
零、写在前面
LLaVA 把 text-only LLM 中已经成功的 instruction tuning 思路迁移到 image-language 场景,提出 visual instruction tuning,并证明:用 GPT-4 生成的 multimodal instruction-following data,加上一个简单的 CLIP-to-Vicuna projection layer,就能训练出具备较强视觉对话和视觉指令跟随能力的开源模型。
证明了 visual instruction tuning 是构建开源 LVLM 的有效 recipe。
一、标题
Visual Instruction Tuning
模型的名字没有在标题中给出,摘要中给了模型名称:LLaVA, Large Language and Vision Assistant
二、摘要

摘要指出,本文首次尝试了视觉指令微调(Visual Instruction Tuning),探索了将指令微调从纯文本领域扩展到多模态领域的方法。摘要直接点明了本文贡献:
- 数据生成:提出了一种新颖的数据生成流程,利用纯语言模型 GPT-4,基于图像的文字描述(标题和边界框),自动生成了大量高质量的多模态语言-图像指令遵循数据,解决了此类数据匮乏的问题。
- 模型(LLaVA):基于生成的数据,开发了一个名为 LLaVA (Large Language and Vision Assistant) 的端到端训练大型多模态模型。该模型连接了一个视觉编码器和一个大型语言模型(LLM),以实现通用的视觉和语言理解。
- 实验结果:
- 多模态对话能力:LLaVA 展示了令人印象深刻的多模态聊天能力,在某些未见过的图像或指令上,其表现可与多模态 GPT-4 相媲美,在一个合成的多模态指令遵循数据集上取得了相当于 GPT-4 85.1% 的相对分数。
- 科学问答表现:在 Science QA 基准测试上进行微调后,LLaVA 与 GPT-4 协同工作,达到了 92.53% 的新的最先进准确率。
- 开源与基准:论文还构建了用于评估的基准,并将 GPT-4 生成的视觉指令微调数据、模型和代码全部开源。
三、引言
引言围绕研究背景、动机、现有方法和本文贡献展开:
-
研究背景与终极目标
人类通过视觉和语言等多种渠道与世界交互,不同渠道在表达特定概念时各有优势。 AI 领域的核心愿景之一是开发一个通用助手(general-purpose assistant),能够有效遵循多模态视觉-语言指令,并在各种真实场景中完成符合人类意图的任务。
-
传统视觉模型的局限性
社区虽然开发了许多语言增强的基础视觉模型,在分类、检测、分割、描述、视觉生成与编辑等任务上表现强大,但它们普遍存在一个共同问题: 每个任务由独立的大模型解决,任务指令隐式地嵌入在模型设计之中。 语言仅被用来描述图像内容,这导致模型接口固定,交互性和对用户指令的适应性都很有限。
While this allows language to play an important role in mapping visual signals to language semantics… it leads to models that usually have a fixed interface with limited interactivity and adaptability to the user’s instructions.
-
大型语言模型(LLM)带来的新范式
大型语言模型(如 ChatGPT、GPT-4)展示了另一种可能性:语言可以作为一个通用接口,让助手能根据显式的任务指令灵活切换任务。 此后,LLaMA、Alpaca、Vicuna 等开源 LLM 通过机器生成的指令遵循数据进行指令微调(instruction-tuning),在对齐能力上表现优异。 关键空白:这一切努力都仅限于纯文本领域。
Importantly, this line of work is text-only.
