
零、写在前面
Qwen2-VL做了以下升级:动态分辨率、跨模态位置编码、视频统一建模和 scaling。
一、摘要
Qwen2-VL 被定义为 Qwen-VL 系列的升级版,核心目标是突破传统视觉处理中的固定分辨率范式。摘要中强调了三个主要技术点:
- Naive Dynamic Resolution:模型可以根据图像原始分辨率动态生成不同数量的 visual tokens,而不是把所有图像强制缩放到同一固定尺寸。
- Multimodal Rotary Position Embedding, M-RoPE:将位置信息扩展到文本、图像和视频之间,使模型能够更自然地融合跨模态的空间与时间信息。
- 统一图像与视频处理范式:论文将图像和视频纳入统一的视觉输入处理框架,以增强模型的视觉感知能力。
摘要还将 Qwen2-VL 放在 scaling 的语境下讨论:作者通过扩大模型规模和训练数据规模,推出不同尺寸版本(2B、8B、72B),并声称 Qwen2-VL-72B 在多种 multimodal benchmarks 上达到与 GPT-4o、Claude 3.5 Sonnet 等领先模型相近的表现。
摘要叙述了一个系统型 LVLM 升级:
| 贡献维度 | 摘要中的核心表述 | 研究意义 |
|---|---|---|
| 分辨率处理 | 动态处理不同分辨率图像 | 避免固定尺寸输入造成的细节损失,尤其利于文档、OCR、图表等高分辨率任务 |
| 位置编码 | M-RoPE 融合文本、图像、视频位置 | 将视觉空间和视频时间显式纳入 LLM 的位置建模 |
| 图像/视频统一 | 使用统一 paradigm 处理 images and videos | 减少把视频作为完全独立模态处理的割裂感 |
| scaling | 扩大模型与数据规模 | 将 LVLM 能力提升解释为架构、数据、参数规模共同作用 |
| 性能定位 | 72B 接近 GPT-4o / Claude 3.5 Sonnet | 将 Qwen2-VL 定位为强开源/open-weight 通用多模态模型 |
需要注意的是,源码中模型规模表述存在一个小不一致:摘要写到 2B、8B、72B,而正文表格和实验部分主要使用 2B、7B、72B。
