
零、写在前面
一、摘要
摘要把 Qwen2.5-VL 定位为 Qwen vision-language 系列的最新旗舰模型,强调它在基础能力和新功能上都有提升。核心能力包括:
- 更强的视觉识别与细粒度感知;
- 使用 bounding boxes 或 points 进行精确 object localization;
- 从 invoices、forms、tables 中抽取结构化数据;
- 分析 charts、diagrams、layouts 等复杂文档元素;
- 处理不同尺寸图像和长视频,支持 second-level event localization;
- 作为 visual agent 操作电脑和移动设备;
- 在 3B、7B、72B 三个规模上覆盖不同资源场景;
- 72B 版本在文档和图表理解上接近或超过 GPT-4o、Claude 3.5 Sonnet 等强模型。
摘要中最重要的技术关键词有四个:dynamic resolution processing、absolute time encoding、native dynamic-resolution ViT from scratch、Window Attention。这些关键词对应论文后文的方法主线。
1. 为什么 dynamic resolution 重要?
传统视觉语言模型经常把输入图像缩放到固定尺寸,例如 224x224、336x336 或某个固定 patch 网格。这么做便于 batch 训练,但对文档、表格、截图、海报、地图等图像很不友好。因为这些任务依赖小字、局部区域、长宽比和布局结构。如果强行压缩,模型还没开始推理,关键信息就可能已经丢失。
Qwen2.5-VL 的 dynamic resolution 思路是让不同尺寸的图片产生不同长度的 visual tokens。大图、细节多的图可以保留更多 token;小图或简单图则不必浪费同样的 token 预算。
这对文档理解尤其关键。比如一张 A4 发票和一张普通照片都压到同样大小,发票上的小字和表格线会更容易丢失;动态分辨率可以更自然地保留这类细节。
2. absolute time encoding 解决什么问题?
视频不是简单的图片序列。两个视频都采样 16 帧时,一个可能覆盖 4 秒,另一个可能覆盖 4 分钟。如果位置编码只知道“第 1 帧、第 2 帧、第 3 帧”,模型并不知道这些帧之间真实相隔多久。
这其实是很糟糕的,如果同样都是30s的两个视频,二者帧率不同,模型只靠帧数是无法区分两个视频其实在物理时间上是一致的。
Qwen2.5-VL 在 Qwen2-VL 的 MRoPE 基础上,把 temporal position IDs 对齐到绝对时间。这样模型可以通过 temporal IDs 的间隔感知事件节奏。例如:
- 某个动作发生在 3 秒到 5 秒之间;
- 某个场景持续了 2 分钟;
- 长视频中某个事件出现在第 1 小时附近。
这类能力对 long-video understanding 和 temporal grounding 很重要。
