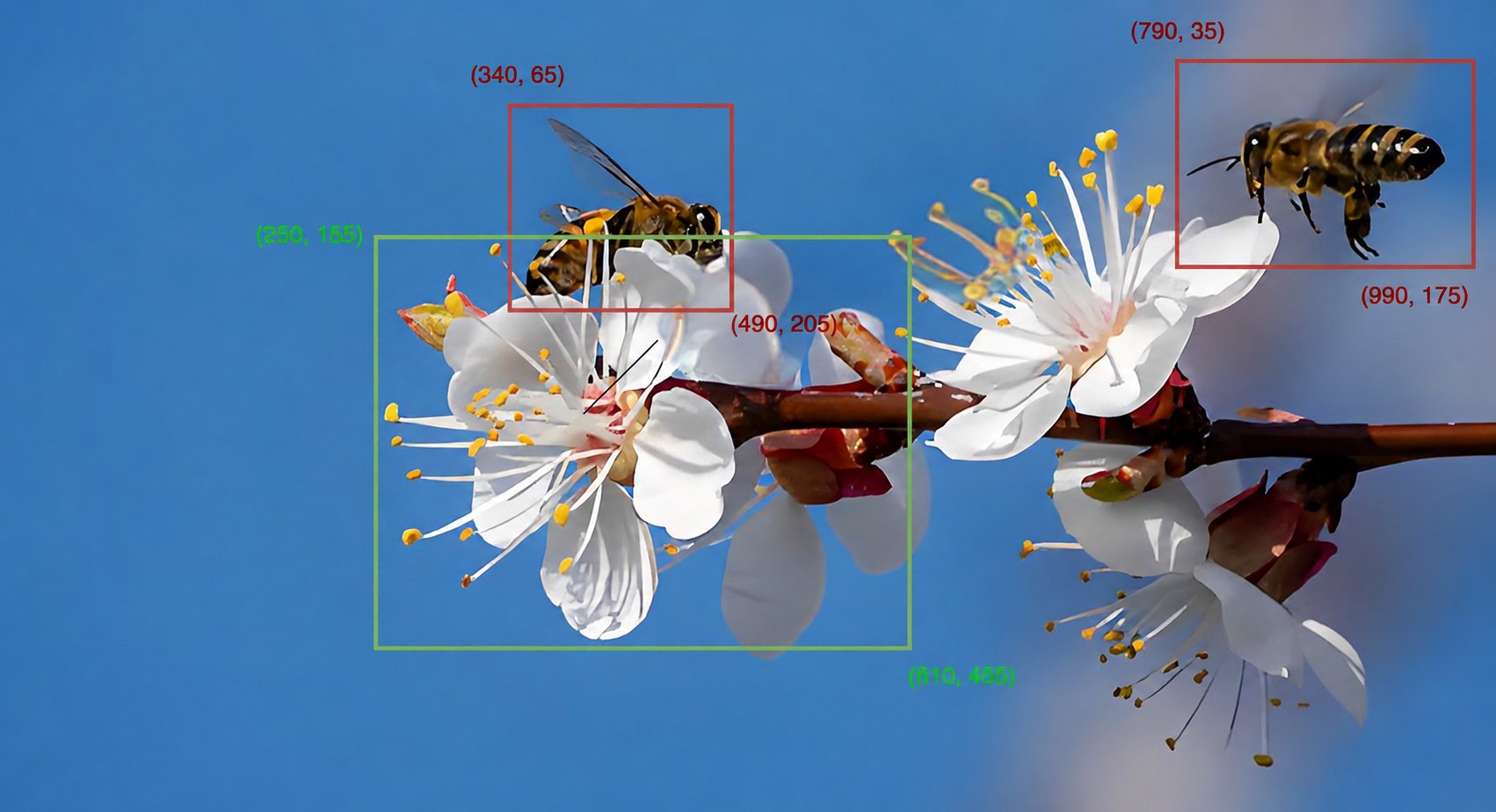
<img>与</img>标记图像内容边界。 - Bounding box 输入输出:为了支持 grounding,论文把 bounding box 坐标归一化到
[0, 1000),并转换成字符串格式,例如(X_top left, Y_top left), (X_bottom right, Y_bottom right)。box 字符串用<box>与</box>包裹。 - Reference 标记:为了把描述文本和对应 box 关联起来,使用
<ref>与</ref>标记被定位的文本片段。
这种设计的好处是:box 不需要额外的位置词表,而是作为普通文本 token 被 LLM 生成和理解。它把 grounding 任务转化为语言建模任务,使 captioning、VQA、grounding、OCR 等任务可以共享自回归生成框架。
下面是一条典型的grounding 任务的样本实例

6.3 三阶段训练流程
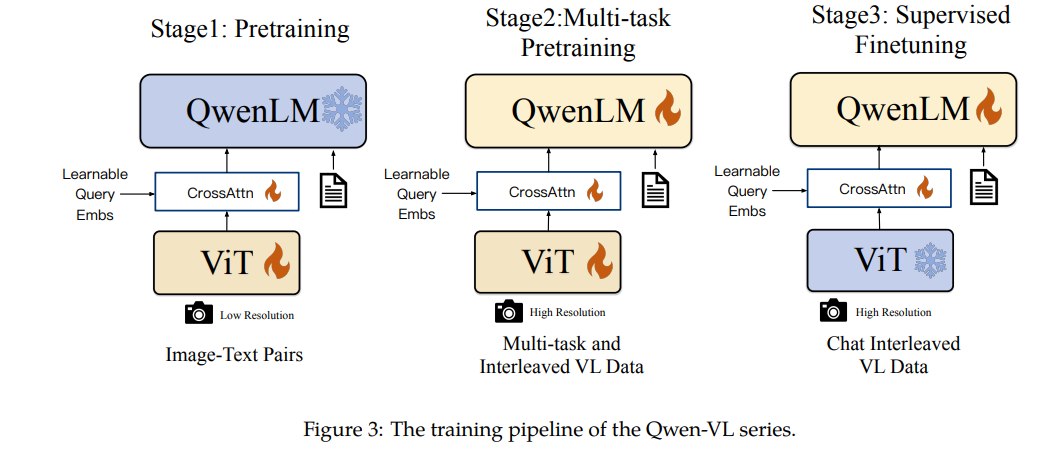
论文把训练分成三个阶段。
第一阶段:Pre-training
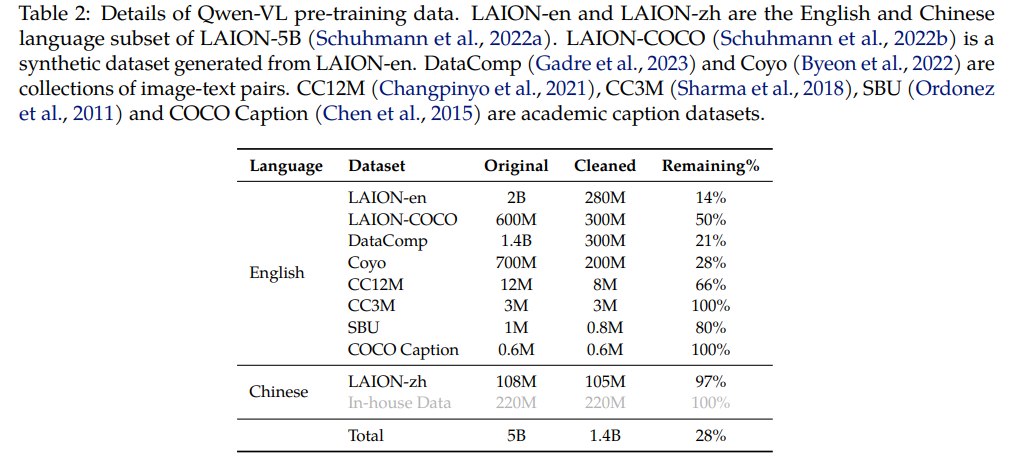
使用大规模弱标注 web-crawled image-text pairs。原始数据约 5B,清洗后保留 1.4B,其中英文文本数据占 77.3%,中文文本数据占 22.7%。数据来源包括 LAION-en、LAION-zh、LAION-COCO、DataComp、Coyo、CC12M、CC3M、SBU、COCO Caption 和 in-house data。
这一阶段冻结 LLM,只优化视觉编码器和 VL adapter。图像分辨率为 224 x 224,目标是最小化文本 token 的 cross-entropy。训练 50,000 steps,batch size 为 30,720,约消耗 1.5B image-text samples。