-
本文的核心动机与贡献
本文首次将指令微调延伸至多模态空间,提出 视觉指令微调(visual instruction-tuning),以向构建通用视觉助手迈出第一步。具体贡献如下:
- 多模态指令遵循数据:针对视觉-语言指令数据缺乏的问题,提出利用 ChatGPT/GPT-4 将图像-文本对自动转化为指令遵循格式的数据生成流程。
- 大型多模态模型(LMM):将 CLIP 的视觉编码器与语言解码器 Vicuna 相连接,端到端微调后得到 LLaVA,实验验证了这种生成数据对指令微调的有效性。
- 多模态指令遵循基准(LLaVA-Bench):提出两个具有挑战性的评测基准,涵盖多样化的图像-指令-标注三元组。
- 开源发布:公开生成的指令数据、代码库、模型检查点及视觉聊天演示。
四、GPT-assisted Visual Instruction Data Generation
4.1 为什么需要 GPT-assisted data generation
多模态领域并不缺 image-text pairs。CC、CC3M、LAION 等公开数据提供了大量图像和 caption。但是 instruction-following data 很少,因为人工构造“围绕一张图片的多轮对话、详细描述、复杂推理问题”成本高,而且标注规范不容易定义。
LLaVA 的关键想法是:既然 text-only GPT-4 已经很擅长生成高质量指令和回答,就可以把图像转换成 GPT-4 能读取的文本代理表示,然后让 GPT-4 生成视觉指令数据。
值得注意的是:论文中的 GPT-4 在数据生成阶段并没有直接看图像。 它是 text-only GPT-4,输入的是图像的 symbolic representation。
5.2 图像如何变成 GPT-4 可读的文本

论文使用两类 symbolic representations:
- Captions:从多个角度描述图像场景,例如 COCO 中一张图对应的若干 caption。
- Bounding boxes:提供目标类别和空间位置,例如
person: [x1, y1, x2, y2]、suitcase: [...]。
这些文本信息让 GPT-4 可以“间接知道”图像中有什么对象、对象在哪里、对象之间可能有什么关系。
然后作者用少量人工设计的 seed examples 做 in-context learning,提示 GPT-4 生成 instruction-following responses。
- 这种做法的优点是便宜、可扩展、能利用 GPT-4 的语言和推理能力;
- 缺点是 GPT-4 只能基于 captions/boxes 的信息生成回答,因此生成数据的视觉细节上限受输入文本代理限制。如果 captions 或 boxes 缺失细节,GPT-4 不可能真正补齐图像信息。
5.3 三类视觉指令数据
论文生成三类 response types。
| 类型 | 目标 | 数据特点 | 对模型能力的作用 |
|---|---|---|---|
| Conversation | 围绕图像进行问答对话 | 多轮问题,覆盖对象类型、数量、动作、位置、相对关系等 | 训练模型遵循用户问题,而不只是描述图像。 |
| Detailed description | 生成丰富、全面的图像描述 | 通常是单轮详细描述 | 增强模型输出细节和组织长文本的能力。 |
| Complex reasoning | 基于视觉内容进行深入推理 | 需要 step-by-step reasoning 和常识推断 | 增强模型把视觉事实与语言侧推理结合的能力。 |
最终数据规模为 158K unique language-image instruction-following samples:
| 数据类型 | 数量 |
|---|---|
| Conversation | 58K |
| Detailed description | 23K |
| Complex reasoning | 77K |
| Total | 158K |
论文还提到,早期实验比较过 ChatGPT 和 GPT-4,GPT-4 在空间推理等方面生成的数据质量更高,因此最终强调 GPT-4 作为 strong teacher。
5.4 数据构造的创新点
LLaVA 的数据构造不是简单“让 GPT-4 写 caption”,而是把已有 image-text pair 改造成 instruction-following format。例如最朴素的扩展方式是:
Human: <question/request> <image>
Assistant: <caption>