3. Window Attention 为什么能降计算量?
Transformer attention 的计算复杂度通常随 token 数量平方增长。图像分辨率越高,patch 越多,attention 成本会迅速变大。**Qwen2.5-VL 的视觉编码器在大多数层使用 window attention,只在少数层使用 full attention。**直观上:
- full attention:每个视觉 patch 都看所有 patch;
- window attention:每个 patch 主要看局部窗口内的 patch;
- 少数 full attention 层:负责补充全局信息交换。
论文中视觉编码器的 window size 是 112x112,对应 8x8 个 14x14 patches;只有第 7、15、23、31 层使用 full attention。这样既保留 native resolution,又降低视觉编码成本。
二、引言
引言先把 LVLM 描述为多模态理解与交互的重要突破,然后指出当前模型仍有瓶颈。
论文用了一个比较形象的比喻:现有多模态模型像夹心饼干的中间层,在很多任务上“能做”,但还不够卓越。
作者认为底层能力应该是 fine-grained visual tasks,也就是细粒度视觉感知;上层能力是 multi-modal reasoning,而 Qwen2.5-VL 要做的是把细粒度感知打牢,并作为 real-world applications 的 agentic amplifier。
引言列出的技术贡献主要有四点:
- 在视觉编码器中引入 window attention,提升推理效率;
- 引入 dynamic FPS sampling,把 dynamic resolution 扩展到时间维度;
- 将 MRoPE 的 temporal domain 对齐到 absolute time,增强时间序列学习;
- 大规模整理高质量预训练和 SFT 数据,把预训练语料从 1.2T tokens 扩展到 4.1T tokens。
随后,论文列出 Qwen2.5-VL 的四个突出特征:
- 强文档解析能力;
- 跨格式精确 object grounding;
- 超长视频理解与细粒度 video grounding;
- 面向电脑和手机设备的 agent 功能。
三、方法
方法部分分为三大块:模型架构、预训练、后训练。
Qwen2.5-VL 的整体结构仍然是常见的 LVLM 范式:
图像/视频输入 -> Vision Encoder -> Vision-Language Merger -> Qwen2.5 LLM Decoder -> 文本/结构化输出
但它在视觉编码器、位置编码、视频时间建模、数据构造和训练流程上做了多处升级。
3.1 模型架构
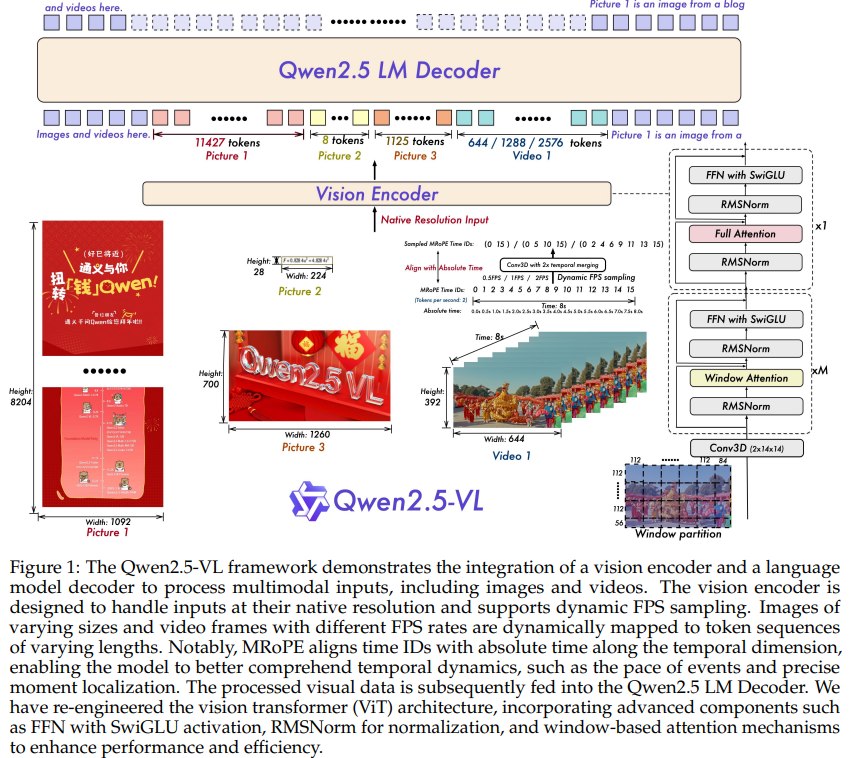
Large Language Model
