
零、写在前面
在每一步生成时都选择概率最高的 token,最终只得到一条 reasoning path,不一定就能得到正确答案,很多时候一个问题有多个解题思路,并且多个解题思路都能得到正确答案,那么综合多次推理的结果往往能够提高答案正确性。
读完这篇工作后,最大启发是:推理不是只生成一条链,而可以是一种 test-time search。CoT 让模型“会写推理过程”,Self-Consistency 让模型“多写几种推理过程,然后用答案一致性做选择”。这正是很多后续 reasoning system 的雏形。
一、标题
Self-Consistency Improves Chain of Thought Reasoning in Language Models
作者来自 Google Research, Brain Team
自洽性能够提升语言模型中的思维链推理
标题里的关键词有三个:
Self-Consistency:不是让多个模型彼此一致,而是让同一个模型生成多条 reasoning paths,然后看这些路径最终答案是否一致。Improves:论文强调它是一个可叠加的改进方法,建立在已有 CoT prompting 之上。Chain of Thought Reasoning:这里仍然沿用 CoT 的基本范式,让模型先生成中间推理步骤,再给出 final answer。
最重要的一点是:Self-Consistency 不是新的 prompt template,而是新的 decoding strategy。
二、摘要
Self-Consistency 用多条 sampled reasoning paths 的 answer-level consistency 替代单条 greedy path,从而显著提升 CoT reasoning 的准确率和稳定性。
摘要主要讲了五点:
第一,CoT prompting 已经在复杂 reasoning tasks 上取得了不错效果。它让模型输出 intermediate reasoning steps,而不是直接输出 answer。
第二,已有 CoT 通常使用 greedy decoding。也就是说,在每一步生成时都选择概率最高的 token,最终只得到一条 reasoning path。
第三,论文提出 self-consistency:用 sampling 生成一组 diverse reasoning paths,然后 marginalize out 这些 reasoning paths,选择 final answer 中最一致的答案。
即:
- 不要只问模型一次。
- 让模型用不同方式推理多次。
- 如果多个不同推理过程都得到同一个答案,就更可能是正确答案。
第四,Self-Consistency 的核心直觉是:复杂推理题通常有多条不同的解题路径,但正确答案通常唯一。错误路径也可能出现,但不同错误路径不一定会收敛到同一个错误答案。
第五,实验显示 Self-Consistency 在 arithmetic 和 commonsense reasoning 上带来显著提升:
- GSM8K:
+17.9% - SVAMP:
+11.0% - AQuA:
+12.2% - StrategyQA:
+6.4% - ARC-challenge:
+3.9%
三、引言
3.1 CoT 的成功与 greedy decoding 的局限
CoT prompting 的基本想法是让模型先写推理过程,再写答案。例如:
Q: If there are 3 cars in the parking lot and 2 more cars arrive,
how many cars are in the parking lot?
A: There are 3 cars in the parking lot already.
2 more arrive.
Now there are 3 + 2 = 5 cars.
The answer is 5.
这种形式比直接回答 5 更适合多步推理,因为模型可以把问题拆成 intermediate steps。
但默认 CoT 还有一个容易忽略的问题:它通常使用 greedy decoding。greedy decode 每一步都选当前概率最大的 token,于是只生成一条最可能的 reasoning path。
问题在于:最高概率的推理路径不一定是正确路径。
尤其是复杂推理题,模型可能一开始就走错一个局部步骤。greedy decoding 一旦走进错误路径,后面会继续沿着这个路径生成,看起来很流畅,但最终答案错。
3.2 为什么多条 reasoning paths 有帮助?
复杂问题往往可以用不同方式求解。
例如一道数学题可以这样解:
- 先算剩余数量,再乘单价。
- 先算每天用掉多少,再算剩余数量。
- 直接写成一个算式。
这些路径表面不同,但如果它们都正确,最后答案应该相同。
Self-Consistency 抓住的正是这个点:
- 正确 reasoning paths 即使形式不同,也更可能收敛到相同 final answer。
- 错误 reasoning paths 可能分散到不同错误答案。
这就是论文所谓的 self-consistency。
3.3 Sample-and-Marginalize
论文把方法概括为 sample-and-marginalize。
sample 是指从模型 decoder 中采样多条 reasoning paths,而不是只取 greedy path。
marginalize 是指最终不关心具体是哪条 reasoning path,而是把 reasoning path 当作 latent variable 消掉,只看 final answer 的一致性。
这句话听起来有点数学,但直觉很简单:
- 推理过程可以有很多种。
- 最终答案才是要聚合的对象。
3.4 为什么不是普通 ensemble?