二、引言
引言首先将 LVLM 描述为建立在 LLM 文本能力之上的多模态扩展。已有 LVLM 通常遵循 visual encoder -> cross-modal connector -> LLM 的基本范式,并结合 next-token prediction、高质量数据、更大模型、更高分辨率、MoE、模型集成和复杂 connector 等手段提升能力。
随后论文指出当前 LVLM 的几个关键瓶颈:
- 固定图像尺寸限制:很多模型将输入图像统一编码到固定分辨率,例如 224×224,或者通过缩放加 padding 的方式保持一致输入。这种做法便于计算,但会损失高分辨率图像中的细节。
- 冻结 CLIP-style vision encoder 的局限:静态、冻结的视觉编码器可能不足以支撑复杂推理和细粒度图像理解。作者认为在 LVLM 训练中 fine-tune ViT,并引入 dynamic resolution training,可以增强视觉适配能力。
- 视频建模需要时间和空间结构:视频不是简单的图像集合,而是包含时间动态的帧序列。传统一维位置编码难以充分表达图像二维空间与视频时间维度。
- LVLM scaling law 仍处早期:相比 LLM,视觉语言模型在模型规模与训练数据规模如何影响性能方面仍缺少系统探索。
在此基础上,引言列出 Qwen2-VL 的四项能力主张:
- 在不同分辨率和长宽比上达到 state-of-the-art understanding;
- 理解 20 分钟以上的 extended-duration videos;
- 具备面向设备操作的 visual agent 能力;
- 支持多语言图像文本理解,包括欧洲语言、日语、韩语、阿拉伯语、越南语等。
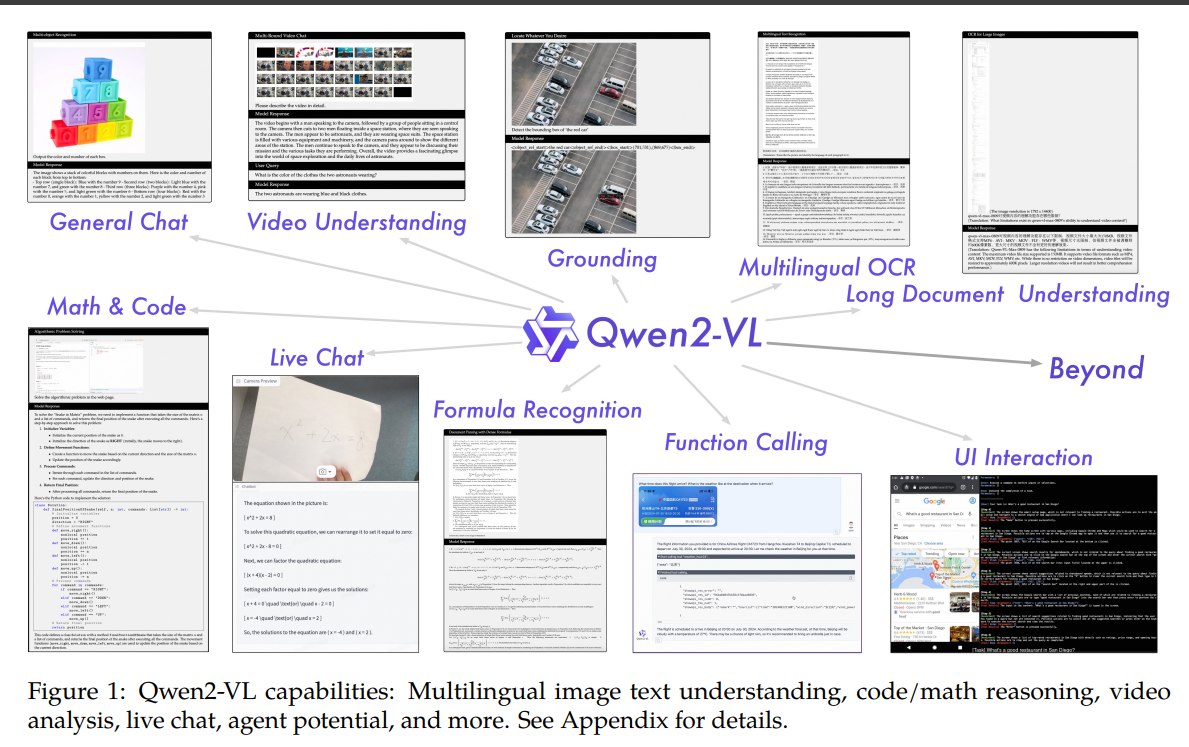
三、方法
3.1 模型架构
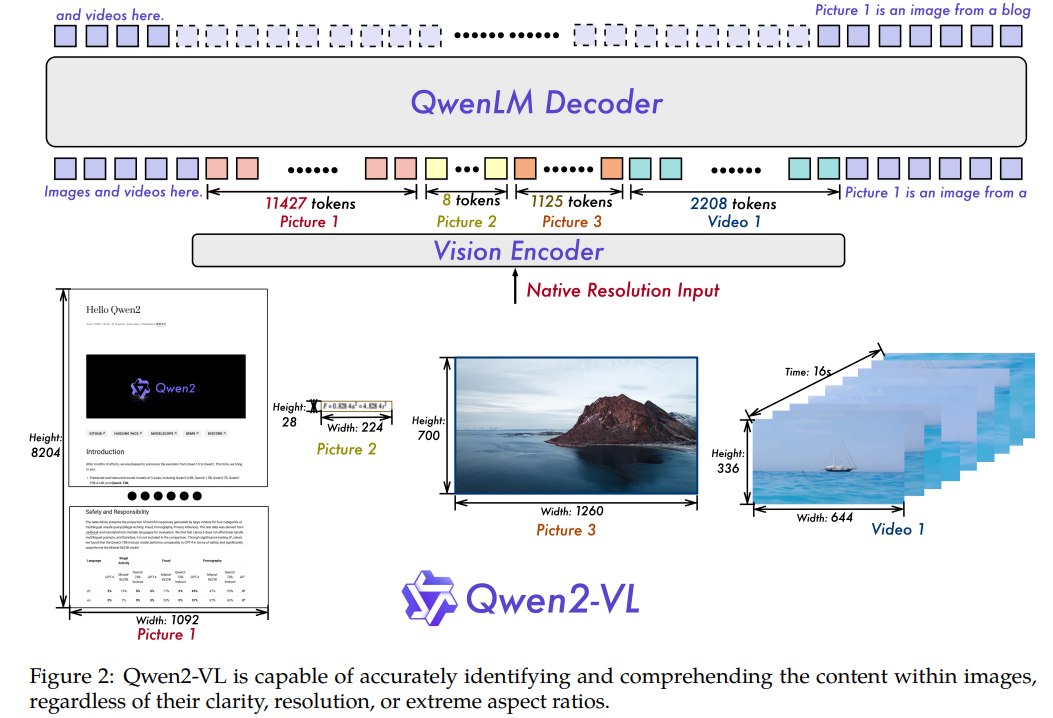