Qwen2.5-VL 使用 Qwen2.5 LLM 作为语言基础。这个选择很重要,因为多模态模型的推理、对话、代码、数学和指令跟随能力,很大程度来自底座 LLM。论文还展示 Qwen2.5-VL 在纯文本任务上基本保持了 Qwen2.5-72B 的强能力。
Vision Encoder
视觉编码器是重新设计并从头训练的 ViT。主要设计包括:
- 输入图像的高和宽会调整为 28 的倍数;
- patch size 是 14;
- 使用 2D-RoPE 表示图像二维空间位置;
- 大多数层使用 window attention;
- 少数层使用 full attention;
- 采用 RMSNorm 和 SwiGLU,使 ViT 设计更接近现代 LLM。
Vision-Language Merger
视觉编码器输出的 patch features 不能直接全部喂给 LLM,否则序列太长、计算太贵。Qwen2.5-VL 用一个 MLP-based merger 把空间相邻的 4 个 patch features 分组、拼接,再投影到和文本 embedding 对齐的维度。
原始视觉 patch token 很多
-> 每 2x2 个相邻 patch 合并
-> 用 MLP 映射到 LLM 能接收的向量空间
-> LLM 把视觉 token 和文本 token 一起处理
这个模块的作用不是复杂推理,而是压缩和对齐。它让动态长度视觉输入能更经济地进入 LLM。
3.2 Native Dynamic Resolution and Frame Rate
Qwen2.5-VL 在空间和时间两个维度都做动态化。
空间动态化
图像以原始尺寸为基础生成可变长度 token 序列,并直接使用输入图像的实际尺寸来表示 bounding boxes 和 points。这与相对坐标不同。相对坐标通常把坐标归一化到 0 到 1 或 0 到 1000 的范围;绝对坐标则保留图像真实尺寸尺度。
绝对坐标的好处是,模型可以学习物体真实尺度和位置关系。例如同样是 “left top corner”,在不同尺寸截图中对应的坐标范围不同。使用实际尺寸有助于模型形成更贴近真实界面的空间理解。
时间动态化
视频输入使用 dynamic FPS training,并把 MRoPE 的 temporal IDs 与真实时间戳对齐。这样模型不仅知道第几帧,还能知道帧与帧之间的时间间隔。
这对 temporal grounding 很关键。例如,当模型回答“人在第几秒开始跑步”时,它需要把视觉事件映射到真实秒数,而不是只在抽样帧序号上做判断。
3.3 MRoPE Aligned to Absolute Time
Qwen2-VL 已经提出 MRoPE,把位置编码拆成 temporal、height、width 三个部分:
- 文本:三个维度使用相同 position IDs,近似普通 1D RoPE;
- 图像:temporal ID 固定,height 和 width 表示二维位置;
