
零、写在前面
这篇主要就是在 LLaVA 框架下,通过少量但关键的设计改动,可以得到一个更强、更简单、数据效率更高的 Large Multimodal Model baseline,即 LLaVA-1.5。
一、摘要
Abstract 针对 LMM 研究中的一个关键问题:现有方法越来越复杂,训练数据和算力规模越来越大,但哪些设计因素真正重要并不清楚。作者希望在 LLaVA 框架内做 controlled study,澄清 input、model、data 这些维度的改动如何影响最终能力。
摘要直接指出了在LLaVA框架内做的三点改动:
- 更高分辨率的视觉编码器:使用
CLIP-ViT-L-336px,让模型能够看到更多图像细节。 - 更强的 vision-language connector:将原始 LLaVA 的 linear projection 换成 two-layer MLP projection,增强跨模态对齐模块的表达能力。
- 加入 academic-task-oriented VQA data,并使用 response formatting prompts:在 VQA、OCR、region-level perception 等任务数据中加入明确的回答格式提示,例如 “Answer the question using a single word or phrase.”,以避免模型在 short-form answer 和 natural conversation 之间失衡。
作者在摘要中给出两个结果:
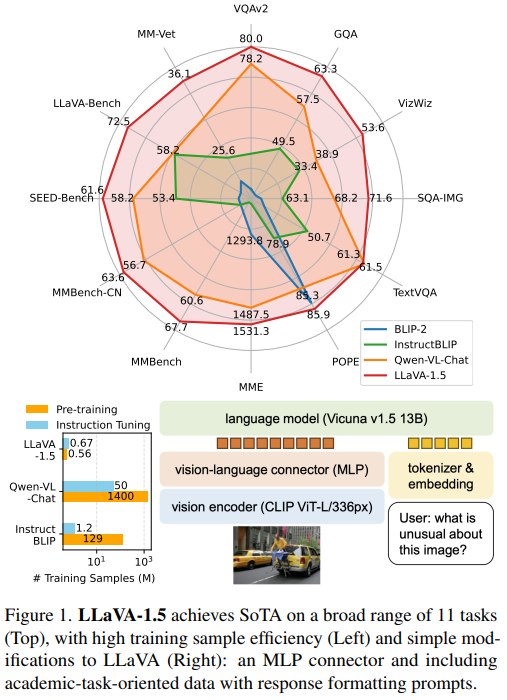
- LLaVA-1.5 在 11 个 benchmarks 上达到 state-of-the-art。
- 最终 13B checkpoint 只使用约 1.2M publicly available data,并能在单个 8-A100 node 上约 1 天完成完整训练。
二、引言
Introduction 的核心论点是:visual instruction tuning 已经成为构建 general-purpose multimodal assistant 的关键路径,但社区仍然缺乏对 LMM 训练 recipe 的系统理解。
LLaVA-1.5 的目标是通过 controlled study 找到更简单、更有效、更可复现的 baseline。
作者指出,LMM 社区已经出现了很多模型和 benchmarks,但不同模型能力差异的根因并不清楚。例如:
- LLaVA 在 conversational-style visual reasoning 和 real-life visual instruction-following tasks 上表现强。
- InstructBLIP 在传统 VQA benchmarks 上更强,尤其是需要 single-word 或 short answer 的任务。
问题在于,这两个系统在 architecture、pretraining data、instruction data、trainable components 等方面差异很大,因此很难判断性能差异来自哪里:是数据规模、Qformer/visual resampler、LLM finetuning,还是 prompt/data mixture 的问题?