Qwen2-VL 系列包含 2B、7B、72B 三个主要版本。论文强调所有不同尺寸的 LLM 都使用约 675M 参数的 ViT,因此视觉编码器计算量不会随着语言模型规模线性增加。语言模型部分采用 Qwen2 系列。
架构升级主要包括三点。
第一,Naive Dynamic Resolution。 Qwen2-VL 不再将所有图像固定到统一尺寸,而是允许任意分辨率图像被动态转换为不同数量的 visual tokens。
具体来说,就是保持原图宽高比,然后resize,然后打成patch,和传统方法不同的是,传统方法的patch数目固定,Qwen2-VL允许不同分辨率图片的token数目不同。
为支持这一点,论文移除了 ViT 原本的 absolute position embeddings,并引入 2D-RoPE 来建模图像二维位置。
推理阶段,不同分辨率图像会被打包进同一序列,并通过控制 packed length 限制 GPU 显存。ViT 后接一个简单 MLP,将相邻 2×2 tokens 压缩为一个 token,并在视觉 token 前后加入 <|vision_start|> 和 <|vision_end|> 特殊标记。论文给出的例子是,224×224 图像在 patch_size=14 的 ViT 编码后,进入 LLM 前会被压缩为 66 个 tokens。
第二,M-RoPE。 与 LLM 中传统 1D-RoPE 不同,M-RoPE 将 rotary embedding 拆分成 temporal、height、width 三个部分。文本输入中三者使用相同 position IDs,因此退化为类似 1D-RoPE;图像输入中 temporal ID 保持常数,height 和 width 根据图像 token 的二维位置分配;视频输入中 temporal ID 随帧递增,height 和 width 仍按图像空间位置分配。论文还指出,M-RoPE 可以降低图像和视频的位置 ID 数值,从而增强长序列推理时的位置外推能力。
Q:MRoPE的具体实现细节是怎样的?
A:
首先要知道RoPE原理:Assignment1
具体来说,现在把embedding 看成 [T, H, W] 三段,然后在三段上分别做RoPE
这样做为什么合理?