但论文认为这种 naive expansion 缺少 diversity 和 in-depth reasoning,所以进一步用 GPT-4 生成多样问题、详细描述和复杂推理答案。
从今天看,这个数据思路有两个长期影响:
- 数据可以成为 LVLM 能力的核心杠杆。 不一定先设计更复杂 architecture,也可以先扩大和改进 multimodal instruction data。
- 强闭源模型可以作为 data engine。 即使目标是训练开源模型,也可以利用 GPT-4 生成训练/评估数据。这条路线后来在多模态和纯文本开源模型中都非常常见。
五、Visual Instruction Tuning
5.1 Architecture
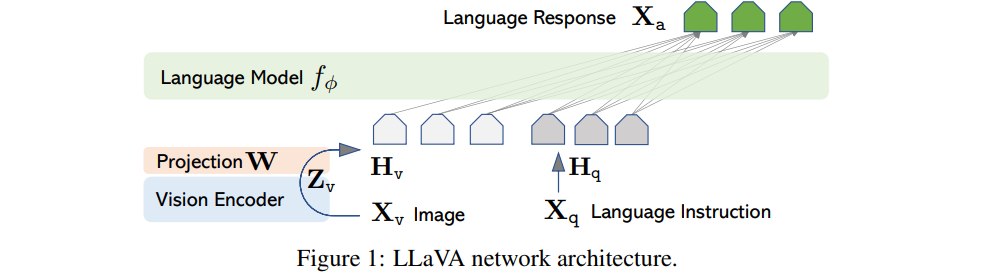
LLaVA 的架构非常简洁:
- 视觉编码器负责把图像变成视觉特征
- projection layer 把视觉特征映射到 LLM 的 word embedding space
- Vicuna 负责根据视觉 token 和文本指令生成回答。
组件表
| 组件 | 论文选择 | 是否训练 | 作用 |
|---|---|---|---|
| Visual encoder | CLIP ViT-L/14 | 始终 frozen | 将输入图像 X_v 编码成视觉特征 Z_v = g(X_v)。 |
| Connector / bridge | Trainable projection matrix W |
Stage 1 训练;Stage 2 继续训练 | 将视觉特征投影成与 LLM word embedding 同维度的 visual tokens H_v = W · Z_v。 |
| LLM | Vicuna, based on LLaMA | Stage 1 frozen;Stage 2 更新 | 执行 instruction following、对话生成、推理和答案输出。 |
| Training objective | Auto-regressive language modeling | 训练 assistant response tokens | 只对 assistant answers 和 stop token 计算 loss。 |
Q:为什么是 simple projection
A:
因为便宜LLaVA 明确承认更复杂的连接方式是可能的,例如 Flamingo 的 gated cross-attention、BLIP-2 的 Q-Former。但本文选择简单 projection layer,原因是:
- 轻量,便于快速迭代 data-centric experiments。 如果核心问题是验证 visual instruction tuning 的有效性,复杂结构会让变量变多。
- 强 CLIP + 强 Vicuna 已经提供很多能力。 Projection layer 只需要把视觉特征对齐到语言 embedding 空间。
- 可作为开源 baseline。 简单架构更容易复现和扩展,也更容易让社区在其上改数据、改 recipe、改 benchmark。
这一点和 MiniGPT-4 是一样的
输入输出格式:
训练时,LLaVA 将多轮对话组织成 Vicuna-style conversation sequence。第一轮 instruction 会随机选择 [question, image] 或 [image, question] 的顺序,后续轮次只有文本 question。模型只在 assistant response tokens 上计算 auto-regressive loss。
这有两个效果:
- 图像被当作整段对话的 grounding context。 即使后续问题不再显式插入图像,回答仍然条件化在最初的 visual tokens 上。
- 训练目标与 LLM instruction tuning 保持一致。 它没有引入额外 detection loss、contrastive loss 或 VQA-specific objective,而是统一成 next-token prediction。
LLaVA 架构强在简洁,但也带来信息瓶颈。
Projection matrix 需要把 CLIP grid features 直接映射到 LLM embedding space,缺少类似 Q-Former 或 cross-attention 的显式查询、筛选、压缩和区域级交互机制。
因此原始 LLaVA 在 OCR、fine-grained grounding、高分辨率细节理解等任务上天然不如后来更系统的数据和接口设计模型。