Introduction 提出了三个研究维度:
- Input:提高图像输入分辨率,使模型能够处理更细粒度的视觉信息。
- Model:重新评估 LLaVA 中极简 fully-connected vision-language connector 的能力,并将 linear connector 扩展为 MLP connector。
- Data:在 visual instruction tuning 中加入 academic-task-oriented data,同时用 response formatting prompts 约束输出形式。
作者强调,LLaVA 的简单设计本身很有价值:相比 InstructBLIP 和 Qwen-VL 这类使用 specially designed visual resamplers、并在上亿甚至十亿级 image-text pairs 上训练的模型,LLaVA 只需要在约 600K image-text pairs 上训练一个简单 projection layer,就能形成有效的 cross-modal alignment。
Introduction 中给出的主要证据包括:
- LLaVA-1.5 使用公开数据,不依赖 Qwen-VL 这类 in-house data。
- 最终模型在 broad range of 11 tasks 上达到 state-of-the-art。
- 训练成本约为单台 8-A100 机器 1 天。
- 通过高分辨率输入,模型 detailed perception 能力提升,并且 hallucination 下降。
- 随机下采样训练数据至较低比例时,性能没有显著下降,说明仍有进一步 dataset compression 或 data efficiency 优化空间。
Introduction 把论文定位为 “baseline paper” 而不是单纯的 “new model paper”。它的贡献不只在于 LLaVA-1.5 本身性能强,还在于给出一种可复现、可 ablate、可扩展的 LMM 研究基线。
三、相关工作
这部分回答两个背景问题:
- 当前 instruction-following LMM 的常见架构是什么?
- 为什么 multimodal instruction-following data 的组织方式会显著影响模型能力?
LMM architecture
常见 instruction-following LMM 通常包含三个核心组件:
- pre-trained visual backbone:将图像编码成 visual features。
- pre-trained LLM:理解 user instructions 并生成文本回复。
- vision-language cross-modal connector:把 vision encoder 输出对齐到 LLM 的 word embedding / token feature space。
一些模型会额外使用 visual resampler,例如 Qformer,用于减少 visual patches 数量或进行 instruction-aware visual feature extraction。但作者强调,LLaVA 是一个非常简单的 LMM architecture:vision encoder + projection layer + LLM。
Two-stage training protocol
LMM 通常采用两阶段训练:
- Vision-language alignment pretraining:使用 image-text pairs 将 visual features 对齐到 language model 的 embedding space。
- Visual instruction tuning:使用 visual instruction data 训练模型跟随包含视觉内容的多样化用户请求。
作者特别对比了不同方法的 pretraining scale:早期模型可能使用约 600K 或 6M image-text pairs,而 InstructBLIP 和 Qwen-VL 等方法使用 129M 到 1.4B 级别数据。
Multimodal instruction-following data
LLaVA 的贡献是用 text-only GPT-4 将 COCO bounding boxes 和 captions 扩展成三类 multimodal instruction data:
- conversational-style QA;
- detailed description;
- complex reasoning。
InstructBLIP 则加入 academic-task-oriented VQA datasets,从而提升传统 VQA 性能。但已有研究指出,naive data merging 会让模型过拟合 short-form VQA answers,削弱自然对话能力。
Evidence used by the authors
作者引用 FLAN 系列在 NLP 中的经验:加入大量 academic language tasks 可以提升 instruction-tuned model 的 generalization ability。由此引出 LLaVA-1.5 的问题意识:multimodal models 是否也能通过加入 academic multimodal tasks 提升能力,同时避免 short-answer overfitting?
四、方法
4.1 问题

LLaVA 与 InstructBLIP 的能力分化:
- 原始 LLaVA 在 natural visual conversation 和 visual reasoning 上强,但在 short-answer academic VQA 上弱,并且 yes/no question 容易偏向回答 “yes”。
- InstructBLIP 在 VQA benchmarks 上强,但可能在需要 detailed response 的对话任务中输出过短答案,例如面对 “Is this unusual? Please explain in detail.” 时只回答 “yes”。
因此,方法部分的关键不是 “如何让模型只更会做 VQA”,而是 “如何让模型同时保留 natural conversation 能力和 academic task 能力”。
4.2 Key technical points
1. Response Format Prompting
作者认为 InstructBLIP 难以平衡 short-form 和 long-form answers,主要有两个原因:
- Response format ambiguous:类似
Q: {Question} A: {Answer}的 prompt 没有明确要求输出格式,容易让模型行为上过拟合 short answer。 - LLM not finetuned:InstructBLIP 只 finetune Qformer,使得 Qformer 的 visual output tokens 必须控制 LLM 输出长短;但相较 LLaMA 这类 LLM,Qformer 容量有限,不一定能可靠控制输出格式。

LLaVA-1.5 的解决方法是给 short-answer VQA 明确追加 response formatting prompt,例如:
Answer the question using a single word or phrase.