假如把[3, 3, 3] 和 [3, 4, 3] 两个坐标分别做MRoPE,那么做完之后二者再求点积,我们发现因为旋转矩阵的转置就是其逆矩阵,那么做点积导致一个旋转矩阵乘另一个旋转矩阵的逆,这会引入二者的相对距离。

第三,统一图像与视频理解。 Qwen2-VL 在训练中混合图像和视频数据。视频按每秒 2 帧采样,并引入 depth 为 2 的 3D convolution,使模型处理 3D tubes 而不是纯 2D patches。为了统一形式,**每张图像被视为两个相同帧。**对于长视频,模型动态调整每帧分辨率,并将每个视频的总 token 数限制在 16,384,以平衡长视频理解能力和训练效率。
3.2 训练
Qwen2-VL 沿用 Qwen-VL 的三阶段训练方法:
- 第一阶段只训练 ViT,使用大规模 image-text pairs 增强 LLM 中的视觉语义理解。
- 第二阶段解冻所有参数,用更广泛的数据进行综合训练。
- 第三阶段锁定 ViT,只对 LLM 进行 instruction fine-tuning。
预训练数据包括 image-text pairs、OCR 数据、interleaved image-text articles、VQA 数据、video dialogues 和 image knowledge datasets。数据来源包括清洗后的网页、开源数据集和 synthetic data,知识截止日期为 2023 年 6 月。
论文披露的训练 token 规模较大:初始预训练阶段约 600B tokens,第二预训练阶段额外使用约 800B image-related tokens,总计约 1.4T tokens。需要注意,论文说明这些 tokens 包括 text tokens 和 image tokens,但训练过程中只对 text tokens 提供监督。
Instruction fine-tuning 阶段采用 ChatML 格式,数据不仅包含纯文本对话,也包含 image QA、document parsing、multi-image comparison、video comprehension、video stream dialogue 和 agent-based interactions。方法部分还定义了 visual grounding 的坐标格式和 special tokens,并将 UI operations、robotic control、games、navigation 等 visual agent 任务形式化为 sequential decision-making problems。