5.2 Training

5.2.1 Stage 1: Pre-training for Feature Alignment
第一阶段目标是让 visual features 与 LLM word embedding space 对齐。论文称之为 feature alignment,可以理解为给 frozen LLM 训练一个兼容的 visual tokenizer。
| 项目 | 设置 |
|---|---|
| 数据 | filtered CC3M / CC-595K |
| 规模 | 595K image-text pairs |
| 数据构造 | 将 image-text pair 用 naive expansion 转成单轮 instruction-following format |
| 冻结模块 | CLIP visual encoder 和 LLM 都 frozen |
| 训练参数 | 只训练 projection matrix W |
| epoch | 1 |
| learning rate | 2e-3 |
| batch size | 128 |
| 训练硬件 | 8×A100 |
| 用时 | 4 小时内完成 |
CC-595K 的过滤方式来自 appendix:对 CC3M caption 抽取 noun phrases,统计频率,跳过频率小于 3 的稀有 noun phrases;从低频 noun phrases 开始加入候选 caption;如果某个 noun phrase 频率超过 100,则随机选 100 个 caption。这样得到约 595K image-text pairs,在减少数据量的同时保持概念覆盖。
这个阶段的关键是:不更新 LLM,不更新 visual encoder,只让 projector 学会把 CLIP features 放到 LLM 能理解的位置。
5.2.2 Stage 2: Fine-tuning End-to-End
第二阶段保持 visual encoder frozen,但更新 projection layer 和 LLM 参数。论文考虑两个 use cases。
| Use case | 数据 / 任务 | 训练形式 | 目的 |
|---|---|---|---|
| Multimodal Chatbot | LLaVA-Instruct-158K | conversation / detailed description / complex reasoning 三类数据均匀采样 | 获得开放式视觉对话和指令跟随能力。 |
| ScienceQA | ScienceQA multimodal science questions | 单轮 conversation;question & context 作为 instruction,reasoning & answer 作为 answer | 测试视觉科学问答和推理能力。 |
Multimodal chatbot 的训练设置:
| 项目 | 设置 |
|---|---|
| 数据 | LLaVA-Instruct-158K |
| epoch | 3 |
| learning rate | 2e-5 |
| batch size | 32 |
| 训练硬件 | 8×A100 |
| 用时 | 10 小时内完成 |
ScienceQA fine-tuning 在实验中训练 12 epochs。论文还使用 reasoning-first 的输出格式,即让模型先预测 reasons,再预测 answer。
5.2.3 Appendix 中的训练细节
Appendix 给出更多实现细节:
- optimizer:Adam;
- weight decay:no weight decay;
- learning rate schedule:cosine learning rate;
- warmup ratio:3%;
- memory optimization:FSDP 和 gradient checkpointing;
- offloading:not used;
- precision:BF16 和 TF32 enabled;
- ScienceQA fine-tuning:8×A100,4 小时内完成。
5.2.4 训练 recipe 小结
LLaVA 的训练 recipe 基本就是:
- 先对齐接口。 用 CC-595K 让 projector 把 CLIP visual features 映射到 LLM embedding space。