- 视频:temporal ID 随帧变化,height 和 width 表示每帧内的二维位置。
Qwen2.5-VL 的升级点是:Qwen2-VL 的 temporal IDs 主要 tied to input frames,而 Qwen2.5-VL 把 temporal component 对齐到 absolute time。也就是说,如果两个视频用不同 FPS 采样,只要真实时间一致,模型可以学习更一致的时间表示。
可以用一个小例子理解:
视频 A:每秒 1 帧,10 秒有 10 帧
视频 B:每秒 5 帧,10 秒有 50 帧
只看帧序号:第 10 帧在 A 中是 10 秒,在 B 中是 2 秒
看绝对时间:模型知道每帧对应真实时间,时间理解更稳定
3.4 预训练数据
论文将预训练数据从 Qwen2-VL 的 1.2T tokens 扩展到约 4.1T tokens。数据类型非常丰富:
- image captions;
- interleaved image-text data;
- OCR data;
- visual knowledge;
- multimodal academic questions;
- localization data;
- document parsing data;
- video descriptions;
- video localization;
- agent-based interaction data。
其中几个数据构造点值得细看。
Interleaved image-text data
图文交错数据的价值在于让模型学习图像和文本同时出现的上下文。论文强调用内部评估模型做四类打分:文本质量、图文相关性、图文互补性、信息密度平衡。这个设计说明大模型训练不是“数据越多越好”,而是要过滤掉图文弱相关、装饰性图片、低质量网页等噪声。
Grounding data
Qwen2.5-VL 使用实际图像尺寸中的坐标表示 boxes 和 points,并构造多格式 grounding 数据,包括 XML、JSON 和自定义格式。还使用 Grounding DINO、SAM 等工具合成数据,扩展到超过 10,000 个 object categories。
这里要注意:grounding 数据不只是“检测物体”,还要把自然语言描述和视觉区域对齐。比如“第二排左侧穿红衣服的人”比“person”更接近 LVLM 需要处理的语言条件定位。
Document omni-parsing data

文档数据是 Qwen2.5-VL 的重点。论文把文档中的段落、表格、图表、公式、图片说明、OCR、乐谱、化学式等都统一到 HTML 格式,并在标签中加入 bbox。这样模型不只是读文字,还能学习文档布局和结构。
这对多模态入门很关键:文档理解不是 OCR 的简单升级。OCR 主要读出文字;document parsing 要同时理解:
- 文字内容;
- 段落顺序;
- 表格结构;
- 图表数据;
- 公式和化学结构;
