
零、写在前面
Qwen3-VL 相比 Qwen2.5-VL 做了一车改进,MoE、256K interleaved context、Interleaved MRoPE、DeepStack、textual timestamp、square-root reweighting、thinking / non-thinking 后训练、knowledge distillation、reinforcement learning、tool-integrated reasoning,读的头大。
一、摘要
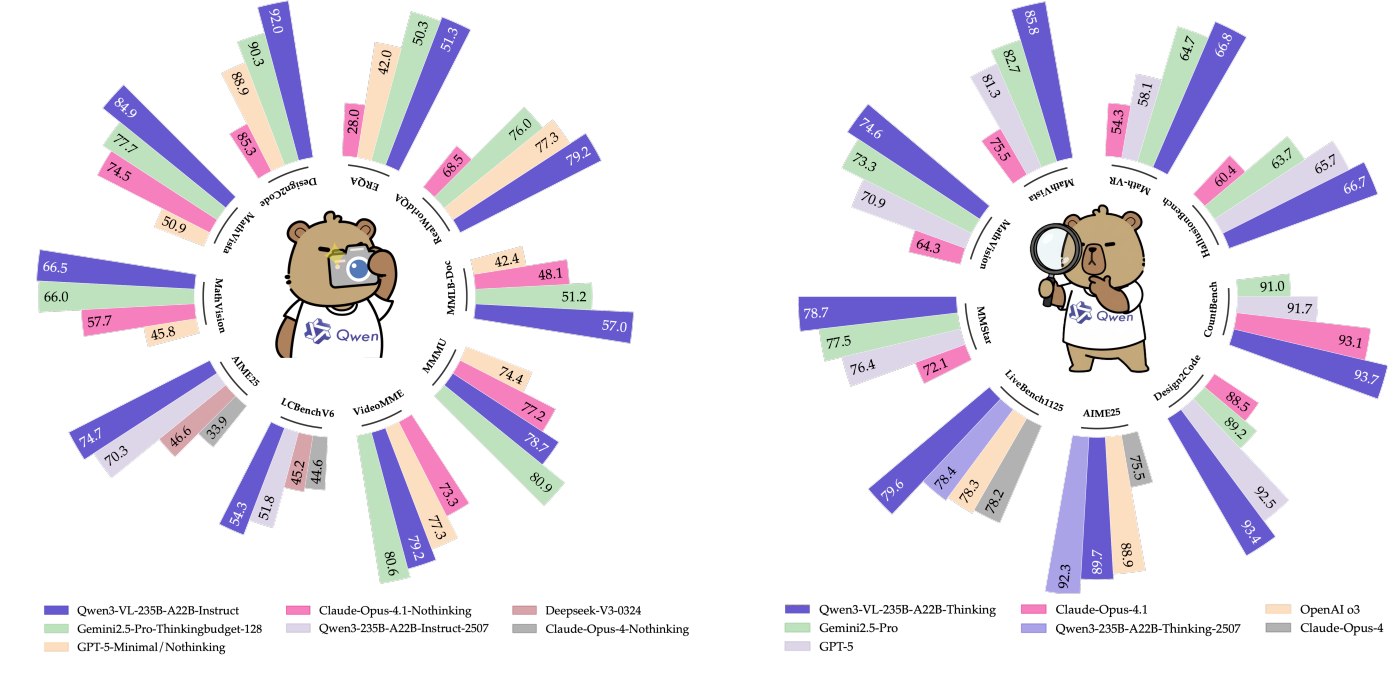
摘要将 Qwen3-VL 定位为 Qwen 系列迄今最强的 vision-language model。核心主张包括:
- 原生支持 up to 256K tokens 的 interleaved context,可混合处理 text、images、video;
- 同时提供 dense 和 MoE 版本,以适配不同 latency-quality trade-offs;
- 有三大能力支柱:更强 pure-text understanding、长上下文多模态理解、复杂多模态推理;
- 架构上引入 Interleaved MRoPE、DeepStack、text-based time alignment;
- 训练上使用 square-root reweighting 平衡 text-only 与 multimodal learning objectives;
- post-training 分成 non-thinking 和 thinking 两类模型;
- 增加 post-training compute,并在 dense 和 MoE 架构中都取得强性能。
摘要里的核心升级可以概括为:
- Qwen2.5-VL:看得更细、视频更长、文档更强、agent 更可用
- Qwen3-VL:上下文更长、推理更强、模型族更完整、后训练更modern、工具与 agent 更深入
1. 256K interleaved context 是什么?
普通 LLM 的 long context 主要指长文本。Qwen3-VL 说的是 interleaved context,也就是上下文里可以交错出现:
文本段落 -> 图片 -> 表格截图 -> 文本说明 -> 视频帧序列 -> 问题
这对长文档和长视频非常关键。比如分析一本教材、几十页 PDF、或者两小时视频时,模型要在大量文本、页面图像、图表和视频帧之间做检索与交叉引用。
2. thinking / non-thinking 是什么?
报告把 post-training 分成 non-thinking 和 thinking variants。可以简单理解为:
- Instruct / non-thinking:更适合日常问答、OCR、文档抽取、GUI 操作等需要直接输出的任务。
- Thinking:显式训练模型产生较长的 Chain-of-Thought reasoning,更适合数学、视觉推理、STEM、复杂图表理解、长链路 agent 决策。
需要注意,thinking 不总是更强。报告里一些 OCR、RealWorldQA 或直接感知任务中,Instruct 版本可能更好;因为这些任务不需要很长推理,过度 reasoning 反而可能引入噪声或延迟。
3. square-root reweighting 解决什么问题?