- 再对齐行为。 用 GPT-4 生成的 visual instruction data 让模型学会以 assistant 的方式回答用户视觉问题。
这一区分很重要。Stage 1 解决“LLM 能不能接收视觉 token”的问题,Stage 2 解决“模型能不能按用户指令使用视觉 token”的问题。
六、Evaluation
6.1 Multimodal Chatbot
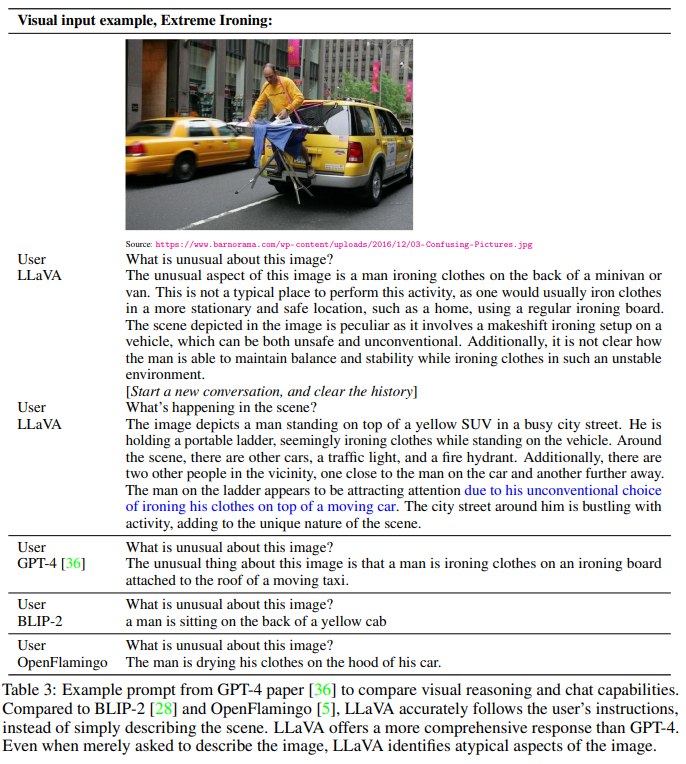
论文先用 GPT-4 论文中的视觉例子做定性比较。例如 Extreme Ironing 图像中,用户问 “What is unusual about this image?”。LLaVA 能识别异常之处在于有人在车上熨衣服,并按问题意图解释为什么不寻常。BLIP-2 和 OpenFlamingo 往往更像 captioning model,只描述场景而没有很好地跟随问题。
这个例子服务于论文主张:visual instruction tuning 不只是让模型知道图像里有什么,而是让模型能根据用户指令选择合适回答方式。
Appendix 还展示了更多定性能力:解释 chicken nugget map meme、根据 sketch 生成 HTML/JS/CSS、根据冰箱内容生成菜谱、关联 Titanic 场景和 Mona Lisa 等。这些例子说明 LLaVA 能把视觉内容与 LLM 中已有的文本知识和生成能力结合起来。
但这些 qualitative examples 也需要谨慎看待。它们证明模型有 interesting behaviors,却不能直接说明模型具备稳定、全面、可靠的多模态推理能力。
6.2 GPT-4-based quantitative evaluation
开放式视觉问答很难用 exact match 或 accuracy 衡量。LLaVA 借鉴 Vicuna 评测思路,用 text-only GPT-4 作为 judge。
评测流程是:
- 构造 image、ground-truth textual descriptions、question 三元组。
- 待评估模型根据 image + question 生成回答。
- text-only GPT-4 基于 question 和 ground-truth textual descriptions 生成 reference response,作为近似 theoretical upper bound。
- 再把 question、文本化 visual information、两个 assistant responses 输入 GPT-4 judge。
- GPT-4 judge 从 helpfulness、relevance、accuracy、level of detail 等维度打 1-10 分。
- 报告相对于 text-only GPT-4 reference 的 relative score。
这里 GPT-4 不是直接看图,而是基于人工或数据管线提供的 textual visual information 做评估。因此它更像一种 LLM-assisted evaluation protocol,而不是严格的人类视觉评测。
6.3 LLaVA-Bench (COCO)
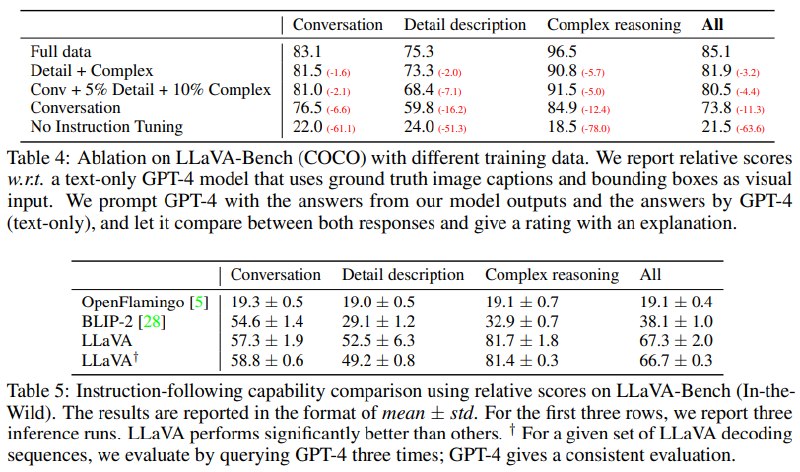
LLaVA-Bench (COCO) 从 COCO-Val-2014 随机选择 30 张图,每张图生成三类问题:conversation、detailed description、complex reasoning,总计 90 个问题。该 benchmark 主要研究模型在与训练生成流程一致的视觉输入上的 alignment behavior。
关键结果如下:
| Training data | Conversation | Detail description | Complex reasoning | All |
|---|---|---|---|---|
| Full data | 83.1 | 75.3 | 96.5 | 85.1 |
| Detail + Complex | 81.5 | 73.3 | 90.8 | 81.9 |
| Conv + 5% Detail + 10% Complex | 81.0 | 68.4 | 91.5 | 80.5 |
| Conversation | 76.5 | 59.8 | 84.9 | 73.8 |
| No Instruction Tuning | 22.0 | 24.0 | 18.5 | 21.5 |