3.3 Multimodal Model Infrastructure
基础设施部分显示 Qwen2-VL 是一个强工程系统成果。训练使用 Alibaba Cloud PAI-Lingjun Intelligent Computing Service。存储上,文本数据放在 CPFS,并用 mmap 高效读取;视觉数据放在 OSS,通过 Python client 并发访问。论文特别指出 video data decoding 是长视频训练的主要瓶颈,因此采用 caching decoding 技术。
并行训练方面,论文使用 3D parallelism,即 data parallelism、tensor parallelism 和 pipeline parallelism 的组合;还使用 DeepSpeed ZeRO-1、sequence parallelism、selective activation checkpointing,以及 1F1B pipeline parallelism 训练 72B 模型。软件栈包括 PyTorch 2.1.2、CUDA 11.8、flash-attention 和若干 fused operators。
四、实验
实验部分先进行跨 benchmark 的 SoTA 对比,再分能力分析,包括 general visual question answering、document and diagrams reading、multilingual text recognition、mathematical reasoning、referring expression comprehension、video understanding 和 visual agent,最后用 ablation studies 分析 dynamic resolution、M-RoPE 和 model scaling。
4.1主要实验结果
4.1.1 综合 benchmark 对比
表格显示 Qwen2-VL-72B 在多项任务上非常强,尤其是文档、OCR、真实世界问答、多语言视觉文本和多模态综合评测。
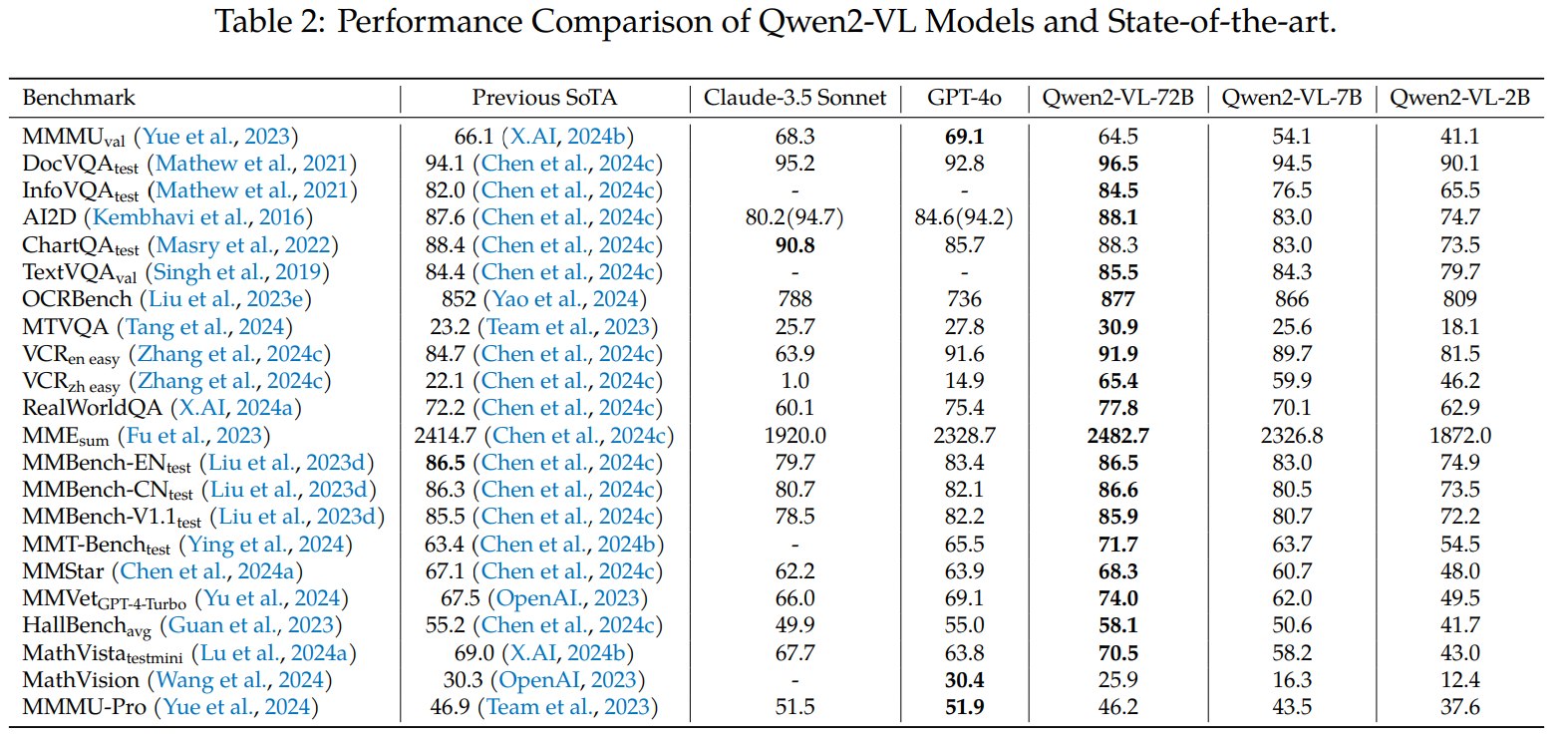