- 页面布局;
- 每个元素的位置。
Video data
视频数据强调不同 FPS 的鲁棒性、长视频 caption 和 video grounding。时间戳既包括秒级格式,也包括 hour-minute-second-frame 格式,使模型能处理更长时间尺度的视频定位。
Agent data
agent 数据包括移动端、网页端、桌面端截图,任务包括 UI caption、UI element grounding、多步操作轨迹和 function call 格式决策。论文还给每一步操作生成 reasoning content,用来解释操作意图,降低模型只记住 ground-truth 操作的风险。
3.5 训练流程
预训练分三阶段:
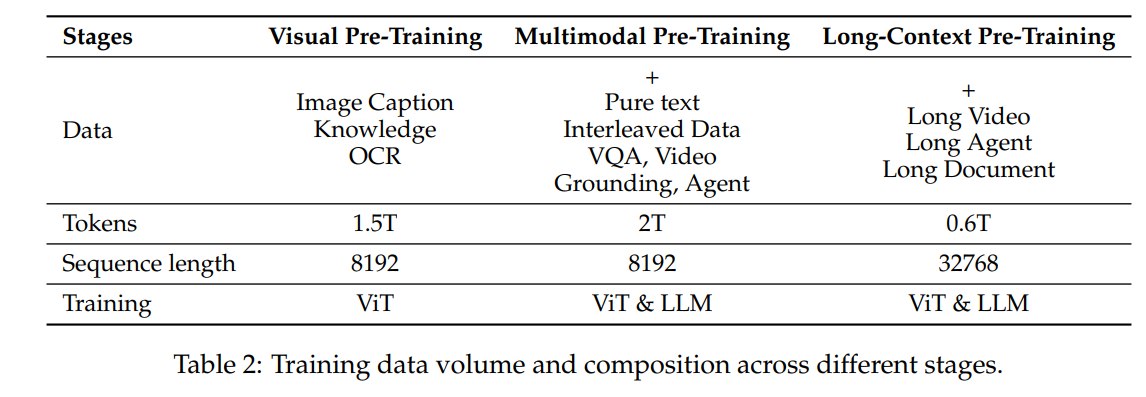
这个流程体现了从视觉基础、到通用多模态、再到长上下文任务的课程式训练思路。后训练包括 SFT 和 DPO,并且冻结 ViT。SFT 数据约 2M 条,纯文本和多模态各占 50%;DPO 使用 image-text 和 pure text preference data 做偏好对齐。
论文还使用数据过滤和 rejection sampling 增强推理能力。尤其在数学、代码、领域 VQA 等复杂任务中,会保留模型输出能匹配 ground truth 的高质量样本,并过滤 code-switching、过长、重复等不良输出。
四、实验
实验部分先比较 Qwen2.5-VL 与 Claude-3.5 Sonnet、GPT-4o、InternVL2.5、Qwen2-VL 等模型的总体表现,然后按能力拆分评测:
- college-level problems;
- math;
- general visual question answering;
- pure text tasks;
- document understanding and OCR;
- spatial understanding;
- video understanding and grounding;
- GUI agent。
整体上,Qwen2.5-VL-72B 在文档、OCR、图表、部分数学视觉推理、长视频理解、GUI grounding 和 agent 任务上表现突出。7B 和 3B 版本也在很多任务上具有较强竞争力。
4.1 总体 benchmark
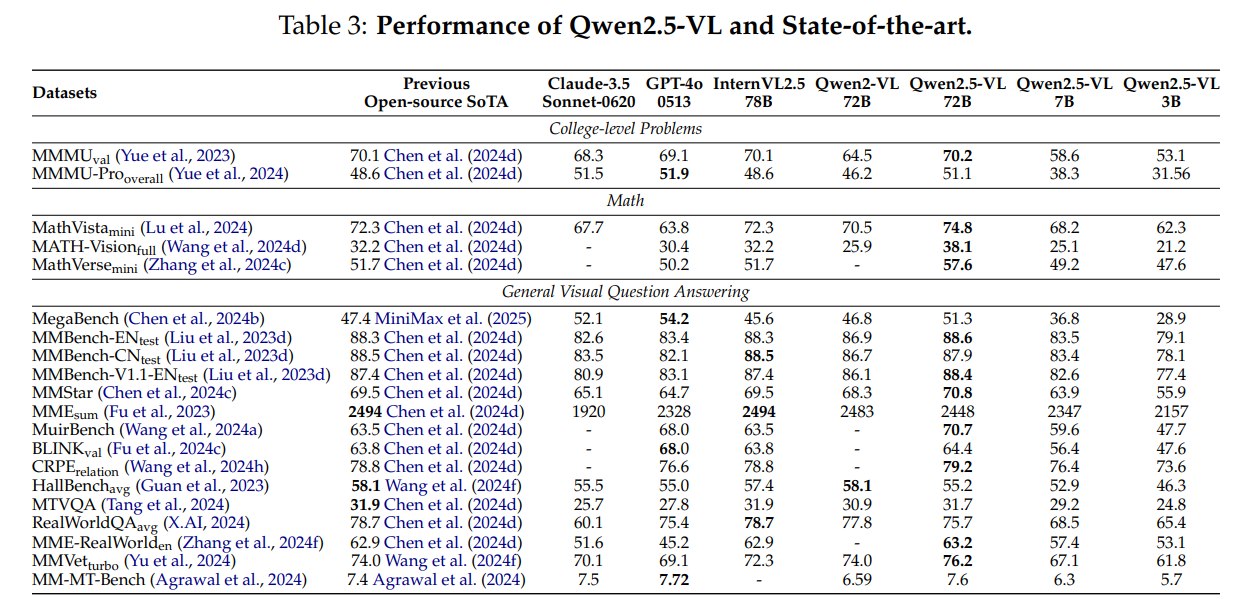
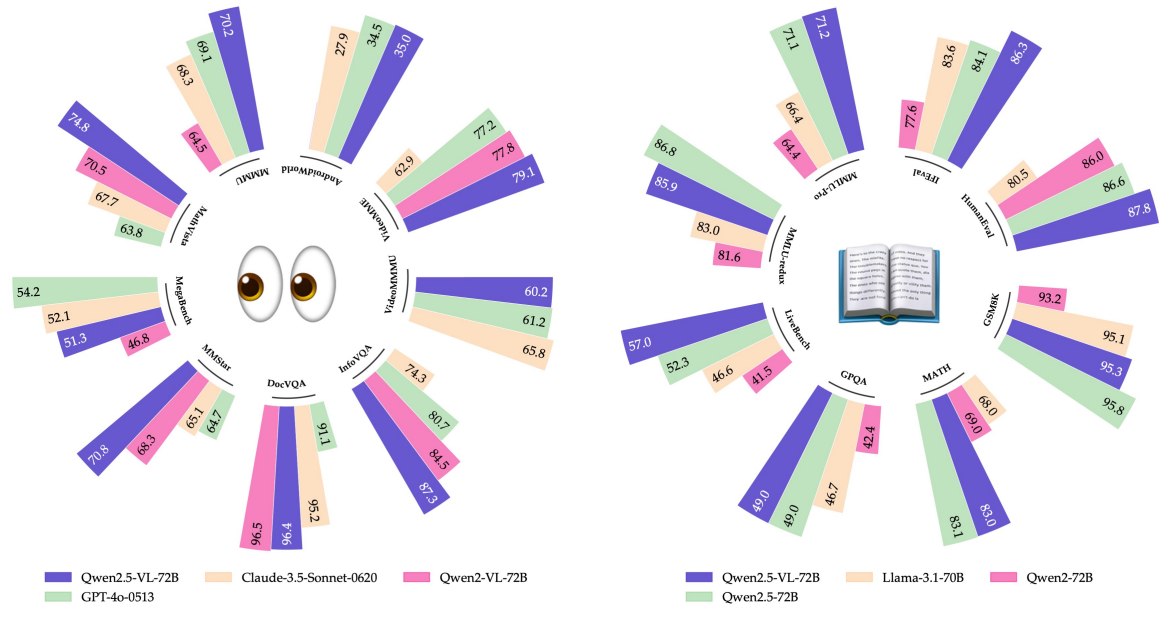
Qwen2.5-VL-72B 在 Table 3 中显示出多项强结果:
- MMMUval:70.2,接近 InternVL2.5-78B 的 70.1,并略高于 GPT-4o 的 69.1;
- MMMU-Prooverall:51.1,接近 GPT-4o 的 51.9 和 Claude-3.5 Sonnet 的 51.5;