对于 multiple-choice 数据,如 A-OKVQA,则使用:
Answer with the option’s letter from the given choices directly.
这种设计的意义是:输出长度和格式由 instruction 显式控制,而不是依赖数据分布或隐式 prompt 模板。
2. MLP vision-language connector
原始 LLaVA 使用 single linear layer 将 visual features 投影到 language space。LLaVA-1.5 将其替换为 two-layer MLP。作者借鉴 self-supervised learning 中 projection head 的经验,认为 MLP 的 representation power 更强,因此能提升 multimodal capabilities。
这点很重要,因为它说明 cross-modal connector 不必复杂到 Qformer/visual resampler 的程度;一个简单 MLP 可能已经能在 data-efficient setting 下提供足够表达能力。
3. Academic-task-oriented data
LLaVA-1.5 加入多类 academic-task-oriented datasets:
- VQA: VQAv2, GQA, OKVQA, A-OKVQA;
- OCR: OCRVQA, TextCaps;
- region-level perception: Visual Genome, RefCOCO;
- visual conversation: LLaVA-Instruct;
- language conversation: ShareGPT。
最终 instruction-following data mixture 约为 665K,pretraining sample size 为 558K。其中 ShareGPT 约 40K conversations,主要提供 language instruction-following 和 multilingual behavior,而不是 multimodal data。
4. Additional scaling
作者进一步进行三类 scaling:
- 将 image resolution 提高到
336^2,使用CLIP-ViT-L-336px; - 加入 GQA 作为额外 visual knowledge source;
- 加入 ShareGPT,并将 LLM 扩展到 13B。
实验显示,scale up LLM 到 13B 对 MM-Vet 等 visual conversation benchmark 提升最明显,说明 base LLM capability 对复杂视觉对话很关键。
4.3 LLaVA-1.5-HD
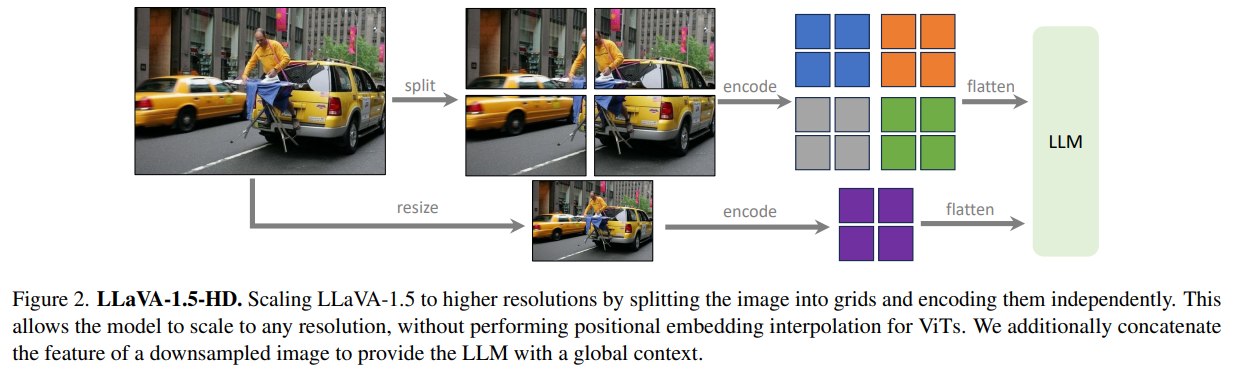
LLaVA-1.5-HD 是对更高输入分辨率的早期探索。由于 open-source CLIP vision encoders 的分辨率有限,作者没有采用 positional embedding interpolation,而是使用 grid-based strategy:
- 将图像 pad/resize 到合适 target resolution。
- 切分成若干
224^2patches。 - 每个 patch 独立经过 CLIP image encoder。
- 将 patch features merge 回一个大的 feature map。
- 额外拼接 downsampled image 的 global context,以减少 split-encode-merge artifact。
- 不进行额外 high-resolution pretraining,直接做 visual instruction tuning。
这种方法的优点是保持 data efficiency,并允许模型处理更灵活的输入分辨率。
4.4 Evidence
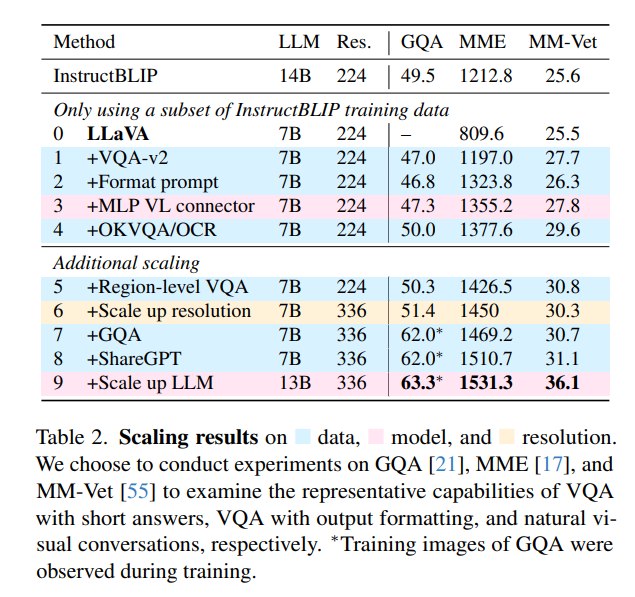
- 加入 VQA-v2 后,MME 从原始 LLaVA 的 809.6 提升到 1197.0。
- 加入 format prompt 后,MME 进一步到 1323.8。
- 加入 MLP connector 后,MME 到 1355.2,MM-Vet 到 27.8。
- 加入 OKVQA/OCR、region-level VQA、336 resolution、GQA、ShareGPT、13B LLM 后,最终 LLaVA-1.5-13B 在 GQA、MME、MM-Vet 上分别达到 63.3、1531.3、36.1。
训练成本方面,LLaVA-1.5 因为输入分辨率提高到 336^2,训练时间约为原始 LLaVA 的 2 倍:约 6 小时 pretraining + 约 20 小时 visual instruction tuning,使用 8×A100。
4.5 Assumptions and limitations
方法的核心假设是:prompt-level format control 加 LLM finetuning 可以解决 short-form 和 long-form answer 的冲突。这一假设在实验中得到支持,但它并不保证所有格式控制都能泛化到复杂 schema、长链式结构化输出或安全关键任务。
另一个限制是 LLaVA-1.5-HD 虽然提高了分辨率灵活性,但 full image patches 会增加训练和推理成本。
五、实验
LLaVA-1.5 在广泛 benchmarks 上取得最强 overall performance,同时使用的数据和算力显著少于许多竞争方法。实验不仅验证 benchmark performance,也探索 data efficiency、hallucination、high-resolution scaling 和 compositional capabilities 等 open problems。
实验部分主要回答四个问题:
- LLaVA-1.5 是否能同时提升 academic VQA 和 instruction-following visual conversation?
- 简单架构是否能与更复杂、更大数据规模的 LMM 竞争?
- 高分辨率、global context、LLM choice、data efficiency 对性能有什么影响?
- LLaVA-1.5 是否呈现出超出显式训练任务组合的 compositional capabilities?