但表格也显示并非所有任务都领先。MMMU 上 Qwen2-VL-72B 为 64.5,低于 GPT-4o 的 69.1 和 Claude 3.5 Sonnet 的 68.3;MMMU-Pro 上 Qwen2-VL-72B 为 46.2,也低于 GPT-4o 和 Claude 3.5 Sonnet。论文作者也承认 MMMU 这类复杂问题集仍有提升空间。
4.1.2 文档、图表与 OCR
论文在 DocVQA、InfoVQA、ChartQA、TextVQA、AI2D 和 OCRBench 等任务上评估文档、图表和 OCR 能力。作者认为 Qwen2-VL 在 DocVQA、InfoVQA、TextVQA 和 OCRBench 等指标上达到 SoTA level。这与方法中的动态分辨率设计形成呼应:高分辨率视觉输入和可变 token 数更有利于保留小字、表格、图像局部结构和长宽比信息。

多语言 OCR 方面,Qwen2-VL-72B 在内部 benchmark 中超过 GPT-4o 的语言包括 Korean、Japanese、French、German、Italian、Russian、Vietnamese;但 Arabic 上 GPT-4o 为 75.9,高于 Qwen2-VL-72B 的 70.7。因此这里应写成“在多数内部多语言 OCR 语言上超过 GPT-4o”,而不是“所有语言都超过”。
4.1.3 数学与视觉推理
MathVista 和 MathVision 用于评估视觉数学推理。Qwen2-VL-72B 在 MathVista 上达到 70.5,但在 MathVision 表中并未超过 GPT-4o。论文也在 ablation 中指出,MMMU 的瓶颈可能更偏 reasoning capability,而不是图像分辨率。这一点很重要:动态分辨率可以改善视觉细节输入,但不能自动解决复杂符号推理、大学级知识推理或长链推理问题。
4.1.4 Referring Expression Comprehension
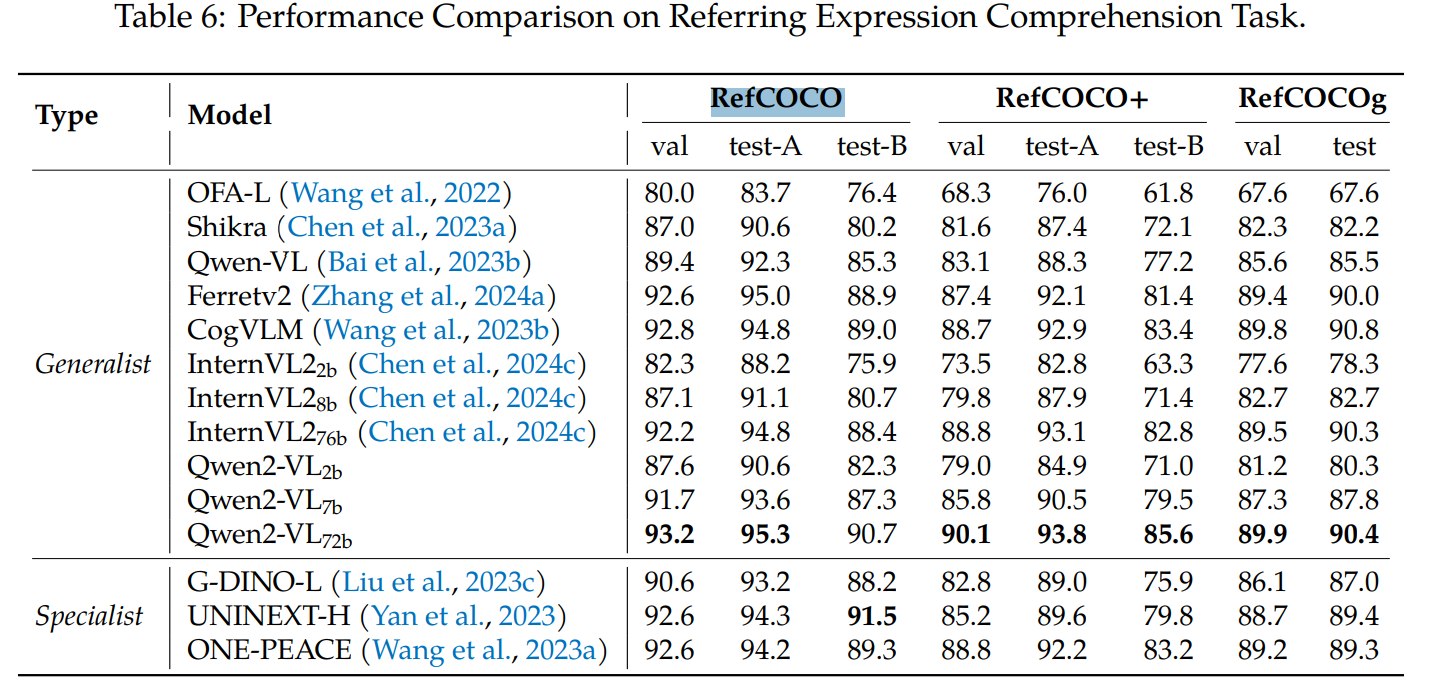
Qwen2-VL 在 RefCOCO、RefCOCO+、RefCOCOg 上表现接近或达到 generalist models 的 top-tier。论文将其归因于更合理的结构设计和高分辨率细节感知能力。这个实验支撑了 visual grounding 数据格式与动态分辨率的实际价值,尤其对后续 UI 操作、机器人控制等 agent 任务有间接意义。
4.1.5 Video Understanding