多模态训练里,text-only 数据和 multimodal 数据的 token 统计非常不平衡。图像和视频会产生大量 visual tokens,如果简单按 token 平均 loss,某类数据可能支配训练;如果按 sample 平均,长样本又可能权重不足。
报告提到从 per-sample loss 转向 square-root-normalized per-token loss。直观上,它试图在“每条样本一票”和“每个 token 一票”之间折中:
样本太短:不能被长样本完全淹没
样本太长:也不能因为 token 多就过度主导训练
这类 reweighting 是现代大模型训练中很常见但容易被忽略的 trick。它不改变模型结构,却会明显影响 text ability 与 multimodal ability 的平衡。
假设一个样本有 n 个 token,每个 token 的 loss 是 l_j。
普通 per-token loss 类似:
$$ > L_i = sum(l_j) > $$或者在 batch 里按所有 token 平均。这样长样本 token 多,贡献就大。
普通 per-sample loss 类似:
$$ > L_i = (1 / n) * sum(l_j) > $$这样每个样本贡献差不多,不管它是 100 tokens 还是 10000 tokens。
而 square-root-normalized per-token loss 可以粗略理解为:
$$ > L_i = (1 / sqrt(n)) * sum(l_j) > $$
二、引言
引言首先说明 VLM 已经从基础视觉感知走向多模态推理、长上下文理解、STEM reasoning、GUI interaction 和 agentic workflows。作者强调一个关键要求:多模态训练不能破坏底座 LLM 的语言能力。
Qwen3-VL 的核心目标是:
- 保持甚至增强 text-only 能力;
- 支持 256K 上下文;
- 提供 dense 与 MoE 两条模型路线;
- 同时发布 non-thinking 和 thinking 版本;
- 用 pretraining 与 post-training 两阶段构建模型能力;
- 通过数据、架构和 RL 后训练连接 perception、reasoning、action。
引言明确列出三个架构改进:
- Enhanced positional encoding:从 Qwen2.5-VL 的 MRoPE 改为 Interleaved MRoPE;
- DeepStack for cross-layer fusion:把不同 ViT 层的视觉 token 注入对应 LLM 层;
- Explicit video timestamps:用文本时间戳替代 Qwen2.5-VL 中基于位置编码的 absolute-time alignment。
训练流程也在引言中概括:
- Pretraining:S0 merger alignment,然后 S1 8K、S2 32K、S3 256K;
- Post-training:SFT、Strong-to-Weak Distillation、Reinforcement Learning。
1. 为什么 Qwen3-VL 不继续沿用 Qwen2.5-VL 的 absolute-time MRoPE?
Qwen2.5-VL 把 MRoPE 的 temporal IDs 对齐到绝对时间,让模型通过位置编码感知真实时间。但 Qwen3-VL 指出两个问题:
- 长视频会产生很大、很稀疏的 temporal position IDs,削弱长时间上下文理解;
- 要让模型学好这种位置编码,需要覆盖不同 FPS 的大规模均匀采样,数据构造成本高。
所以 Qwen3-VL 改成 textual timestamp,例如在视频 temporal patch 前加 <3.0 seconds> 或 HMS 格式时间戳。这样时间信息变成模型已经擅长处理的文本 token。
也就是说:
Qwen2.5-VL:把时间藏进位置编码里
Qwen3-VL:把时间直接写给模型看