5.1 Benchmarks
论文评估总计 12 个 benchmarks,可分为两类。
Academic-task-oriented benchmarks
- VQA-v2:open-ended short-answer visual perception。
- GQA:视觉场景理解与 compositional question answering。
- VizWiz:视觉障碍用户提出的问题,评估 zero-shot generalization 和 unanswerable handling。
- ScienceQA-IMG:带图像的 science question answering,使用 multiple-choice subset。
- TextVQA:text-rich visual question answering。
Instruction-following LMM benchmarks
- POPE:评估 hallucination,包含 random、popular/common、adversarial splits。
- MME-Perception:yes/no 形式的 visual perception benchmark。
- MMBench:multiple-choice all-round evaluation。
- MMBench-CN:MMBench 的中文版本。
- SEED-Bench:图像和视频任务;视频用中间帧评估。
- LLaVA-Bench-in-the-Wild:真实视觉对话场景,用 GPT-4 评估 correctness/helpfulness。
- MM-Vet:复杂视觉对话能力评估,也使用 GPT-4 evaluation。
5.2 Results
Overall benchmark performance
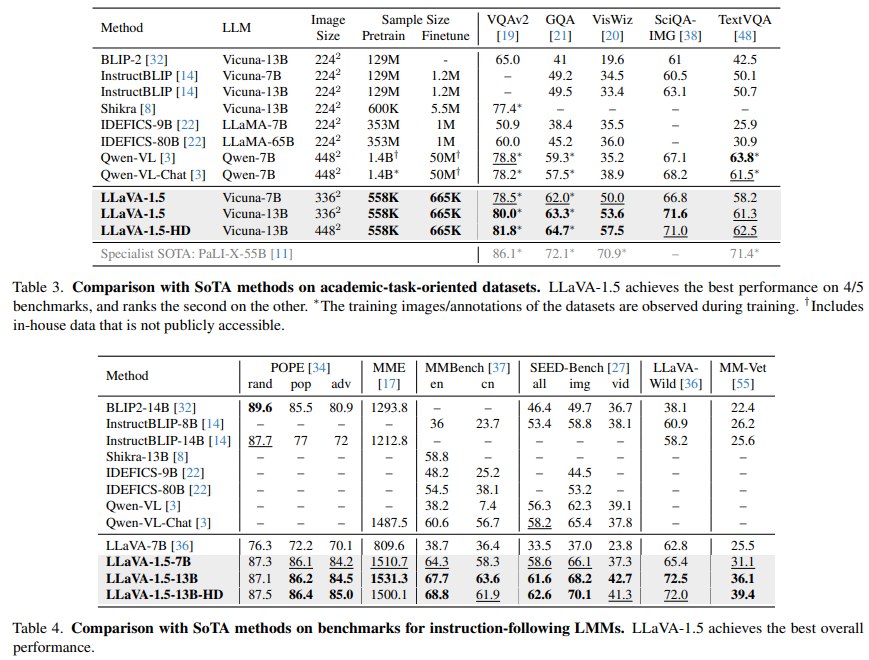
作者报告 LLaVA-1.5 在 12 个 benchmarks 上达到 best overall performance。更具体地说:
- 在 academic-task-oriented datasets 表中,LLaVA-1.5 在 5 个任务中取得 4 个最优,并在另一个任务中排名第二。
- 在 instruction-following LMM benchmarks 表中,LLaVA-1.5-13B 在 MME、MMBench、MMBench-CN、SEED-Bench、LLaVA-Wild、MM-Vet 等任务上表现强。
- 摘要和图示中的 “11 benchmarks/tasks” 与正文 “12 benchmarks” 不是完全矛盾:正文覆盖 12 个 benchmark 维度,而作者强调 SoTA/best coverage 时使用 11 个任务/benchmark 的表述。
Comparison with data-heavy methods
LLaVA-1.5 的一个关键实验意义是 data/compute efficiency:
- BLIP-2 / InstructBLIP 使用 129M 级别 pretraining data。
- Qwen-VL 使用 1.4B pretraining data 和 50M instruction tuning data,并包含 inaccessible in-house data。
- LLaVA-1.5 使用 558K pretraining samples 和 665K instruction-tuning samples,即约 1.2M publicly available data。
尽管数据规模小得多,LLaVA-1.5 仍取得强 overall performance。这支持作者关于 “visual instruction tuning 和 simple connector 足以构建强 baseline” 的论点。
High-resolution scaling
LLaVA-1.5-HD 将输入扩展到 448^2 或更灵活的 grid-based 高分辨率设置。结果显示:
- 高分辨率对需要 detail perception 的任务尤其有用,例如 OCR-heavy 或 detailed description tasks。
- 加入 global context 可以缓解 patch split/merge 带来的 artifact,并帮助模型定位 relevant regions。
- 在 7B ablation 中,global context 将 GQA 从 62.9 提升到 63.8,MME 从 1425.8 提升到 1497.5,MM-Vet 从 31.9 提升到 35.1。
Qualitative examples


论文用两个 qualitative examples 说明 LLaVA-1.5 的行为改进:
- Tricky question detection:当用户问 “What’s happening in the desert?”,但图像实际是 beach/city skyline 时,LLaVA-1.5 能指出图中没有 desert,而原始 LLaVA 更容易顺着错误前提回答。
