
零、写在前面
之前手搓过GPT-2(LLMs-From-Scratch),然后一时兴起想梳理一下GPT1~3的技术路线。
一、背景:从 Transformer 到自回归语言模型
GPT 系列建立在 Transformer 之上。Transformer 最初由 Vaswani et al. 在 Attention Is All You Need 中提出,其核心是用 self-attention 取代 RNN/CNN 中的序列建模机制,使模型能够并行处理 token,并通过 attention 直接建模长距离依赖。
GPT 使用的是 decoder-only Transformer:
- 只保留 Transformer decoder 风格的单向结构;
- 使用 causal mask,当前位置只能看到当前位置及其之前的 token;
- 训练目标是 autoregressive language modeling,即根据前文预测下一个 token。
形式上,给定 token 序列 $u = (u_1, u_2, \dots, u_n)$,语言模型最大化:
$$ \sum_i \log P(u_i \mid u_1, \dots, u_{i-1}; \theta) $$这个目标非常简单,但 GPT-1 到 GPT-3 的核心发现是:当数据、模型容量和计算规模持续扩大时,单纯的 next-token prediction 可以学到大量可迁移的语言知识、世界知识和任务模式。
二、GPT-1:Generative Pre-Training + Supervised Fine-Tuning
2.1 标题
Improving Language Understanding by Generative Pre-Training
通过大规模预训练来提升语言理解。
论文本身并没有给GPT起名字,大家拿Generative Pre-Training的首字母起了GPT这个名字。好在后续GPT工作的持续跟进,爆火出圈,使得GPT这个名字可以说是家喻户晓了。
- 时间:2018
- 最大模型规模:约 117M 参数
- 训练数据:BooksCorpus
- 关键范式:无监督生成式预训练 + 有监督下游微调
2.2 核心问题
GPT-1 面对的问题是:当时很多 NLP 任务都依赖任务特定的监督数据和模型结构,迁移能力有限。GPT-1 的目标是先用大规模无标注文本训练一个通用语言表示,再用少量有标注数据微调到具体任务。
这形成了后来非常重要的两阶段范式:
- Unsupervised pre-training:在 BooksCorpus 上训练自回归语言模型。
- Supervised fine-tuning:把下游任务改写成统一的 token 序列输入,再继续训练模型完成分类、问答、自然语言推理等任务。
2.3 architecture
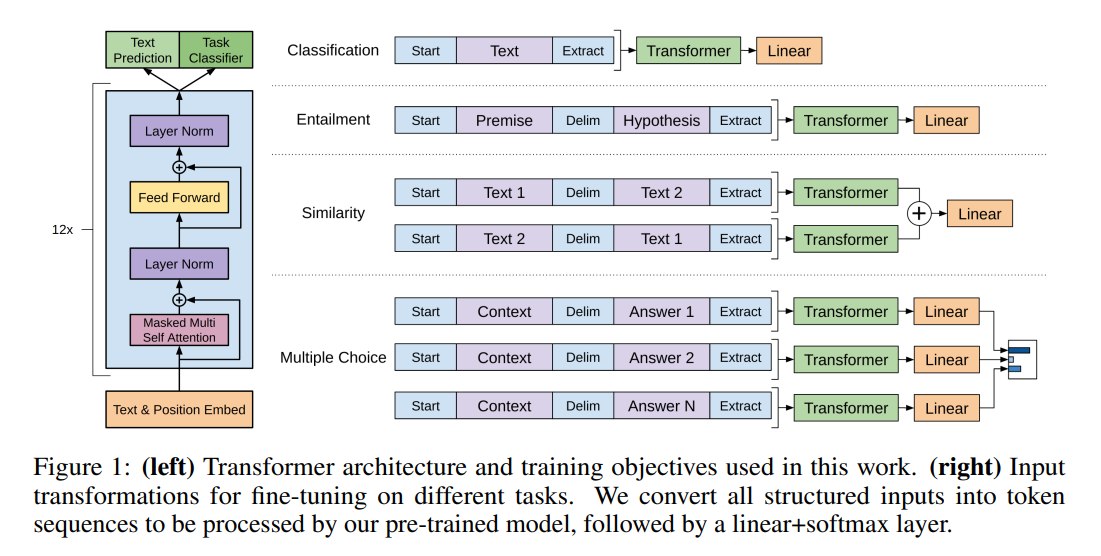
注意这个地方是 post-norm
GPT-1 使用 12 层 Transformer decoder:
- masked multi-head self-attention;
- position-wise feed-forward network;
- learned positional embeddings;
- Byte Pair Encoding tokenization;
- 单向语言模型目标。
从今天的视角看,GPT-1 的结构并不复杂,真正重要的是它证明了 decoder-only 生成式预训练也能迁移到语言理解任务。这点很关键,因为同一时期的很多工作更强调 task-specific architecture,后来的 BERT 则走向 encoder-only masked language modeling 路线。
2.4 下游任务适配方式
GPT-1 把不同 NLP 任务统一改写为序列输入。例如:
- 文本分类:
[text] -> label - 自然语言推理:
[premise] [delimiter] [hypothesis] -> label - 多选问答:把每个候选答案分别拼接到上下文后打分
这种做法的意义是:尽量减少任务特定结构,让同一个预训练模型通过输入格式适配不同任务。
2.5 技术贡献与局限
贡献:
- 建立了 “pre-training + fine-tuning” 的 GPT 路线;
- 证明生成式语言模型可以服务于语言理解任务;
- 将无标注文本中的知识迁移到多个有监督 benchmark。
局限:
- 仍然强依赖下游监督 fine-tuning;
- 模型和数据规模有限;
- 对任务的泛化主要来自微调,而不是自然语言 prompt 或上下文学习。
三、GPT-2:Language Models are Unsupervised Multitask Learners
3.1 标题
Language Models are Unsupervised Multitask Learners
- 时间:2019
- 最大模型规模:1.5B 参数
- 训练数据:WebText