前者更“结构化”,后者更“语言化”。Qwen3-VL 选择后者,是因为长视频场景下更直接、更稳定,也更容易被 LLM 使用。
2. 为什么要强调不要损伤 LLM 语言能力?
多模态模型不是视觉模型加一个聊天界面。它的推理、规划、代码、数学和指令跟随大量依赖语言模型底座。如果加入图像/视频训练后,文本能力下降,那么复杂多模态任务也会受损。
Qwen3-VL 在 Evaluation 中专门评估 text-centric tasks,并声称 VL 模型在一些文本任务上能达到或超过对应 text-only backbone。这是很重要的系统目标:多模态增强不应该以语言退化为代价。
三、模型
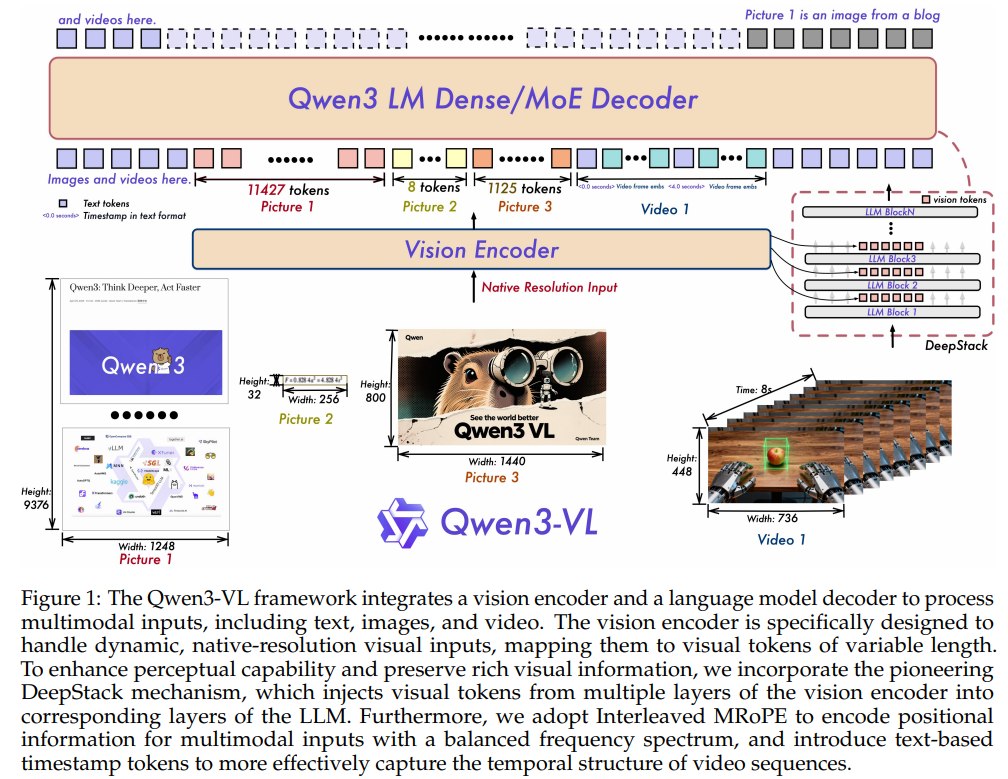
Qwen3-VL 仍采用三模块架构:
Vision Encoder -> MLP-based Vision-Language Merger -> Qwen3 LLM Decoder
但模型部分有三个关键升级:
- Interleaved MRoPE:改善 t/h/w 三个位置维度的频率分配;
- DeepStack:从 ViT 中间层抽取多层视觉特征,注入 LLM 前几层;
- Video Timestamp:用显式文本时间戳表示视频时间。
此外,Qwen3-VL 的 LLM backbone 包括 dense 和 MoE 两类:
| 类型 | 模型 |
|---|---|
| Dense | Qwen3-VL-2B、4B、8B、32B |
| MoE | Qwen3-VL-30B-A3B、235B-A22B |
视觉编码器方面,报告使用 SigLIP-2 architecture,并继续进行 dynamic resolution training。小规模 LLM 使用 SigLIP2-Large,默认使用 SigLIP2-SO-400M。
3.1 Interleaved MRoPE
Qwen2-VL / Qwen2.5-VL 的 MRoPE 把 embedding dimensions 分成 temporal、height、width 三块。问题是这种分块会导致三种轴使用不同频段,形成 imbalanced frequency spectrum。报告认为这会损害 long-video understanding。
Qwen3-VL 的 Interleaved MRoPE 把 t、h、w 交错分布到 embedding dimensions 中,让每个轴都能覆盖低频和高频。
旧版 MRoPE:分块
pair index: 0 1 2 3 | 4 5 6 7 | 8 9 10 11 axis used: t t t t | h h h h | w w w w freq band: 高频 ---------> 中频 ---------> 低频Interleaved MRoPE:交错
pair index: 0 1 2 | 3 4 5 | 6 7 8 | 9 10 11 axis used: t h w | t h w | t h w | t h w freq band: 高频 -------------------------------> 低频
为什么频率重要?RoPE 的不同频率对应不同尺度的位置建模。低频更适合长距离、全局位置;高频更适合短距离、局部细节。如果某个轴缺少低频或高频,就可能在长视频或细粒度空间定位中吃亏。
3.2 DeepStack
普通 VLM 往往只取 vision encoder 最后一层输出,再经过 merger 输入 LLM。问题是 ViT 不同层包含不同层次视觉信息:
- 浅层:边缘、纹理、局部形状;
- 中层:部件、区域结构;
- 深层:语义对象、场景概念。
Qwen3-VL 的 DeepStack 选择 vision encoder 中三个层级的 features,用专门 merger 投影成 visual tokens,然后通过 lightweight residual connections 加到 LLM 前三层 hidden states 中。
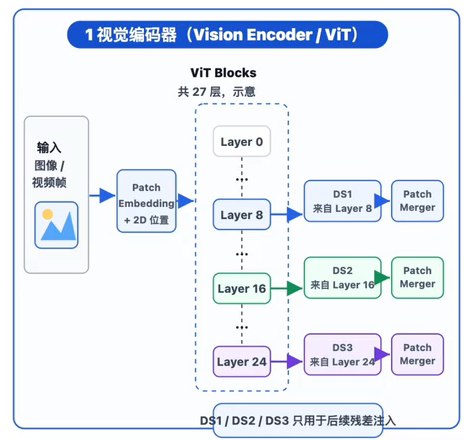
Q:ViT 的层级输出的token序列长度和LLM的输入长度不同,怎么做残差连接呢?