视频 benchmark 覆盖短视频到最长约一小时的视频。Qwen2-VL-72B 在 MVBench、PerceptionTest 和 EgoSchema 上表现强,在 EgoSchema 上达到 77.9,高于 GPT-4o 的 72.2 和 Gemini 1.5-Pro 的 63.2。但在 Video-MME 上,Gemini 1.5-Pro 的结果仍高于 Qwen2-VL-72B。论文还明确指出,Video-MME 评测时每个视频最多抽取 768 帧,这可能影响长视频性能,未来需要支持更长序列。
因此,Qwen2-VL 的视频能力可以概括为“强且具备长视频潜力”,但不能概括为“所有长视频 benchmark 最强”。
4.1.6 Visual Agent
Visual agent 实验分为 function calling、UI operations、card games、robotic control 和 navigation。Qwen2-VL-72B 在 function calling 的 Type Match 和 Exact Match 上超过 GPT-4o,在 AITZ UI 操作和多个 card game 任务中也表现突出。论文认为这与视觉 grounding、OCR 和决策能力有关。
但 navigation 是明显弱项:在 R2R 和 REVERIE 上,Qwen2-VL 与 GPT-4o 都明显落后于 specialized VLN models。论文将原因归结为模型从多张图像中生成的 map information 不完整且不结构化,说明 3D 环境地图建模仍是通用多模态模型的重要挑战。
4.2 消融实验
4.2.1 Dynamic Resolution
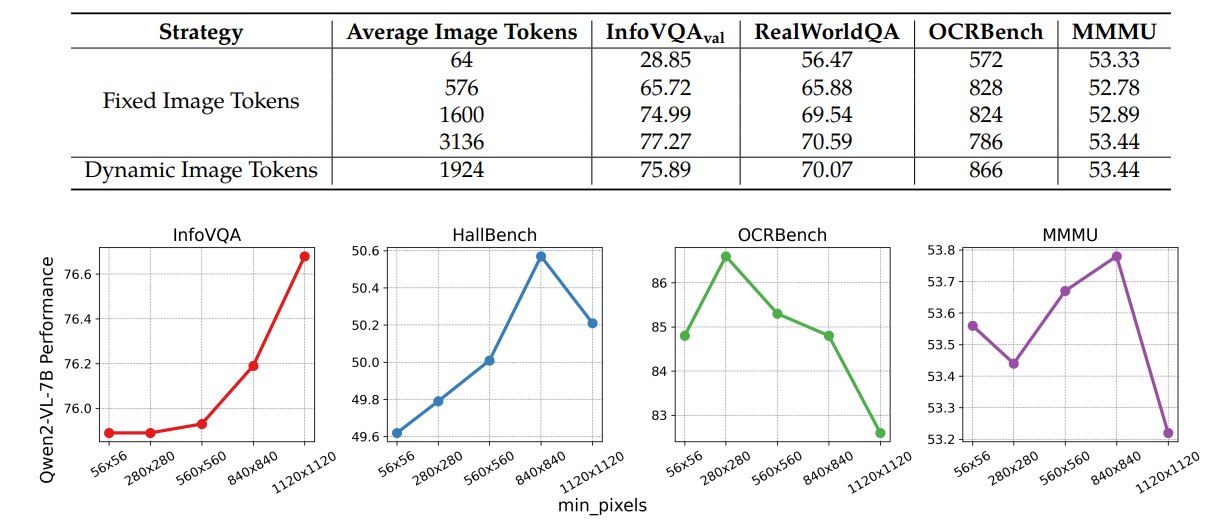
动态分辨率消融显示,固定 token 数策略没有一个配置能在所有 benchmark 上最优。Dynamic Image Tokens 平均使用 1924 image tokens,在多个任务上达到 top-tier,并比 3136 固定 tokens 更节省。论文进一步指出,简单增大图像尺寸不总是有益;在 OCRBench 中,过高的 min_pixels 反而会造成性能下降,可能因为极小图像被过度放大后偏离训练分布。
这个结果支持两个判断:
- 动态分辨率的价值不是“越大越好”,而是“按图像内容和原始分辨率分配合适 token 预算”。