Self-Consistency 很像 ensemble,但它不是训练多个模型,也不是使用多个模型投票。
它是:
single model + multiple sampled reasoning paths + answer vote
所以论文称它更像一种:self-ensemble
也就是同一个模型对同一个问题“多想几遍”,再根据答案一致性做选择。
四、背景和相关工作
4.1 Chain-of-Thought Prompting
Chain-of-Thought prompting 通过在 prompt 中加入 step-by-step exemplars,让 LLM 生成一串中间推理步骤。
形式上,它从:
input -> output
变成:
input -> reasoning path -> output
CoT 对 arithmetic reasoning、commonsense reasoning、symbolic reasoning 等任务尤其有效。
但 CoT 本身只规定了输出结构,并没有规定 decoding 时应该如何选择 reasoning path。默认做法通常是 greedy decoding。
Self-Consistency 就是在 CoT 的基础上改 decoding。
4.2 Sampling Decoding
语言模型生成文本时可以有多种 decoding 方法。
greedy decoding:
每一步都选概率最高的 token。
优点是稳定、便宜、可复现。缺点是容易陷入局部最优,而且只得到一条路径。
temperature sampling:
从概率分布中随机采样 token,temperature 控制随机性。
temperature 越高,输出越多样;temperature 越低,输出越接近 greedy。
top-k sampling:
每一步只在概率最高的 k 个 token 中采样。
nucleus sampling / top-p sampling:
每一步在累计概率达到 p 的候选 token 集合中采样。
Self-Consistency 可以和这些 sampling 方法结合。它需要 diversity,但不希望完全随机,所以论文通常使用 temperature sampling 加 top-k。
4.3 Re-ranking / Verifier
在生成式任务中,另一类常见方法是先生成多个候选,再用 scorer 或 verifier 排序。
比如数学题里可以训练一个 verifier,判断某条 solution 是否正确。Cobbe et al. 的 GSM8K verifier 就属于这类路线。
但 verifier 通常需要:
- 额外训练数据。
- 额外模型。
- 人工标注或自动构造的 correctness labels。
Self-Consistency 不训练 verifier,也不需要额外标注。它只利用 final answers 的一致性。
4.4 Sample-and-Rank