- MathVistamini:74.8,高于表中 previous open-source SoTA 的 72.3;
- MATH-Visionfull:38.1,高于 GPT-4o 的 30.4;
- MathVersemini:57.6,高于 GPT-4o 的 50.2;
- MMVet:76.2,高于 Qwen2-VL-72B 的 74.0;
- MM-MT-Bench:7.6,接近 GPT-4o 的 7.72。
但也不是所有任务都领先。例如 MegaBench 上 GPT-4o 为 54.2,Qwen2.5-VL-72B 为 51.3;RealWorldQA 上 InternVL2.5-78B 为 78.7,Qwen2.5-VL-72B 为 75.7。阅读这类表格时要避免简单说“全面超越”,更准确的说法是:Qwen2.5-VL-72B 在多个关键多模态 benchmark 上达到开源前列,并在若干任务上接近或超过闭源模型。
4.2 纯文本任务
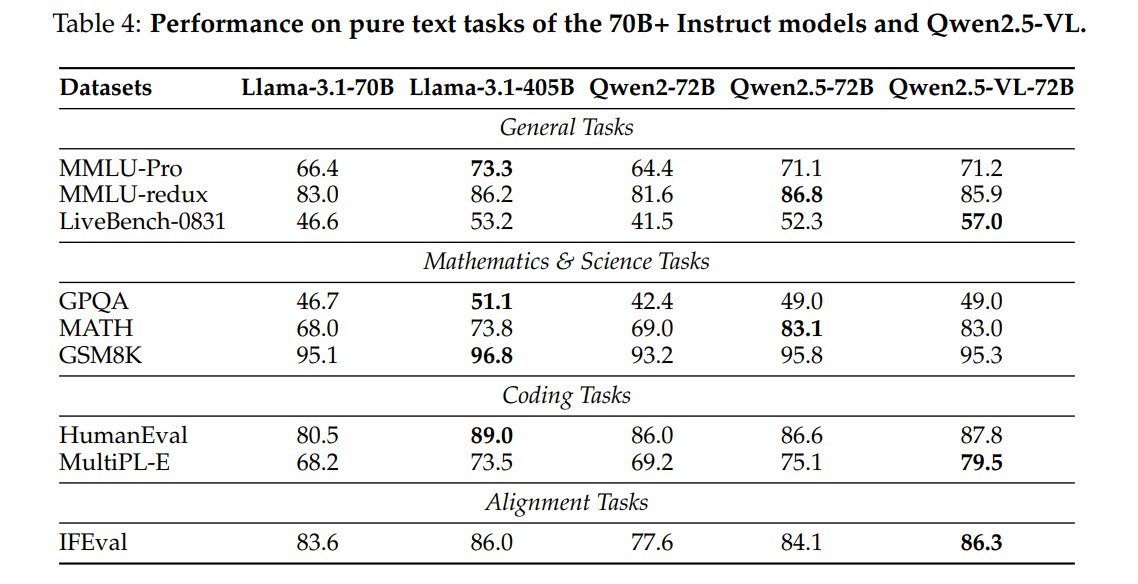
Table 4 很重要,因为多模态训练可能损伤语言能力。Qwen2.5-VL-72B 在纯文本任务上基本保持 Qwen2.5-72B 水平:
- MMLU-Pro:71.2,略高于 Qwen2.5-72B 的 71.1;
- MATH:83.0,接近 Qwen2.5-72B 的 83.1;
- HumanEval:87.8,高于 Qwen2.5-72B 的 86.6;
- MultiPL-E:79.5,高于 Qwen2.5-72B 的 75.1;
- IFEval:86.3,高于 Qwen2.5-72B 的 84.1。
这说明 Qwen2.5-VL 在引入视觉能力后,没有明显牺牲文本、数学、代码和指令跟随能力。对 LVLM 来说,这点很关键:如果语言底座退化,多模态推理也会受影响。
4.3 Document Understanding and OCR
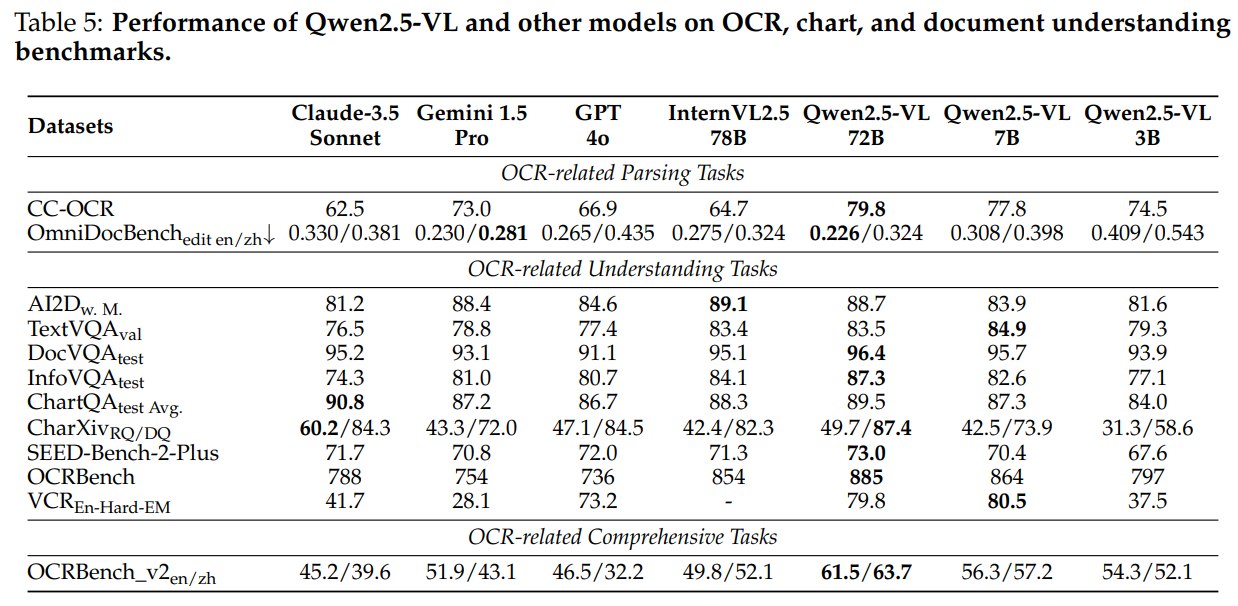
这是 Qwen2.5-VL 最强的实验板块之一。
在 OCR-related parsing tasks 中:
- CC-OCR:Qwen2.5-VL-72B 为 79.8,高于 Claude-3.5 Sonnet、Gemini 1.5 Pro、GPT-4o 和 InternVL2.5-78B;
- OmniDocBench edit en/zh 是越低越好,Qwen2.5-VL-72B 在英文上为 0.226,中文为 0.324,表现很强。
在 OCR-related understanding tasks 中:
- DocVQAtest:96.4;
- InfoVQAtest:87.3;
- OCRBench:885;
- OCRBench_v2 en/zh:61.5/63.7。