A:
LLM的输入是 文本token + 视觉token,残差连接加到视觉部分就好了。
直观上:
传统方式:只把最终视觉表示交给 LLM
DeepStack:把浅层、中层、深层视觉信息分层注入 LLM
它的好处是增强 vision-language alignment,尤其对细粒度视觉理解、OCR、文档、图表和 grounding 有帮助。报告的 DeepStack 消融也显示平均指标从 74.7 提升到 76.0,InfoVQA、DocVQA、ChartQA、MMMU、MMStar 等都有提升。
3.3 Text-based Video Timestamp
Qwen3-VL 把每个视频 temporal patch 前缀成文本时间戳,例如 <3.0 seconds>。训练时同时使用 seconds 和 HMS 格式,让模型能理解不同时间表达。
这有一个很实际的好处:时间变成自然语言上下文的一部分。模型可以像读字幕一样读时间,而不是只靠位置编码去猜。
代价是上下文长度会增加,因为时间戳本身也占 token。但在 256K context 的条件下,这个代价相对可接受。
4. MoE
MoE 是 Qwen3-VL 相对 Qwen2.5-VL 的重要扩展。它的核心思想是把模型容量拆成多个 experts,每个 token 由 router 选择少数 experts 处理。
优点:
- 总参数大,知识容量高;
- 每个 token 激活参数少,推理成本低于同等总参数 dense model;
- 适合在质量和延迟之间折中。
风险:
- 训练和部署更复杂;
- expert 负载均衡、router 稳定性、通信开销都是工程难点;
- 小 batch 或在线服务中可能出现效率不稳定。
报告中的 235B-A22B 就体现了这种取舍:它有 235B 总参数,但每个 token 激活约 22B,试图以较低激活成本获得大模型容量。
四、预训练
Qwen3-VL 的 pre-training 分四阶段:
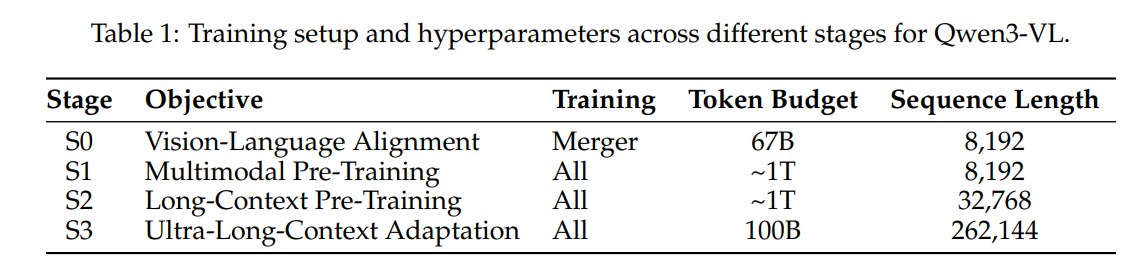
这个流程比 Qwen2.5-VL 更明显地围绕长上下文展开:先对齐视觉和语言,再做全参数多模态预训练,再扩到 32K,最后扩到 256K。
预训练数据覆盖:
- image caption 和 interleaved text-image;
- knowledge;
- OCR、document parsing、long document understanding;
- grounding 和 counting;
- spatial understanding 和 3D recognition;
- code;
- video;
- STEM;
- agent。
1. S0 为什么只训练 merger?
S0 的目标是 vision-language alignment。视觉编码器和 LLM 都先冻结,只训练 MLP merger。这样做有两个好处:
- 训练成本低;
- 避免一开始就破坏视觉 encoder 和 LLM 已有能力。
可以理解为先学一个“翻译器”:把视觉特征翻译成 LLM 能理解的 embedding 空间。等桥搭好了,再进行全参数训练。
2. 长上下文训练为什么要分 S1 / S2 / S3?
直接从 8K 跳到 256K 成本太高,也容易训练不稳定。Qwen3-VL 用课程式扩展:
8K:基础多模态能力
32K:长文档、长视频、多步任务
256K:超长文档和超长视频适应
S3 只有 100B tokens,比 S1/S2 少很多,因为它更像专门的长上下文适配阶段,而不是重新学习全部知识。
3. Image caption 和 interleaved 数据的升级
Qwen3-VL 用 Qwen2.5-VL-32B 进行 recaptioning,把原始网页文字改写成更细粒度、更流畅、更包含视觉细节的 caption。并且只对 recaptioned text 做去重,避免删掉视觉上不同但文字相似的样本。
对 interleaved book-scale data,报告使用 Qwen2.5-VL-7B 做多模态 parsing,把文本和 embedded figures、diagrams、photographs 对齐;还把连续页面合并到 up to 256K tokens,用于 ultra-long context modeling。
这一点很重要:长上下文不是简单把很多页拼起来,还要保证页面顺序、图文对齐、图文比例和视觉-文本交互密度。
4. OCR、文档和 long document
Qwen3-VL 的 OCR 数据扩展很大:
- 30M in-house OCR samples;
- 额外 29 种语言;
- 约 30M multilingual synthetic OCR samples;
- 超过 1M internal real-world multilingual images。
文档解析方面:
- 从 Common Crawl 收集 3M PDFs,覆盖 10 类文档;
- 加入 4M internal documents;
- 用 layout model 预测阅读顺序和 bbox;
- 用 Qwen2.5-VL-72B 做区域识别;
- 统一为 QwenVL-HTML 和 QwenVL-Markdown 两种格式。
相对 Qwen2.5-VL,Qwen3-VL 更强调 long document understanding:把多页图像放在前面,再接对应 OCR/HTML 文本,并构造跨页 VQA,让模型学会多页、多模态、多跳推理。
5. Grounding 从绝对坐标回到归一化坐标
Qwen2.5-VL 强调基于实际图像尺寸的 absolute coordinates。Qwen3-VL 则采用 scaled to [0, 1000] 的 normalized coordinate system。
假设原图尺寸是:
width = 1920 height = 1080某个物体在原图中的 bounding box 是:
x1 = 480 y1 = 270 x2 = 1440 y2 = 810归一化公式:
x_norm = x / width * 1000 y_norm = y / height * 1000所以:
x1_norm = 480 / 1920 * 1000 = 250 y1_norm = 270 / 1080 * 1000 = 250 x2_norm = 1440 / 1920 * 1000 = 750 y2_norm = 810 / 1080 * 1000 = 750模型输出就是:
{"bbox": [250, 250, 750, 750]}
这不是简单倒退,而是另一种工程取舍:
- 绝对坐标有利于学习真实尺度;
- 归一化坐标更稳健,方便跨分辨率、跨长宽比和下游 post-processing。
Qwen3-VL 面向更广泛输入和部署,归一化坐标可能更容易让不同分辨率任务共享同一输出格式。
6. 3D Grounding 和 Embodied Spatial Data
Qwen3-VL 加入 3D grounding:输入单目图像和 referring expression,输出结构化 JSON 格式的 9-DoF 3D bounding box。9-DoF 通常包括位置、尺寸和旋转等自由度。
这对 embodied AI 很重要。2D grounding 只能说“物体在图片哪里”;3D grounding 试图回答“物体在三维空间哪里、朝向如何、可如何交互”。这为机器人、导航、具身操作提供基础。
7. Multimodal Coding
Qwen3-VL 加入视觉到代码的数据,例如:
- UI screenshot -> responsive HTML/CSS;
- image -> editable SVG;
- flowchart / diagram / LaTeX equation -> code or markup;
- StackOverflow posts with images -> multimodal coding QA。
这说明 Qwen3-VL 不只做“看图回答”,还想把视觉内容转成可执行或可编辑的结构。这是 multimodal code intelligence 的核心。
8. STEM 数据和 Long CoT 数据
STEM(Science, Technology, Engineering, and Mathematics)部分采用 divide-and-conquer:先加强视觉感知和语言推理,再整合成多模态推理。报告提到:
- 1M 几何图中的 point-grounding samples;
- 2M perception-oriented VQA;
- 6M diagram captions;
- 60M K-12 和本科级 multimodal reasoning exercises;
- 12M multimodal long CoT samples。
这些数据支撑 thinking model 在 MathVista、MathVision、MMMU、LogicVista 等任务上的表现。
五、后训练
Qwen3-VL 的 post-training 是这篇报告最Modern的部分(看的头晕)。它分三阶段:
- Supervised Fine-Tuning (SFT):赋予 instruction-following,并激活推理能力;
- Strong-to-Weak Distillation:用强 teacher model 提升较弱 student model;
- Reinforcement Learning (RL):进一步增强 reasoning、instruction following、alignment 和鲁棒性。
此外,报告单独介绍:
- Long-CoT cold start data;
- Reasoning RL;
- General RL;
- Thinking with Images;
- tool-integrated RL。
5.1 SFT:模仿高质量答案
SFT 是最容易理解的后训练:给模型输入和标准答案,让模型学习“用户这样问时应该这样答”。
Qwen3-VL 的 SFT 数据约 1.2M samples:
- 约 1/3 text-only;
- 约 2/3 image-text 和 video-text;
- 包含单轮、多轮、单图、多图、视频、工具增强图像搜索、视觉 grounding reasoning;
- 先用 32K context 训练一轮,再用 256K context 训练一轮;
- 长上下文包括 hundreds of pages technical documents、entire textbooks、up to two hours videos。
Qwen3-VL 还把 SFT 数据分成两种格式:
- non-thinking models:标准回答格式;
- thinking models:Chain-of-Thought 格式,显式包含推理过程。
5.2 Long-CoT Cold Start:给 thinking model 一个起跑姿势
Long-CoT cold start data 是 thinking model 的基础。它不是让模型从零通过 RL 自己摸索推理,而是先给它一批高质量、长链路、难度较高的推理样本。
报告中的关键过滤非常值得注意:
- 保留 baseline pass rate 低或需要更长回答的问题;
- 对 vision-language math,丢弃那些不看图也能被 Qwen3-30B-nothink 正确解出的样本;
- 过滤重复、语言混杂、错误答案、猜测式答案。
这个 “multimodal necessity filtering” 很重要。它确保数据确实需要视觉输入,而不是文字里已经泄露答案。否则模型可能看起来在做多模态推理,实际只是在做文本推理。
5.3 Strong-to-Weak Distillation:强模型教弱模型
Distillation 的核心是让强 teacher model 生成高质量回答或 logits,弱 student model 学习它。
报告分两步:
- Off-policy Distillation:teacher 生成的输出作为响应蒸馏,帮助 student 获得基础推理能力;