sample-and-rank 也会采样多个 outputs,但它通常选择 log probability 最高的那条生成。
它的逻辑是:
采样多个候选 -> 根据模型概率排序 -> 选概率最高的候选
Self-Consistency 的逻辑不同:
采样多个候选 -> 抽取 final answer -> 选出现次数最多的 answer
这两个方法的区别很重要。Self-Consistency 不相信“最高概率路径一定最正确”,而相信“多个不同路径都得到的答案更可靠”。
4.5 Beam Search
beam search 会保留多个高概率 partial sequences。它在机器翻译等任务中常见。
但对于 reasoning paths,beam search 往往缺乏多样性。多个 beams 可能只是同一个高概率路径的轻微变体,不能真正探索不同解法。
beam search 和 self-consistency 是有本质区别的。
论文实验显示,Self-Consistency with sampling 明显优于 beam search。这说明 reasoning 任务中 diversity 很关键。
4.6 Consistency in Language Models
语言模型中的 consistency 以前常用于对话一致性、事实一致性、解释一致性等。
这篇论文中的 consistency 是更具体的:
不同 reasoning paths 得到的 final answers 是否一致。
因此,它关注的不是每句话是否事实正确,而是 answer-level agreement。
五、方法
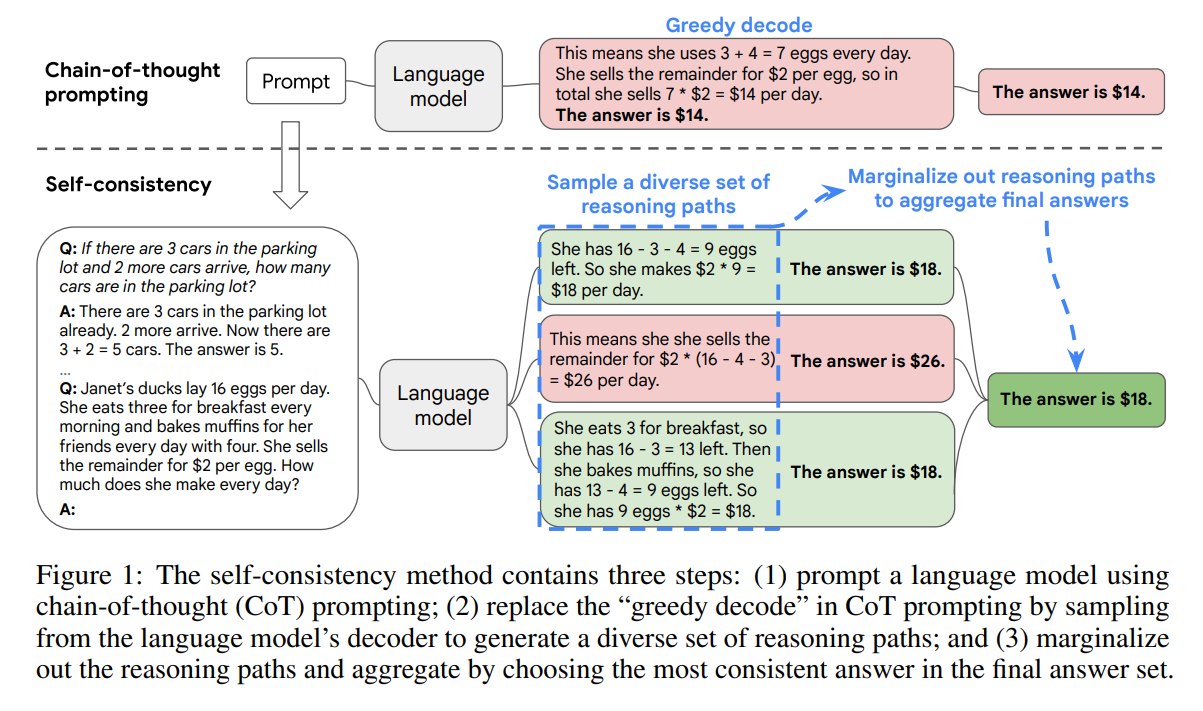
5.1 流程
Self-Consistency 有三步。
第一步,用 CoT prompt 提示模型,让它具备生成 reasoning path 的格式:
Q: ...
A: reasoning steps ... The answer is ...
第二步,不使用 greedy decoding,而是从模型 decoder 中采样多条 outputs:
$$ (r_1, a_1), (r_2, a_2), ..., (r_m, a_m) $$其中:
- $r_i$ 是第 $i$ 条 reasoning path。
- $a_i$ 是第 $i$ 条 reasoning path 给出的 final answer。
- $m$ 是采样路径数量,论文主实验常用 40。
第三步,忽略具体 reasoning path,只聚合 final answers:
$$ answer = majority_{vote}(a_1, a_2, ..., a_m) $$展示一个例子,假设问题是:
Janet's ducks lay 16 eggs per day.
She eats 3 for breakfast and uses 4 for muffins.
She sells the rest for $2 per egg.
How much does she make every day?