- Constrained JSON output:在读取证件图像并输出 JSON 时,LLaVA-1.5 能更好遵循用户指定格式,虽然仍存在细节错误。
这些例子支持作者关于 response format generalization 和 visual grounding improvement 的说法,但它们仍是 qualitative evidence,不能替代系统性安全或鲁棒性评估。
5.3 Open-problem observations
Data efficiency
作者随机下采样 LLaVA-1.5 training data mixture,发现:
- full data mixture 仍提供最佳 knowledge coverage 和 overall performance。
- 只用 50% samples 时,模型仍能保持 full dataset performance 的 98% 以上。
- 从 50% 进一步到 30% 时,部分任务性能仍较稳定。
这说明 multimodal instruction tuning 可能也存在类似 LIMA/less-is-more 的现象,未来可以研究更有原则的 dataset compression 或 data selection。
Rethinking hallucination
作者提出一个很有启发性的 hallucination 解释:LMM 的 hallucination 不一定只来自训练数据中的错误描述;也可能来自 data granularity 与 model perception capability 的不匹配。
如果训练数据中的描述细节超出了模型在当前输入分辨率下能可靠感知的范围,模型可能会学习到一种在细节不足时仍生成细节的行为,从而表现为 hallucination。提高输入分辨率到 448^2 后,hallucination 显著减少,说明更强 perception capability 可以缓解这一问题。
Compositional capabilities
LLaVA-1.5 显示出一定 compositional capabilities:模型分别从 English-only visual instruction data 和 multilingual text-only ShareGPT data 中学习能力后,可以泛化到 multilingual visual conversation。类似地,ShareGPT 带来的语言能力也能与 visual grounding 结合,使模型在 visual writing tasks 中产生更长、更细节、更 grounded 的回复。
但作者也承认,组合能力并不完美。例如,模型能在 VQA 中识别某对象属性,不代表它一定能在整图 detailed description 中准确描述该属性;某些外语视觉对话能力仍然较弱。
六、结论
Conclusion 的核心观点是:LLaVA-1.5 通过简单、有效、数据高效的设计,帮助 demystify large multimodal model 的训练,并为 open-source LMM research 提供可复现 baseline。
结论又回到论文最初的问题:LMM 是否必须依赖复杂架构、大规模私有数据和高昂算力?
LLaVA-1.5 的答案是:不一定。至少在 LLaVA framework 下,简单 connector、明确 response formatting、公开数据和适度 scaling 就能产生强 baseline。
论文最终总结了三类贡献:
- Improved baseline:LLaVA-1.5 在多个 benchmarks 上达到强性能,并保持简单架构。
- Design understanding:通过 controlled study 展示 input resolution、MLP connector、academic-task data、format prompts、LLM scale 等因素的作用。
- Open-problem exploration:初步研究 high-resolution scaling、hallucination、data efficiency 和 compositional capability。
Limitations
作者明确承认以下限制:
- High-resolution training 更慢:LLaVA-1.5 使用 full image patches,训练 iteration 可能变长。
- 不支持 multiple-image understanding:受 instruction-following data 和 context length 限制,模型还不能可靠处理多图输入。
- 特定领域 problem solving 能力有限:复杂领域任务需要更强 LLM 和更高质量、有针对性的 visual instruction tuning data。
- 仍可能 hallucinate:尽管 hallucination tendency 降低,模型仍可能生成错误信息。
- critical applications 需谨慎使用:例如 medical 场景。

说些什么吧!