- 关键范式:大规模自回归语言模型 + zero-shot task transfer
3.2 核心问题
GPT-2 的核心主张是:如果语言模型足够大,训练文本足够丰富,那么模型可以在不进行下游梯度更新的情况下,通过自然语言上下文完成多种任务。
这就是 zero-shot task transfer:
- 不为目标任务单独 fine-tune;
- 只通过上下文、任务描述、问题格式或 prompt 引导模型输出答案;
- 模型在预训练阶段通过互联网文本中的自然任务格式间接学会任务模式。
这里其实是比较取巧的,因为18年的BERT在论文中把GPT1吊打了一遍,GPT2 这次采用更大的参数、更大的数据自然会取得更好的效果,但这再去和BERT会发现其实优势并不大。所以作者就把 Zero-shot 作为文章的卖点。
关于作者转用Zero-shot 作为卖点,沐神的点评:“做研究不要一条路走到黑”。
做过程你可以一条路走到黑,但是在做研究的时候,你要灵活一些,不要一条路走到黑。你需要尝试从一个新的角度来看问题。 gpt2还是做语言模型,但是在做到下游任务的时候,会用一个叫做zero-shot的设定,zero-shot是说,在做到下游任务的时候,不需要下游任务的任何标注信息,那么也不需要去重新训练已经预训练好的模型。这样子的好处是我只要训练好一个模型,在任何地方都可以用。 如果作者就是在gpt1的基础上用一个更大的数据集训练一个更大的模型,说我的结果比Bert好一些,可能也就好那么一点点,不是好那么多的情况下,大家会觉得gpt2这篇文章就没什么意思了,工程味特别重。那么我换一个角度,选择一个更难的问题,我说做zero-shot。虽然结果可能没那么厉害了,没那么有优势,但是新意度一下就来了。
3.3 数据与规模
GPT-2 使用 WebText 数据集,来源是 Reddit 上高 karma 外链指向的网页文本。OpenAI 官方介绍中称 GPT-2 是一个 1.5B 参数 Transformer language model,训练于约 8 million web pages。
相比 GPT-1,GPT-2 的关键变化是规模:
| 项目 | GPT-1 | GPT-2 |
|---|---|---|
| 最大参数量 | 117M | 1.5B |
| 上下文长度 | 512 tokens | 1024 tokens |
| 主要数据 | BooksCorpus | WebText |
| 下游适配 | fine-tuning | zero-shot prompting |
3.4 模型结构变化
GPT-2 仍是 decoder-only Transformer,但相比 GPT-1 做了工程层面的调整:
- 扩大层数、hidden size、attention heads;
- 使用更长上下文窗口;
- 调整 LayerNorm 位置(pre-norm);
- 使用更大规模、更开放领域的数据。
GPT-2 的核心创新不是提出全新结构,而是强调 同一个语言建模目标在更大规模下可以表现出任务迁移能力。
3.5 Zero-shot 能力
GPT-2 展示了模型在以下任务上的 zero-shot 行为:
- language modeling;
- question answering;
- summarization;
- translation;
- reading comprehension;
- commonsense reasoning。
这里的 zero-shot 并不意味着模型真的“理解”了所有任务,而是说明模型能从上下文格式中推断出某种输入输出模式。例如,给出一段英文文本和 “TL;DR:” 这样的提示,模型可能生成摘要;给出翻译格式,模型可能生成目标语言句子。
3.6 技术贡献与局限
贡献:
- 将 GPT 路线从 “pre-train + fine-tune” 推向 “pre-train + prompt”;
- 证明语言模型规模扩大后会出现更明显的跨任务迁移;
- 强化了互联网规模文本作为通用训练数据的价值。
局限:
- zero-shot 性能不稳定,很多任务仍显著落后于 supervised fine-tuning;
- 输出可能存在事实错误、重复、偏见和有害内容;
- WebText 数据不可完全复现;
- 长文本一致性和可控性仍然有限。
四、GPT-3:Language Models are Few-Shot Learners
4.1 标题
Language Models are Few-Shot Learners
- 时间:2020,NeurIPS 2020
- 最大模型规模:175B 参数
- 训练数据:Common Crawl、WebText2、Books1、Books2、Wikipedia 等混合语料
- 关键范式:scaling + in-context learning + few-shot prompting
4.2 核心问题
GPT-3 进一步追问:如果继续扩大模型、数据和计算,语言模型能否在没有参数更新的情况下,只根据 prompt 中的少量示例完成任务?