- On-policy Distillation:student 自己先生成回答,再用 teacher 的 logits 对齐,通过最小化 KL divergence 让 student 更接近 teacher。
这里的 on-policy 很关键,因为 student 自己生成的分布和 teacher 直接生成的分布不同。让 student 在自己的输出轨迹上学习 teacher,可以减少训练和推理分布不一致。
5.4 RL:不是游戏式试错,而是“奖励驱动的继续训练”
在 LLM/VLM 后训练中,RL 可以这样理解:
给模型一个问题
-> 模型采样多个答案
-> reward system 给每个答案打分
-> 训练算法提高高分答案的概率,降低低分答案的概率
它和 SFT 的区别是:
- SFT 学的是固定标准答案;
- RL 学的是“什么样的输出会得到更高奖励”。
在 Qwen3-VL 中,RL 不是让模型在真实世界中随便试错,而是在可验证任务或 judge model 上获得反馈。比如数学题可以用最终答案验证,代码题可以用 executor 跑测试,grounding 可以和 bbox/point 标注比较,格式要求可以用规则检查。
5.5 Reasoning RL
Reasoning RL 覆盖 mathematics、coding、logical reasoning、visual grounding、visual puzzles。它强调每个任务最好能 deterministic verification,也就是可用规则或代码验证。
数据准备过程:
- 对 multimodal queries,用 Qwen3-VL-235B-A22B 初步 checkpoint 每题采样 16 个回答;
- 如果 16 个都错,丢弃该 query;
- 去掉 preliminary RL 中提升潜力小的数据源;
- 得到约 30K RL queries;
- 训练每个模型时,每题采样 16 个回答;
- pass rate 超过 90% 的 easy queries 会被过滤。
为什么过滤 easy queries?因为如果题太简单,模型本来就会,RL 信号很弱;训练资源应该放在“模型有机会学会但还不稳定”的问题上。
RL 算法使用 SAPO,报告称它是 smooth and adaptive policy-gradient method。这里不深究公式,把它理解为一种更新模型策略的算法:根据 reward 调整模型输出分布,让高奖励响应未来更容易出现。
5.6 General RL
General RL 不只针对数学/代码推理,而是增强通用鲁棒性和对齐。任务包括:
- VQA;
- image captioning;
- OCR;
- document parsing;
- grounding;
- clock recognition;
- instruction following;
- structured output。
它优化两个维度:
- Instruction Following:是否满足用户约束,比如格式、长度、JSON、内容要求;
- Preference Alignment:开放问题中是否 helpful、factual、style appropriate。
General RL 还用于修正 SFT 中学到的错误先验,例如反直觉计数、复杂时钟识别、语言混杂、重复、格式错误。
5.7 Rule-Based Rewards 和 Model-Based Rewards
Qwen3-VL 的 RL 奖励有两类:
- Rule-Based Rewards:适合可明确验证的任务,如答案格式、JSON 合法性、数学最终答案、代码测试、坐标误差。优点是精确,不容易误判。
- Model-Based Rewards:使用 Qwen2.5-VL-72B-Instruct 或 Qwen3 作为 judge,适合开放式任务。优点是灵活,缺点是 judge 也可能有偏差。
报告还提到 reward hacking:模型可能找到奖励函数漏洞,而不是真正完成任务。比如 Thinking with Images 里,模型可能只调用一次工具就骗过前两个奖励。所以作者加入 Tool-Calling Reward,鼓励模型根据任务复杂度合理使用工具。
5.8 Thinking with Images
这部分非常有意思。Qwen3-VL 训练模型形成视觉 agent 式流程:
think -> act -> analyze feedback -> answer
两阶段流程:
- 合成约 10K grounding examples,对 Qwen2.5-VL-32B 做 SFT,让它学会视觉 agent 行为,再进行 multi-turn tool-integrated RL;
- 用训练好的 Qwen2.5-VL-32B visual agents 生成约 120K 多轮 agentic interactions,再用于 Qwen3-VL 的 cold-start SFT 和 tool-integrated RL。
三个奖励信号:
- Answer Accuracy Reward:最终答案是否正确;
- Multi-Turn Reasoning Reward:是否正确理解工具或环境反馈,并逐步推理;
- Tool-Calling Reward:工具调用次数是否与任务复杂度匹配。
这说明 Qwen3-VL 的 thinking 不只是“写长推理”,还包含“看图、调用工具、读反馈、再推理”的交互式能力。
六、Evaluation
Evaluation 覆盖范围非常广,包括:
- General VQA;
- Multimodal Reasoning;
- Alignment and Subjective Tasks;
- Text Recognition and Document Understanding;
- 2D and 3D Grounding;
- Fine-grained Perception;
- Multi-Image Understanding;
- Embodied and Spatial Understanding;
- Video Understanding;
- Agent;
- Text-Centric Tasks;
- Ablation Study;
- Needle-in-a-Haystack。