- 分辨率策略对感知类任务更敏感,而对 MMMU 这类复杂推理任务影响较小。
4.2.2 M-RoPE
M-RoPE 消融中,相比 1D-RoPE,M-RoPE 在多个下游任务上更好,特别是视频 benchmark。论文还展示了长度外推能力:尽管训练时每个视频最大 token 数为 16K,Qwen2-VL-72B 在推理时最大到 80K tokens 仍保持较稳健表现。这直接支撑了 M-RoPE 的设计动机,即通过更合理的位置建模增强图像/视频长序列处理。
4.2.3 Model Scaling
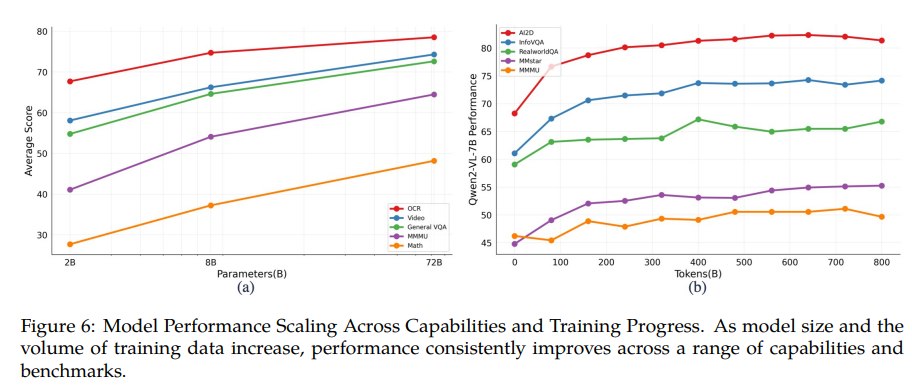
Scaling 分析显示,模型规模和训练数据增加通常会带来性能提升,数学能力与参数规模正相关较明显。OCR 相关任务则呈现另一个特点:小模型已经有相对强的表现。这提示多模态能力不是单一 scaling 曲线:OCR、文档解析、复杂数学推理、长视频理解对模型规模、视觉分辨率、训练数据和推理上下文的依赖程度不同。
五、结论
5.1 作者结论
论文结论将 Qwen2-VL 总结为包含 2B、7B、72B 三个 open-weight models 的通用 LVLM 系列。作者声称 Qwen2-VL 在多种 multimodal scenarios 中达到与 GPT-4o、Claude 3.5 Sonnet 等 top-tier models 相近的性能,并超过其他 open-weight LVLM models。结论再次强调两个核心技术:Naive Dynamic Resolution 和 M-RoPE;同时强调 20 分钟以上视频理解、视觉 agent 能力、多语言图像文本理解和开源权重对研究与应用的意义。
5.2 总结
Qwen2-VL 的核心价值可以概括为:用动态视觉 token 机制和多模态位置编码,配合大规模训练数据、统一图像/视频处理和强工程基础设施,构建一个能力覆盖面很广的 open-weight LVLM 系列。
从论文结构看,Qwen2-VL 的贡献不是某个孤立模块,而是一个系统组合:
- 动态分辨率提升对不同尺寸、长宽比和高分辨率细节的适应;
- M-RoPE 提供文本、图像、视频统一但结构敏感的位置建模;
- 三阶段训练与大规模混合数据支撑 OCR、文档、视频、agent 等多能力形成;
- 基础设施解决动态序列、长视频、并行训练和大模型训练效率问题;
- 广泛实验展示其作为通用 open-weight LVLM 的竞争力。

说些什么吧!