GPT-3 的答案是:可以在大量任务上显著提升,但能力并不均匀,也不等价于可靠理解。
GPT-3 论文重点评估三种设置:
- Zero-shot:只给任务描述,不给示例。
- One-shot:给一个输入输出示例。
- Few-shot:在上下文中给少量示例,但不更新模型参数。
这类能力后来通常称为 in-context learning:模型通过 prompt 中的上下文示例临时推断任务模式,而不是通过 fine-tuning 修改参数。
4.3 模型与训练
GPT-3 仍然是 autoregressive decoder-only Transformer(架构和GPT-2一样)。它的核心不是结构革命,而是规模化:
- 最大模型达到 175B 参数;
- 上下文长度扩展到 2048 tokens;
- 训练目标仍是 next-token prediction;
- 不针对每个下游任务进行梯度更新。
GPT-3 论文报告了一系列不同规模的模型,从 125M 到 175B,用于观察 scaling 对性能的影响。
| 模型 | 参数量 |
|---|---|
| GPT-3 Small | 125M |
| GPT-3 Medium | 350M |
| GPT-3 Large | 760M |
| GPT-3 XL | 1.3B |
| GPT-3 2.7B | 2.7B |
| GPT-3 6.7B | 6.7B |
| GPT-3 13B | 13B |
| GPT-3 | 175B |
4.4 数据组成
GPT-3 使用多个语料来源,包括:
- filtered Common Crawl;
- WebText2;
- Books1;
- Books2;
- English-language Wikipedia。
其中 Common Crawl 提供了最大规模的开放网页文本,其他数据源用于提升质量和覆盖面。GPT-3 的训练不只是“堆更多网页”,还包括过滤、去重和混合采样权重等数据工程。
4.5 Few-shot Prompting
GPT-3 的 few-shot prompting 可以理解为把训练样例直接写进上下文。例如情感分类:
Sentence: The movie was surprisingly thoughtful and moving.
Sentiment: Positive
Sentence: The plot was dull and the acting was weak.
Sentiment: Negative
Sentence: The ending was predictable but still enjoyable.
Sentiment:
模型不更新参数,而是根据前两个示例推断第三个样本的输出格式和任务含义。
这与 GPT-1 的 fine-tuning 有本质差别:
- GPT-1:任务知识通过梯度更新写入参数;
- GPT-3:任务模式通过上下文临时提供,参数保持不变。
4.6 实验结果与能力边界
GPT-3 在多类任务上展示了明显的 few-shot 能力:
- language modeling;
- closed-book question answering;
- translation;
- reading comprehension;
- commonsense reasoning;
- natural language inference;
- arithmetic and symbolic tasks;
- cloze and completion-style tasks。
但 GPT-3 的结果也说明:scale 不是万能的。
- 有些任务随规模平滑提升;
- 有些任务需要特定格式的 prompt;
- 算术、组合泛化、事实一致性仍然不可靠;
- 模型可能生成自信但错误的答案;
- 偏见、有害输出和数据污染问题更难忽视。
4.7 技术贡献与局限
贡献:
- 将 GPT 路线明确推向 scaling law 和 emergent prompting behavior;
- 系统展示 zero-shot、one-shot、few-shot 三种评估方式;
- 让 in-context learning 成为大语言模型交互范式;
- 证明更大的通用语言模型可以减少对任务特定 fine-tuning 的依赖。
局限:
- 训练和推理成本极高;
- 输出不可控,容易 hallucination;
- 对 prompt 格式敏感;
- 可能复现训练数据中的社会偏见;
- 缺乏透明的可解释机制;
- 少样本能力并不代表真正稳健的任务理解。
五、总结
5.1 GPT-1 / GPT-2 / GPT-3 横向对比
| 维度 | GPT-1 | GPT-2 | GPT-3 |
|---|---|---|---|
| 论文 | Improving Language Understanding by Generative Pre-Training | Language Models are Unsupervised Multitask Learners | Language Models are Few-Shot Learners |
| 时间 | 2018 | 2019 | 2020 |
| 最大参数量 | 117M | 1.5B | 175B |