这些结果与方法部分的数据构造高度呼应。Qwen2.5-VL 并不只是“读字”,而是把文档元素统一为结构化 HTML,让模型学习布局、bbox、表格、图表、公式、乐谱、化学式等复杂元素。对文档任务来说,这比普通 caption 或 VQA 数据更贴近真实需求。
4.4 Spatial Understanding
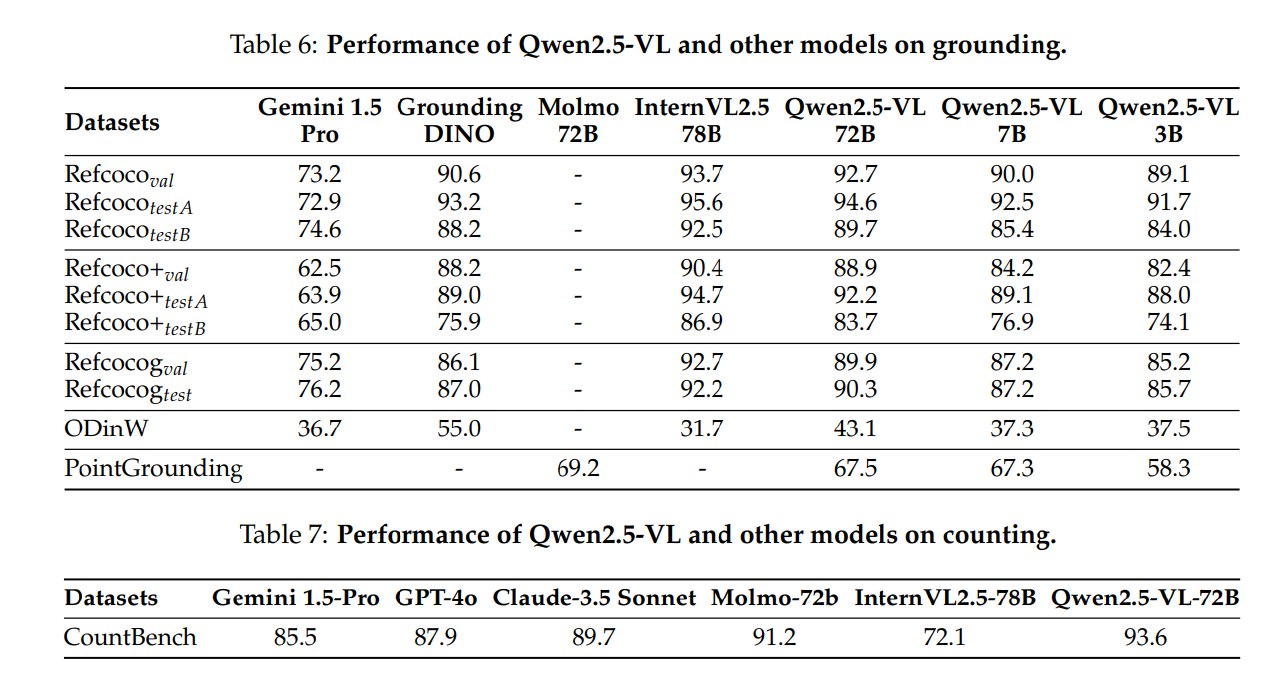
spatial understanding 包括 grounding、open-vocabulary detection、point grounding 和 counting。Table 6 和 Table 7 中:
- ODinW:Qwen2.5-VL-72B 为 43.1,高于 Gemini 1.5 Pro 的 36.7 和 InternVL2.5-78B 的 31.7,但低于 specialist model Grounding DINO 的 55.0;
- PointGrounding:Qwen2.5-VL-72B 为 67.5,接近 Molmo-72B 的 69.2;
- CountBench:Qwen2.5-VL-72B 为 93.6,高于 Gemini 1.5-Pro、GPT-4o、Claude-3.5 Sonnet、Molmo-72B 和 InternVL2.5-78B。
这里可以看到 generalist model 与 specialist model 的关系:Qwen2.5-VL 在开放词汇检测上接近专业检测模型,但仍未完全超过 Grounding DINO;然而它的优势是能把 grounding、语言理解、推理、输出格式和 agent 操作放在同一模型中。
4.5 Video Understanding and Grounding
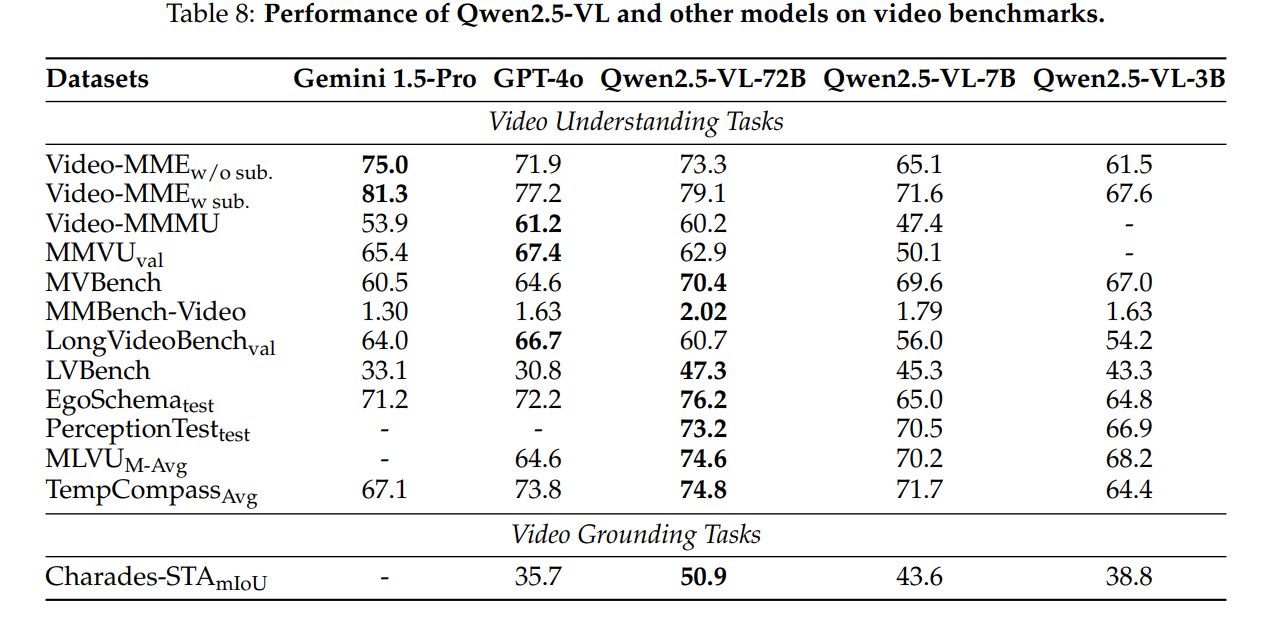
视频实验覆盖从短视频到小时级长视频的任务。Table 8 中:
- Video-MME without subtitles:Qwen2.5-VL-72B 为 73.3,低于 Gemini 1.5-Pro 的 75.0,但高于 GPT-4o 的 71.9;
- Video-MME with subtitles:79.1,低于 Gemini 1.5-Pro 的 81.3,高于 GPT-4o 的 77.2;
- MVBench:70.4,高于 Gemini 1.5-Pro 和 GPT-4o;
- LVBench:47.3,明显高于 Gemini 1.5-Pro 的 33.1 和 GPT-4o 的 30.8;
- EgoSchema:76.2,高于 GPT-4o 的 72.2;
- TempCompass:74.8,略高于 GPT-4o 的 73.8;
- Charades-STA mIoU:50.9,高于 GPT-4o 的 35.7。
这部分最能体现 absolute time MRoPE 的意义。Charades-STA 是 temporal grounding 任务,需要定位事件发生的时间段。Qwen2.5-VL 在该任务上明显高于 GPT-4o,说明时间对齐机制和视频 grounding 数据确实支撑了秒级事件定位能力。