几个结论非常清楚:
- Instruction tuning 极其关键。 No Instruction Tuning 只有 21.5,而 full data 达到 85.1。
- 三类数据互补。 只用 conversation 数据整体 73.8;加入 detailed description 和 complex reasoning 后提升明显。
- Reasoning data 也能改善 conversation。 论文指出 detailed description 和 complex reasoning 不只提升对应任务,也改善 conversation performance。
6.4 LLaVA-Bench (In-the-Wild)

In-the-Wild benchmark 更难。它包含 24 张 diverse images 和 60 个问题,覆盖 indoor/outdoor scenes、memes、paintings、sketches 等,并为每张图提供高度详细的人工描述和问题。
结果如下:
| Model | Conversation | Detail description | Complex reasoning | All |
|---|---|---|---|---|
| OpenFlamingo | 19.3 ± 0.5 | 19.0 ± 0.5 | 19.1 ± 0.7 | 19.1 ± 0.4 |
| BLIP-2 | 54.6 ± 1.4 | 29.1 ± 1.2 | 32.9 ± 0.7 | 38.1 ± 1.0 |
| LLaVA | 57.3 ± 1.9 | 52.5 ± 6.3 | 81.7 ± 1.8 | 67.3 ± 2.0 |
| LLaVA† | 58.8 ± 0.6 | 49.2 ± 0.8 | 81.4 ± 0.3 | 66.7 ± 0.3 |
LLaVA 相比 BLIP-2 和 OpenFlamingo 的优势很明显,尤其是 complex reasoning。论文解释为 visual instruction tuning 让模型更能跟随用户问题,而不是只做 image description。
但 In-the-Wild benchmark 也揭示了局限。例如 ramen 图像需要餐厅品牌识别、多语言理解和外部知识;fridge 图像要求高分辨率细节识别和品牌识别。论文观察到 LLaVA 有时会把图像当成 “bag of patches”,例如把“有草莓”和“有酸奶”错误结合成“有草莓味酸奶”。这说明模型还不具备稳定的细粒度视觉语义组合能力。
6.5 ScienceQA
ScienceQA 包含 21K multimodal multiple-choice questions,覆盖 3 个 subjects、26 个 topics、127 个 categories 和 379 个 skills。划分为 12,726 train、4,241 validation、4,241 test。
LLaVA 在 ScienceQA 上的核心结果:
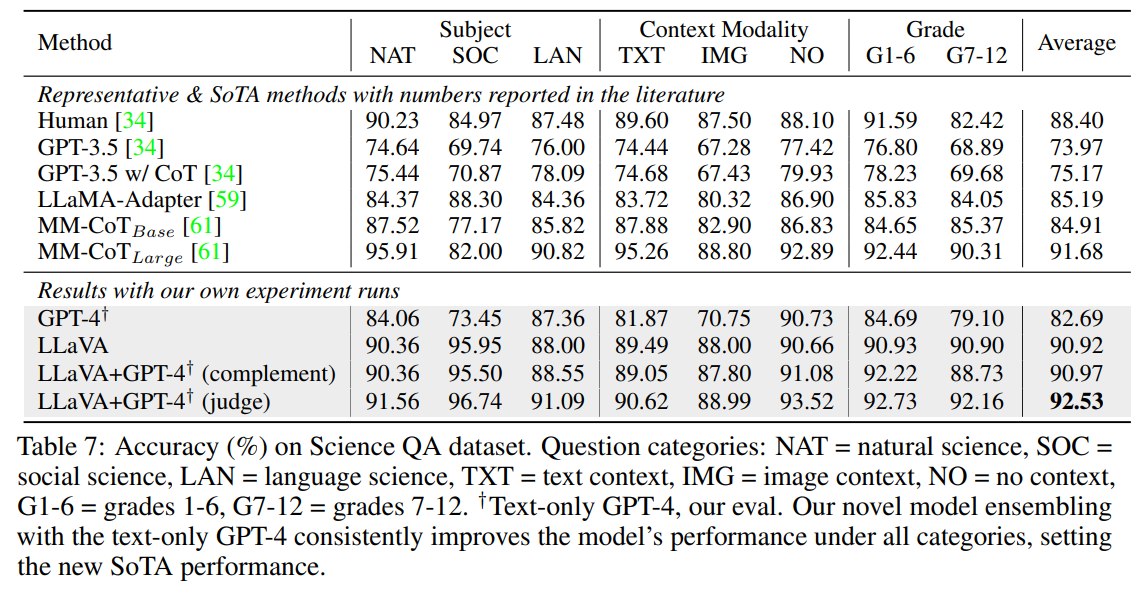 这里最容易误读的是 92.53%。它不是单个 LLaVA 模型的纯性能,而是 LLaVA + text-only GPT-4 as judge 的 ensemble 结果。
这里最容易误读的是 92.53%。它不是单个 LLaVA 模型的纯性能,而是 LLaVA + text-only GPT-4 as judge 的 ensemble 结果。
论文测试了两种结合方案:
- GPT-4 complement:当 GPT-4 不能回答时,用 LLaVA prediction 替代。结果 90.97,几乎等于 LLaVA 单独表现。
- GPT-4 as judge:当 GPT-4 和 LLaVA 答案不同,重新提示 GPT-4 根据问题和两个模型结果给最终答案。结果 92.53,成为新的 SoTA。
这个结果有两个含义:
- LLaVA 本身已经接近当时 ScienceQA SoTA,但并未超过 MM-CoT Large 的 91.68。
- text-only GPT-4 虽然不能看图,但能基于题目、常识和 LLaVA 的候选答案做 meta-reasoning,从而纠正一部分错误。
6.6 Ablations
论文的 ablation 提供了很多 practical lessons。
1、Instruction tuning 是主要能力来源