第二阶段:Multi-task Pre-training
引入高质量、细粒度视觉语言标注数据,并把图像分辨率提升到 448 x 448。这一阶段解冻 LLM,训练整个模型。任务包括:
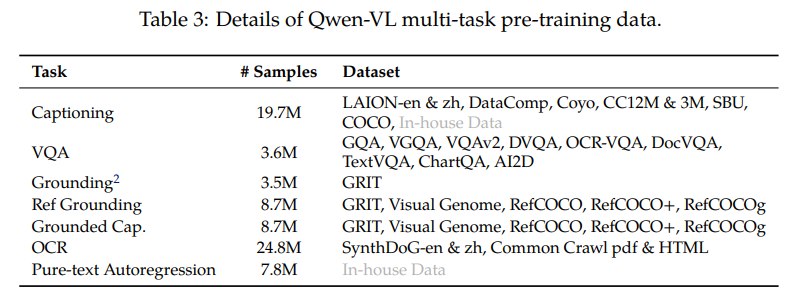
多任务训练是 Qwen-VL 能力形成的核心。它把普通图文对齐、VQA、grounding、OCR、文档理解、纯文本生成混合起来,让模型同时具备通用理解和细粒度视觉语言能力。
第三阶段:Supervised Fine-tuning
对 Qwen-VL 进行 instruction fine-tuning,得到 Qwen-VL-Chat。SFT 数据约 350K,来源包括 caption/dialogue 数据、人工标注、模型生成和策略拼接,重点补充 localization 和 multi-image comprehension。该阶段冻结视觉编码器,优化语言模型和 adapter,并混合多模态与纯文本对话数据,以保持通用对话能力。
7. 实验
实验部分覆盖面很广,目标是证明 Qwen-VL 不只是某个单项任务强,而是作为 generalist LVLM 在 captioning、VQA、text-oriented VQA、grounding、few-shot learning 和 instruction following 上都有竞争力。
7.1 Image Captioning 与 General VQA
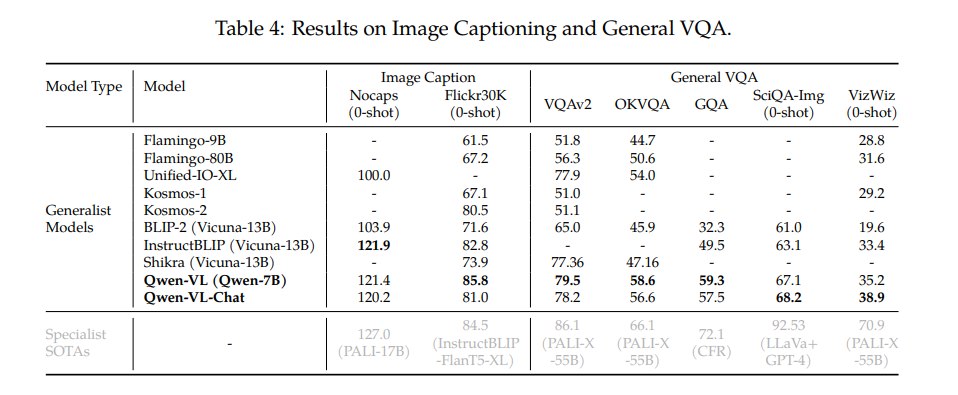
论文在 Nocaps、Flickr30K、VQAv2、OKVQA、GQA、ScienceQA-Img、VizWiz 等数据集上评估。结果显示:
- Qwen-VL 在 Flickr30K zero-shot captioning 上达到 85.8 CIDEr,超过 Flamingo-80B 等更大模型;
- 在 VQAv2、OKVQA、GQA 上分别达到 79.5、58.6、59.3;
- Qwen-VL-Chat 在 ScienceQA-Img 和 VizWiz 上表现更强,说明 instruction tuning 有助于部分交互式或真实场景任务。
这里的关键点是,Qwen-VL-7B 规模不算最大,但在多个 generalist model 比较中表现突出。论文用这一组实验支撑 “leading performance under similar model scales”。
7.2 Text-oriented VQA
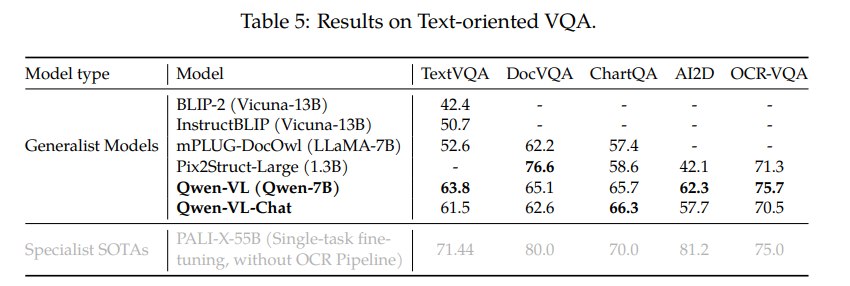
Text-oriented VQA 是 Qwen-VL 的重点能力之一。论文评估 TextVQA、DocVQA、ChartQA、AI2D、OCR-VQA。结果包括:
- Qwen-VL 在 TextVQA 上达到 63.8,明显高于 BLIP-2、InstructBLIP、mPLUG-DocOwl;
- 在 DocVQA 上达到 65.1;
- 在 ChartQA 上 Qwen-VL-Chat 达到 66.3;
- 在 AI2D 上 Qwen-VL 达到 62.3;
- 在 OCR-VQA 上 Qwen-VL 达到 75.7。
这些结果说明 OCR、PDF/HTML 渲染数据、SynthDoG 英中合成数据对 text-reading 能力有明显帮助。相比只用自然图像问答数据的 LVLM,Qwen-VL 对带文字图像、文档、图表、科学图示的支持更强。
7.3 Referring Expression Comprehension / Grounding
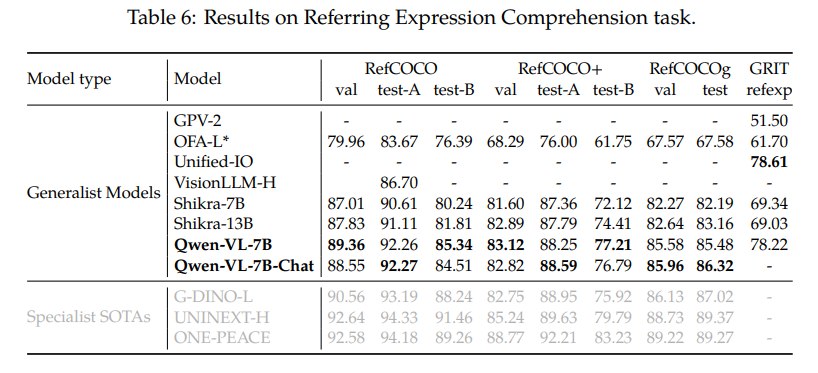