不过论文也说明评测时每个视频最多分析 768 帧,总 video tokens 不超过 24,576。因此“理解小时级视频”并不等于模型无成本地处理完整原始视频,而是通过采样、token 预算和时间编码在长视频中做有效建模。
4.6 GUI Agent
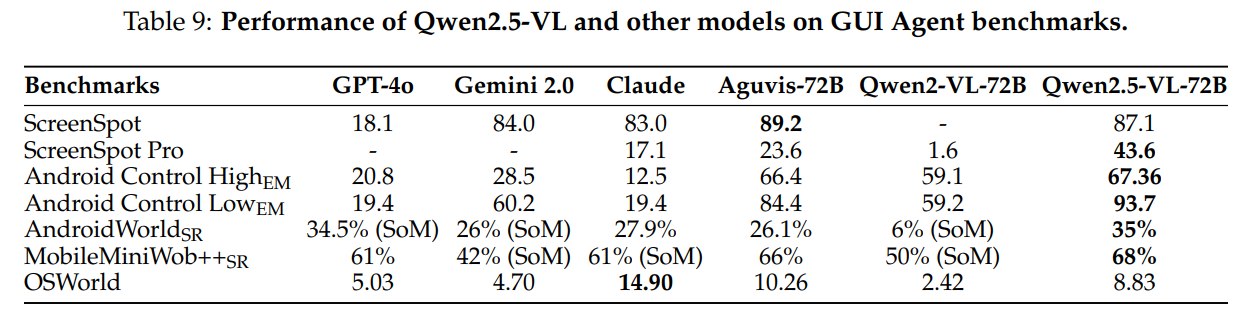
GUI agent 评测包括 ScreenSpot、ScreenSpot Pro、Android Control、AndroidWorld、MobileMiniWob++、OSWorld 等。
Qwen2.5-VL-72B 的结果包括:
- ScreenSpot:87.1;
- ScreenSpot Pro:43.6,远高于 Qwen2-VL-72B 的 1.6;
- Android Control HighEM:67.36;
- Android Control LowEM:93.7;
- AndroidWorld success rate:35%;
- MobileMiniWob++ success rate:68%;
- OSWorld:8.83。
ScreenSpot Pro 的巨大提升尤其值得注意,因为它说明 Qwen2.5-VL 的 GUI grounding 能力比上一代有明显跃升。Agent 能力不是单靠语言推理就能实现,它需要截图理解、UI 元素定位、操作格式统一、多步轨迹、以及对每一步动作意图的 reasoning 数据。
但 OSWorld 上 Claude 为 14.90,高于 Qwen2.5-VL-72B 的 8.83,说明真实桌面环境仍然困难。GUI agent 需要长期规划、状态追踪、错误恢复、工具调用和视觉定位协同,单次截图 grounding 强不代表完整 agent 已经成熟。
五、结论
报告的结论部分将 Qwen2.5-VL 总结为一个 state-of-the-art vision-language model series,强调它在视觉识别、object localization、document parsing、long-video comprehension、dynamic-resolution processing、absolute time encoding、Window Attention、纯文本能力保持、小模型效率和 real-world task execution 上的综合提升。
如果用一句话概括这篇报告:
Qwen2.5-VL 通过 native dynamic-resolution ViT、Window Attention、absolute-time-aligned MRoPE、大规模高质量多模态数据、长上下文训练和 SFT/DPO 后训练,把 Qwen-VL 系列从“通用视觉语言理解”进一步推向“细粒度感知 + 文档解析 + 视频定位 + GUI agent”的系统能力。

说些什么吧!