| 架构 | Decoder-only Transformer | Decoder-only Transformer | Decoder-only Transformer |
| 训练目标 | 自回归 next-token prediction | 自回归 next-token prediction | 自回归 next-token prediction |
| 主要数据 | BooksCorpus | WebText | Common Crawl、WebText2、Books、Wikipedia |
| 上下文长度 | 512 tokens | 1024 tokens | 2048 tokens |
| 下游适配 | Supervised fine-tuning | Zero-shot prompting | Zero-shot / one-shot / few-shot prompting |
| 核心贡献 | 生成式预训练迁移到理解任务 | 大规模 LM 出现无监督多任务迁移 | 规模化带来上下文学习和少样本能力 |
| 主要局限 | 依赖有监督微调 | zero-shot 不稳定 | 成本高、偏见、幻觉、prompt 敏感 |
5.2 技术演进主线
GPT-1 到 GPT-3 的演进可以概括为四条主线。
1、架构主线:少变结构,多扩规模
三代 GPT 都坚持 decoder-only Transformer。它们没有像很多模型那样频繁更换结构,而是持续扩大模型、数据和计算。这说明 GPT 路线的重点不是复杂架构设计,而是验证一个简单目标在大规模下的上限。
2、目标函数主线:next-token prediction 足够通用
从 GPT-1 到 GPT-3,训练目标始终是预测下一个 token。这个目标看似只是语言建模,但因为自然语言中包含知识、推理、任务描述、问答、翻译、代码和格式化文本,模型在压缩文本分布时会间接学习大量任务规律。
3、适配范式主线:fine-tuning → prompting → in-context learning
| 阶段 | 代表模型 | 适配方式 | 参数是否更新 |
|---|---|---|---|
| 预训练 + 微调 | GPT-1 | 下游 supervised fine-tuning | 更新 |
| 零样本提示 | GPT-2 | prompt / natural language context | 不更新 |
| 上下文学习 | GPT-3 | few-shot examples in prompt | 不更新 |
这个变化非常重要:模型从“为每个任务训练一次”逐渐走向“用自然语言描述任务”。这也是后续 instruction tuning、prompt engineering、agent workflow 的基础。
4、能力主线:从迁移表示到通用接口
GPT-1 更像一个强大的预训练初始化;GPT-2 开始表现出任务接口的雏形;GPT-3 则把自然语言上下文变成了通用任务接口。
因此,GPT-3 的意义不只是模型更大,而是它改变了人和模型交互的方式:用户不一定需要准备训练集和训练流程,可以先通过 prompt 直接表达任务。
5.3 与 BERT 路线的简要对比
GPT 与 BERT 都属于预训练语言模型,但路线不同:
| 维度 | GPT 系列 | BERT |
|---|---|---|
| 结构 | Decoder-only | Encoder-only |
| 注意力方向 | 单向 causal attention | 双向 self-attention |
| 训练目标 | Next-token prediction | Masked language modeling + NSP |
| 更自然的任务 | 生成、补全、prompting | 分类、匹配、抽取式理解 |
| 典型适配 | fine-tuning / prompting | fine-tuning |
GPT 路线的优势是生成自然,能够直接建模文本续写;BERT 路线的优势是双向编码,适合许多判别式理解任务。GPT-3 之后,decoder-only 结构因为与生成式交互天然匹配,成为大语言模型的主流基础结构之一。
5.4 局限性
GPT-1 到 GPT-3 共同暴露出一些问题:
- 事实可靠性不足:模型优化的是文本概率,不是真实性。
- 可控性有限:生成内容受 prompt、采样参数和训练分布影响。
- 偏见与安全问题:大规模网页语料会引入社会偏见、有害内容和隐私风险。
- 评估困难:benchmark 分数不能完全代表真实应用可靠性。
- 计算成本高:GPT-3 级别模型的训练门槛极高。
- 数据污染风险:互联网训练语料可能包含测试集或相似内容。
5.5 后续影响
GPT-3 之后,大语言模型研究沿着几条方向继续发展:
- Instruction tuning:让模型更好地遵循自然语言指令。
- RLHF:用人类偏好优化输出质量和安全性。
- Tool use / agents:让语言模型调用工具、检索资料、执行多步任务。
- Retrieval-Augmented Generation:用外部知识缓解 hallucination。
- Efficient fine-tuning:用 LoRA、prefix tuning 等方式降低适配成本。
这些方向并不是 GPT-1/2/3 的组成部分,但都建立在 GPT 系列展示出的通用语言建模能力之上。

说些什么吧!