论文用 RefCOCO、RefCOCO+、RefCOCOg、GRIT 等 benchmark 测试定位能力。Qwen-VL 在多个 split 上接近或超过当时 generalist models,甚至部分接近 specialist SOTA。例如 Qwen-VL-7B 在 RefCOCO val/test-B、RefCOCO+ val/test-B、RefCOCOg 等任务上表现强劲。
这部分实验支撑了论文标题中的 “Localization”。由于 Qwen-VL 把 box 坐标作为文本输出,grounding 能力本质上来自接口设计与 grounding 数据训练的结合。
7.4 Few-shot Learning
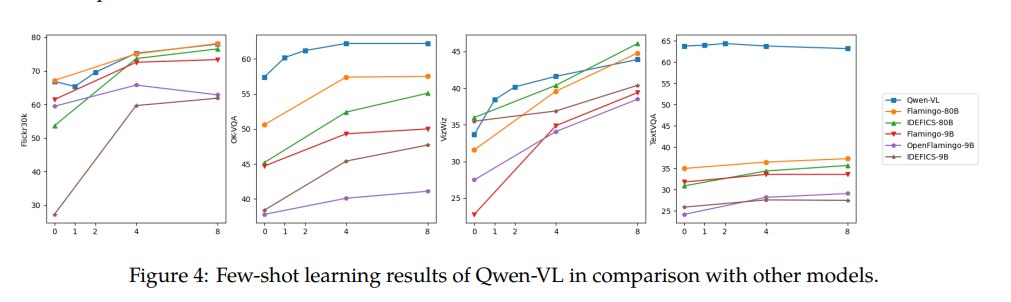
论文还评估了视觉语言任务上的 in-context few-shot learning,包括 OKVQA、VizWiz、TextVQA、Flickr30K。作者指出 Qwen-VL 相比 Flamingo-9B、OpenFlamingo-9B、IDEFICS-9B 等同规模模型有更好的 few-shot 表现,甚至可接近更大规模模型。
重要的是,论文说明 few-shot 示例采用朴素随机采样,没有使用 RICES 等更复杂的 exemplar selection 方法。这有助于增强实验说服力,因为性能不是依赖精心设计的 few-shot 检索策略。
7.5 Instruction Following in Real-world User Behavior
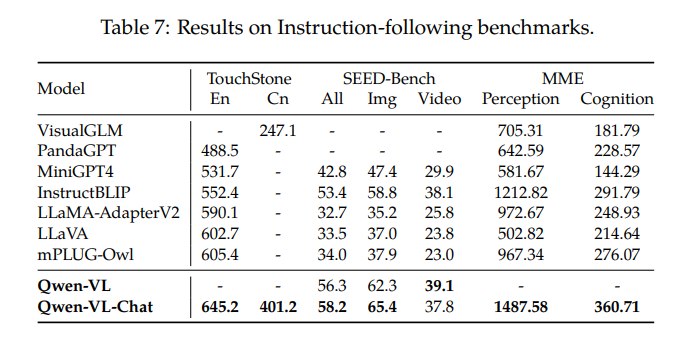
Qwen-VL-Chat 在 TouchStone、SEED-Bench、MME 上评估真实用户行为下的视觉语言指令跟随能力。结果显示:
- TouchStone 英文得分 645.2,中文得分 401.2,超过 VisualGLM、MiniGPT-4、InstructBLIP、LLaVA、mPLUG-Owl 等;
- SEED-Bench overall 达到 58.2,image 维度 65.4;
- MME perception / cognition 分别达到 1487.58 / 360.71。
这一组实验突出 Qwen-VL-Chat 的对话与指令跟随能力,尤其强调中文能力和理解识别类任务。论文还提到,在 SEED-Bench 中,简单采样四帧即可把视觉能力迁移到 video tasks,这为后续 Qwen-VL 向视频扩展埋下伏笔。
7.6 附录中的补充实验
附录提供了几个有价值的细节:
- 数据清洗流程:对 web-crawled image-text pairs 做 aspect ratio、图像尺寸、CLIP score、语言字符、emoji、文本长度、HTML tag 等过滤。
- OCR 数据构造:SynthDoG 使用 COCO 背景、41 种英文字体和 11 种中文字体生成文本;PDF 用 PyMuPDF 渲染页面并提取文本 bbox;HTML 用 Puppeteer 渲染和提取。
- Adapter query 数量 ablation:最终选择 256 queries,因为太少会丢失视觉信息,太多会增加收敛难度和计算成本。
- Window attention vs global attention:实验发现 window attention loss 更高,训练速度优势有限,因此最终使用 vanilla/global attention。
- 纯文本能力:通过混合 pure-text data,Qwen-VL 没有明显损害文本任务能力,在 MMLU、CMMLU、C-Eval 上相对 Qwen-7B intermediate checkpoint 还有一定提升。

说些什么吧!