LLaVA-Bench (COCO) 中,No Instruction Tuning 的 overall score 是 21.5,而 full data 是 85.1。这说明只做 feature alignment 远远不够;模型必须学习如何根据用户指令组织回答。
这也回答了一个关键问题:LLaVA 的能力来自 vision encoder、LLM、projector,还是 instruction data?
更准确的答案是:
- CLIP 提供视觉语义基础;
- Vicuna 提供语言生成、对话和推理能力;
- projection layer 提供跨模态接口;
- instruction data 决定模型是否会以 assistant 的方式使用这些能力。
如果没有 instruction data,前三者连接起来也不会自然形成视觉指令跟随能力。
2、三类指令数据互补
Conversation-only 的 all score 是 73.8;加入 detailed description 和 complex reasoning 后,full data 达到 85.1。特别是 detailed description 从 59.8 提升到 75.3,complex reasoning 从 84.9 提升到 96.5。
这说明视觉对话模型不能只靠问答对训练。详细描述数据增强细节表达,复杂推理数据增强逻辑组织和常识关联,二者都会反过来提升 general conversation。
3、Feature alignment pretraining 很重要
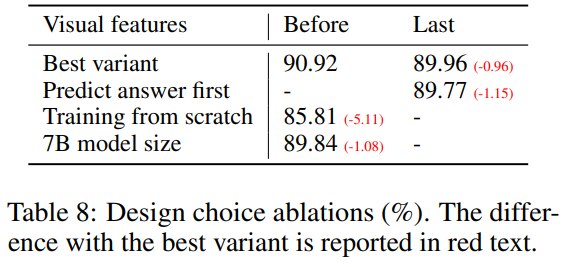
ScienceQA ablation 中,跳过 pretraining 直接从 scratch 在 ScienceQA 上训练,accuracy 从 90.92 降到 85.81,下降 5.11 个百分点。
这说明 Stage 1 不只是 warm-up,而是让 projector 与 LLM embedding space 建立稳定对齐。没有这个阶段,Stage 2 需要同时学习视觉接口和任务行为,效果明显变差。
4、CLIP feature layer choice matters
ScienceQA 中,使用 CLIP vision encoder 的 before-last layer feature 达到 90.92,而 last layer feature 是 89.96,下降 0.96。论文猜测 last layer 更偏全局和抽象属性,before-last layer 更保留局部细节,因此对需要具体图像细节的问题更有用。
这个观察对后续 LVLM 很重要:视觉特征不一定越高层越好,任务需要的空间/局部信息会影响 feature selection。
5、CoT-like reasoning-first 主要改善收敛
论文比较 answer-first 和 reasoning-first。reasoning-first 可以更快达到较高 accuracy,但进一步训练后最终性能提升有限。作者结论是:CoT-like reasoning-first strategy 大幅改善 convergence,但对最终 performance 贡献相对小。
6、Model scale 有帮助但不是唯一因素
13B best variant 是 90.92,7B model size 是 89.84,下降 1.08。这说明更大 LLM 有帮助,但在 LLaVA 这个设置中,数据和训练 recipe 同样关键。
七、总结
7.1 Limitations and Risks
论文的局限可以从正文、appendix 和实验失败案例中总结。
7.1.1 细粒度视觉理解不足
In-the-Wild benchmark 中的 fridge 和 ramen 例子说明,LLaVA 对高分辨率细节、品牌文字、多语言标识、细粒度物体属性的处理还不稳定。原始 LLaVA 使用 CLIP ViT-L/14 和简单 projector,没有专门为 OCR、document、chart 或 grounding 做接口和数据设计。
这也是它与 Qwen-VL 的重要差别:Qwen-VL 把 OCR、text reading、grounding 和 position-aware adapter 作为系统能力建设的一部分,而 LLaVA 原始论文主要聚焦 visual instruction following。
7.1.2 Hallucination
Appendix 明确提到 LLaVA 可能生成不基于事实或输入数据的内容,类似 LLM hallucination。在医疗等 critical applications 中,这会带来安全风险。