报告对 flagship、medium-size、small-size 模型分别给表,并区分 thinking 与 instruct。
6.1 General VQA
Qwen3-VL-235B-A22B-Instruct 在 MMBench 和 RealWorldQA 上取得强结果,报告表中为:
- MMBench-EN:89.3;
- MMBench-CN:88.9;
- RealWorldQA:79.2;
- MMStar:78.4。
Thinking 版本在 MMStar 上为 78.7,略高于 Instruct。中等模型里,Qwen3-VL-32B-Thinking 在 MMBench 和 RealWorldQA 上也很强。
阅读提醒:General VQA 并不总是 thinking 越强越好。有些任务主要考图像理解和常识回答,直接 Instruct 版本可能更稳。
6.2 Multimodal Reasoning
这是 Qwen3-VL 的重点能力。报告覆盖 MMMU、MMMU-Pro、MathVista、MathVision、MathVerse、DynaMath、LogicVista、VisualPuzzles 等。
旗舰模型代表结果:
- MMMU:Thinking 80.6,Instruct 78.7;
- MMMU-Pro:Thinking 69.3,Instruct 68.1;
- MathVista mini:Thinking 85.8,Instruct 84.9;
- MathVision:Thinking 74.6,Instruct 66.5;
- MathVerse mini:Thinking 85.0,Instruct 72.5;
- LogicVista:Thinking 72.2,Instruct 65.8。
这里可以清楚看到 thinking 对复杂推理有帮助,尤其 MathVision、MathVerse、LogicVista 这类需要多步推理的任务。
6.3 Alignment and Subjective Tasks
评测包括 MM-MT-Bench、HallusionBench、MIA-Bench。报告称 Qwen3-VL-235B-A22B 在 hallucination、复杂指令跟随和主观评测上表现强。
代表结果:
- HallusionBench:Thinking 66.7,Instruct 63.2;
- MM-MT-Bench:Thinking 8.5,Instruct 8.5;
- MIA-Bench:Thinking 92.7,Instruct 91.3。
这说明 thinking 对减少复杂视觉语境下的误判有帮助,但多轮对话评分上二者接近。
6.4 Text Recognition and Document Understanding
文档仍然是 Qwen 系列强项。旗舰模型代表结果:
- DocVQA test:Instruct 97.1;
- InfoVQA test:Thinking 89.5,Instruct 89.2;
- ChartQA test:90.3;
- OCRBench:Instruct 920;
- OCRBench_v2 en:Instruct 67.1;
- OCRBench_v2 zh:Thinking 63.5;
- CC-OCR:Instruct 82.2;
- MMLongBenchDoc:Instruct 57.0,Thinking 56.2。
报告还强调多语言 OCR:Qwen3-VL 从 Qwen2.5-VL 的 10 个非中英语言扩展到 39 个语言,并在 39 种语言中的 32 种超过 70% accuracy。
提醒:OCR 和 document parsing 不一定需要 thinking。表中 OCRBench、DocVQA 等任务 often Instruct 更强,因为它们更依赖准确感知和格式稳定,而不是长链推理。
6.5 2D / 3D Grounding
Qwen3-VL 加强了 2D grounding、counting 和 3D object localization。
代表结果:
- RefCOCO-avg:Thinking 92.1,Instruct 91.9;
- CountBench:Thinking 93.7,Instruct 93.0;
- ODinW-13:Instruct 48.6;
- ARKitScenes:Instruct 56.9;
- SUNRGBD:Instruct 39.4。
ODinW-13 用 mAP,且提示中同时给出所有类别。3D grounding 使用 Omni3D 相关数据,IoU threshold 为 0.15,并固定 detection confidence 为 1.0。
提醒:这里的 3D grounding 是从单目图像估计 3D box,难度很高;评价设置和 specialist detectors 不完全相同,不能简单说通用 VLM 已经完全替代专业 3D detection 模型。
6.6 Fine-grained Perception 和 Tool Use
报告展示工具增强后,Qwen3-VL 在 V*、HRBench4K、HRBench8K 上显著提升。旗舰 Instruct + tool 结果包括:
- V*:93.7+;
- HRBench4K:85.4+;
- HRBench8K:82.4+。
报告指出,加工具带来的收益有时超过单纯扩大模型规模。这是很重要的趋势:未来多模态能力不只是 scaling model parameters,还包括 scaling tool-integrated agentic learning。
6.7 Multi-Image、Spatial 和 Embodied Understanding
Qwen3-VL 在多图理解和空间具身任务上也有较强表现:
- MUIRBENCH:Thinking 80.1;
- EmbSpatialBench:Thinking 84.3;
- RefSpatialBench:Thinking 69.9;
- RoboSpatialHome:Thinking 73.9;
- VSI-Bench:Instruct 62.7。
这些任务考察跨图比较、空间关系、可供性、具身决策等。它们比普通 VQA 更接近真实 agent 或机器人场景。
6.8 Video Understanding
Qwen3-VL 的视频能力来自 interleaved MRoPE、textual timestamps、dense video captions、spatio-temporal grounding 和 256K context。
代表结果:
- MVBench:Instruct 76.5;
- Video-MME without subtitles:Instruct 79.2;
- MLVU-MAvg:Instruct 84.3;
- LVBench:Instruct 67.7;
- Charades-STA mIoU:Instruct 64.8;
- VideoMMMU:Thinking 80.0。
报告中说明评测最多使用 2,048 frames,总 video tokens 不超过 224K。对不同 benchmark,per-frame token 上限和 FPS 不同。作者也承认,由于 API 和资源限制,与 Gemini、GPT-5、Claude 的视频帧数设置不能保证完全公平。
这个自我限定很重要:长视频 benchmark 的比较非常受输入帧数、采样率、token 预算、字幕、评测器影响。
6.9 Agent
GUI grounding 和在线环境评测包括 ScreenSpot Pro、OSWorldG、AndroidWorld、OSWorld、WindowsAA。
代表结果:
- ScreenSpot Pro:Instruct 62.0;
- OSWorldG:Thinking 68.3,Instruct 66.7;
- AndroidWorld:Instruct 63.7;
- OSWorld:Thinking 38.1,Instruct 31.6;
- WindowsAA:Thinking 32.1,Instruct 28.9。
中等模型里 Qwen3-VL-32B 在 OSWorld 上达到 41.0,AndroidWorld 为 63.7。说明 agent 能力不只来自最大模型,小中型模型也有实用潜力。
6.10 Text-Centric Tasks
Qwen3-VL 专门比较 text-centric tasks,说明多模态训练没有明显破坏语言能力。旗舰 Instruct 在 AIME-25、HMMT-25、LiveCodeBench、Arena-Hard 等任务上很强;Thinking 版本在 AIME-25 为 89.7,LiveCodeBench v6 为 70.1。
有意思的是,报告指出 Qwen3-VL 作为 VLM,能在部分文本任务上接近或超过 text-only baselines。这说明视觉语言训练和后训练可能反过来增强某些推理能力,但具体原因仍需谨慎判断,可能来自数据、distillation、RL 和训练 compute 的共同作用。
6.11 Ablation 和 Needle-in-a-Haystack
消融包括:
- Vision Encoder:Qwen3-ViT 相比 SigLIP-2 在 VLM bench 上整体更强,OmniBench 从 50.1 提升到 53.0;
- DeepStack:平均分从 74.7 提升到 76.0,InfoVQA、DocVQA、ChartQA、MMMU、MMStar 等提升;
- Needle-in-a-Haystack:Qwen3-VL-235B-A22B-Instruct 在 30 分钟内,也就是 256K context 内达到 100% accuracy;通过 YaRN positional extension 外推到约 1M tokens、约 2 小时视频时仍保持 99.5%。
Needle-in-a-Haystack 是长上下文检索能力测试:把关键帧插入长视频不同位置,要求模型找到并回答问题。它主要验证长上下文中“找得到证据”,但不完全等同于真实长视频深度理解。
七、结论
结论将 Qwen3-VL 总结为 state-of-the-art vision-language foundation model series。核心贡献包括:
- 高质量多模态数据迭代;
- Interleaved MRoPE;
- DeepStack vision-language alignment;
- text-based temporal grounding;
- 256K-token interleaved context;
- dense 与 MoE 多规模部署;
- non-thinking 与 thinking post-training;
- 面向 embodied AI agents、tool-augmented reasoning 和 real-time multimodal control 的未来方向。
一句话概括:
Qwen3-VL 是从 Qwen2.5-VL 的“强感知多模态模型”进一步升级为“长上下文、多规模、强推理、可工具交互、可 agent 化”的多模态基础模型。
如果把 Qwen3-VL 的技术贡献压缩成一张图:
由image-2绘制
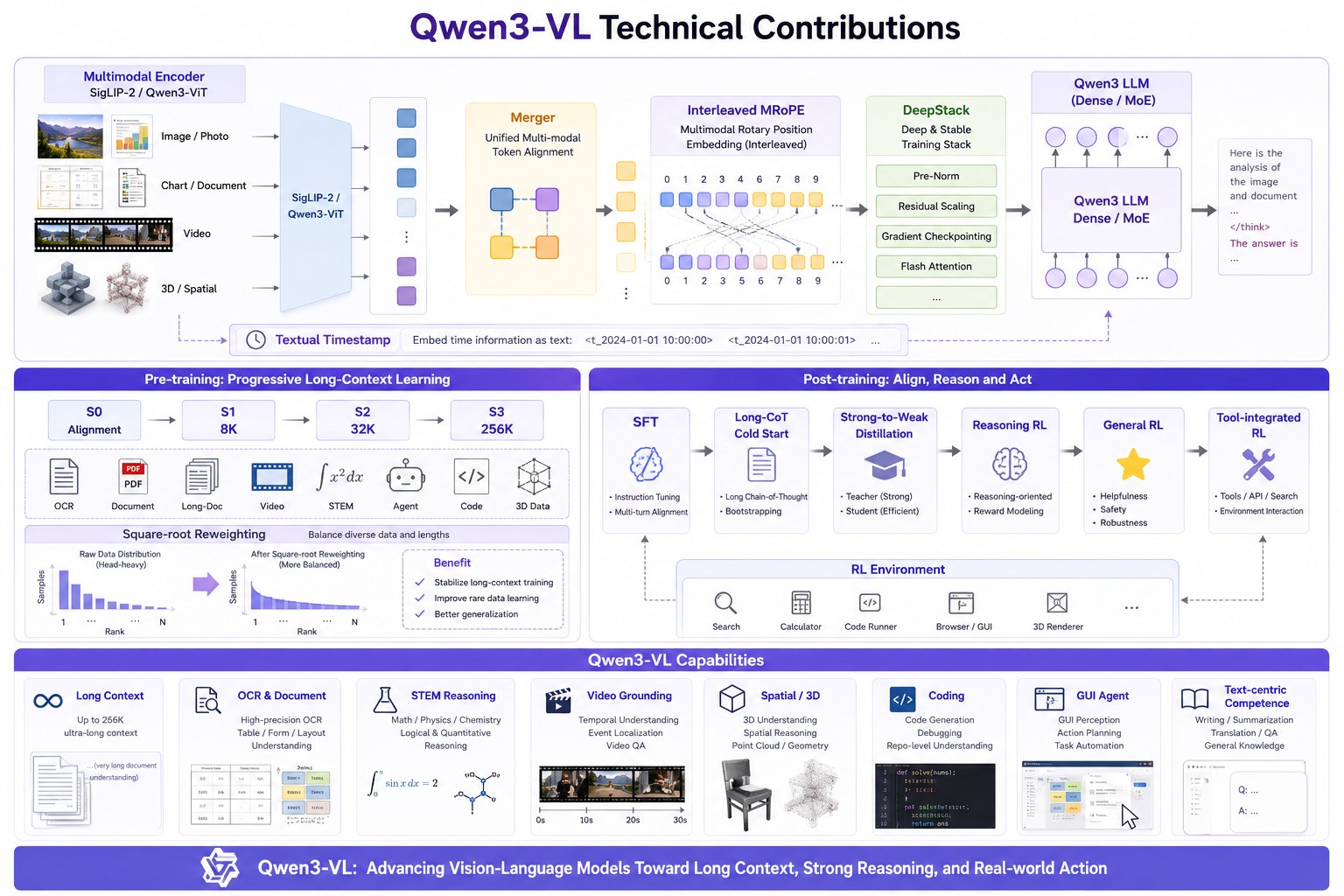
相对 Qwen2.5-VL,多了很多新东西:
- MoE:总参数大、激活参数小,用专家路由平衡能力和成本;
- Interleaved MRoPE:解决 t/h/w 分块带来的频率不均衡;
- DeepStack:把多层视觉特征注入 LLM,强化细粒度视觉对齐;
- Textual timestamp:把视频时间显式写成文本 token,替代复杂稀疏 temporal position IDs;
- 256K interleaved context:长文本、长文档、多图、视频帧混合上下文;
- Strong-to-Weak Distillation:强模型教弱模型,尤其帮助小模型;
- RL 后训练:通过 reward system 优化模型输出,不只是模仿数据;
- Thinking with Images:模型不只回答,还能 think、act、读工具反馈、再回答。

说些什么吧!