图像场景中 hallucination 更复杂,因为模型可能:
- 编造图中不存在的物体;
- 把两个真实物体错误组合;
- 用语言模型常识覆盖视觉证据;
- 对不确定细节给出过度自信回答。
7.1.3 Bias transfer
LLaVA 建立在 CLIP、LLaMA 和 Vicuna 上,因此会继承视觉编码器和语言模型中的偏见。CLIP 可能带来图像-文本数据偏见,LLaMA/Vicuna 可能带来语言文化、性别、职业、地区等偏见。
7.1.4 Evaluation robustness
论文用 text-only GPT-4 作为 judge,作者也承认这种 multimodal evaluation 很复杂。GPT-4-based evaluation 在本文中表现一致,但在不同任务、不同模型、不同 prompt 下的鲁棒性仍需要研究。
尤其要注意:GPT-4 judge 基于 textual descriptions 评估回答,并不直接访问原图。这种评估方式对 detailed annotation 的质量高度敏感。
7.1.5 Data generation bias
GPT-4 生成的 instruction data 受输入 captions/boxes 和 prompt examples 影响。它可能偏向语言上流畅但视觉上不完全可靠的回答,也可能继承 GPT-4 本身的表达风格和推理偏差。
因此 LLaVA 的数据 pipeline 很强,但不是免费真值来源。后续工作需要更系统地研究生成数据的 correctness、diversity、coverage 和 bias。
7.2 未来研究问题
7.2.1 如何构造更可靠的 multimodal instruction data?
LLaVA 用 captions 和 boxes 作为 GPT-4 的文本代理输入,这种方式可扩展,但会受代理信息质量限制。后续问题包括:
- 如何让生成数据更忠实于图像?
- 如何减少 GPT-4 语言偏见和 hallucination?
- 如何覆盖 OCR、grounding、document、chart、GUI 等更细粒度任务?
- 如何评估生成指令数据的多样性、难度和错误类型?
7.2.2 Simple projector 的信息瓶颈在哪里?
LLaVA 选择 simple projection 是很好的 baseline,但它可能不足以处理复杂视觉结构。可以继续研究:
- Q-Former、cross-attention、Perceiver Resampler、position-aware adapter 与 MLP projector 的差异;
- connector 是否应该保留更多 spatial information;
- connector 是否应该支持 dynamic resolution 和 variable visual token;
- 对 OCR/grounding/document 等任务,simple projector 的失效模式是什么。
7.2.3 如何评估开放式 multimodal instruction following?
GPT-4 judge 是实用方案,但不是最终答案。未来需要:
- 更可靠的人类评测协议;
- 更可复现的自动评测指标;
- 针对 hallucination、visual grounding、fine-grained perception 的专项评测;
- 避免 judge 模型偏好长答案、流畅答案或某类语言风格。
7.2.4 如何减少 visual hallucination?
LLaVA 的开放生成能力带来 hallucination 风险。后续可以研究:
- 视觉证据校验;
- uncertainty-aware answering;
- grounding-aware generation;
- retrieval-augmented multimodal reasoning;
- hallucination-specific training data 和 preference optimization。
7.2.5 如何把 visual assistant 扩展到真实应用?
原始 LLaVA 主要聚焦 real-life image tasks 和 visual chat。真实应用还需要:
- 高分辨率文字读取;
- 文档、表格、图表理解;
- 多图、多轮长上下文;
- video understanding;
- GUI / agentic interaction;
- safety、privacy 和 bias mitigation。

说些什么吧!