模型采样出 4 条 reasoning paths:
| path | reasoning 摘要 | final answer |
|---|---|---|
| Path 1 | 16 - 3 - 4 = 9, 9 * 2 = 18 |
$18 |
| Path 2 | 错把剩余或收入算错 | $26 |
| Path 3 | 16 - 3 = 13, 13 - 4 = 9, 9 * 2 = 18 |
$18 |
| Path 4 | 错把用掉的蛋乘 2 | $14 |
final answers 是:
$18, $26, $18, $14
majority vote 后选择:
$18
这就是 Self-Consistency 的直觉:虽然某些 path 会错,但正确答案在多条不同正确路径中重复出现。
5.2 Majority vote
论文把 reasoning path 看成 latent variable。
给定 prompt 和 question,模型采样出:
$$ (r_i, a_i), i = 1, ..., m $$其中 $r_i$ 是 reasoning path,$a_i$ 是 answer。
Self-Consistency 最简单的聚合公式是:
$$ argmax_a Σ_i \ 1 \ (a_i = a) $$其中:
- $a$:某个候选 final answer。
- $a_i$:第
i条 sampled path 的 final answer。 - $1(a_i = a)$:如果第
i条路径答案等于a,记为 1,否则记为 0。 - $Σ_i$:把所有路径的投票加起来。
- $argmax_a$:选择得票最多的答案。
这就是 majority vote。
也就是取众数:统计每个答案出现了几次,选出现次数最多的那个。
5.3 为什么叫 marginalize out reasoning paths?
在概率图景里,我们真正关心的是 answer a,但模型生成时会先生成 reasoning path r。
因此可以把 r 看成一个中间变量:
question -> reasoning path r -> answer a
Self-Consistency 不是选择某一条最好的 r,而是把很多可能的 r 都考虑进去,看它们支持哪个 a。
这就是:
marginalize out r
即:
- 不要纠结哪条推理过程看起来最漂亮;
- 看多条推理过程最后共同支持哪个答案。
5.4 为什么用Majority Vote ?
论文也比较了不同 answer aggregation strategies。
常见策略包括:
unweighted sum / majority vote:每条 path 一票。weighted sum:按模型生成概率加权。weighted average:按答案组内平均概率加权。normalized weighted sum:用长度归一化后的生成概率加权。
Table 1 显示,在 PaLM-540B 上,majority vote 和 normalized weighted sum 非常接近:
| Aggregation | GSM8K | MultiArith | AQuA | SVAMP | CSQA | ARC-c |
|---|---|---|---|---|---|---|
Greedy decode |
56.5 | 94.7 | 35.8 | 79.0 | 79.0 | 85.2 |
Weighted sum (normalized) |
74.1 | 99.3 | 48.0 | 86.8 | 80.7 | 88.7 |
Unweighted sum / majority vote |
74.4 | 99.3 | 48.3 | 86.6 | 80.7 | 88.7 |
也就是说,majority vote 在 GSM8K 74.4、MultiArith 99.3、AQuA 48.3、SVAMP 86.6、CSQA 80.7、ARC-c 88.7,表现已经非常强。
论文解释说,一个原因是不同 sampled outputs 的 normalized probabilities 往往很接近,模型本身并不能很好地区分哪条 path 更可靠。因此,简单投票就足够好。
5.5 适用条件
Self-Consistency 最适合这类任务:
- final answer 可以被解析出来。
- final answer 来自相对明确的答案空间。
- 同一问题存在多种可能 reasoning paths。
- 采样能产生足够 diversity。
比如数学题、选择题、yes/no 问题、符号推理都比较适合。
如果是开放式写作任务,final answer 没有明确等价判断,Self-Consistency 就没那么直接。论文也指出,开放生成任务理论上可以扩展,但需要定义“多个答案是否一致”的 metric。
六、实验
6.1 实验设置
论文评估了三类任务。
| 类型 | 数据集 |
|---|---|
| Arithmetic reasoning | AddSub, MultiArith, ASDiv, AQuA, SVAMP, GSM8K |
| Commonsense reasoning | CommonsenseQA, StrategyQA, ARC |
| Symbolic reasoning | Last Letter Concatenation, Coinflip |
模型包括四类:
UL2-20BGPT-3 / Codex code-davinci-001GPT-3 / Codex code-davinci-002LaMDA-137BPaLM-540B
实验不做 training 或 finetuning,只做 prompting-based inference。主实验中,每次独立采样 40 条 outputs,并对结果取平均。
采样设置包括:
- UL2-20B / LaMDA-137B:temperature
T = 0.5,top-kk = 40 - PaLM-540B:temperature
T = 0.7,top-kk = 40 - GPT-3:temperature
T = 0.7,不使用 top-k truncation
6.2 Arithmetic Reasoning 主结果
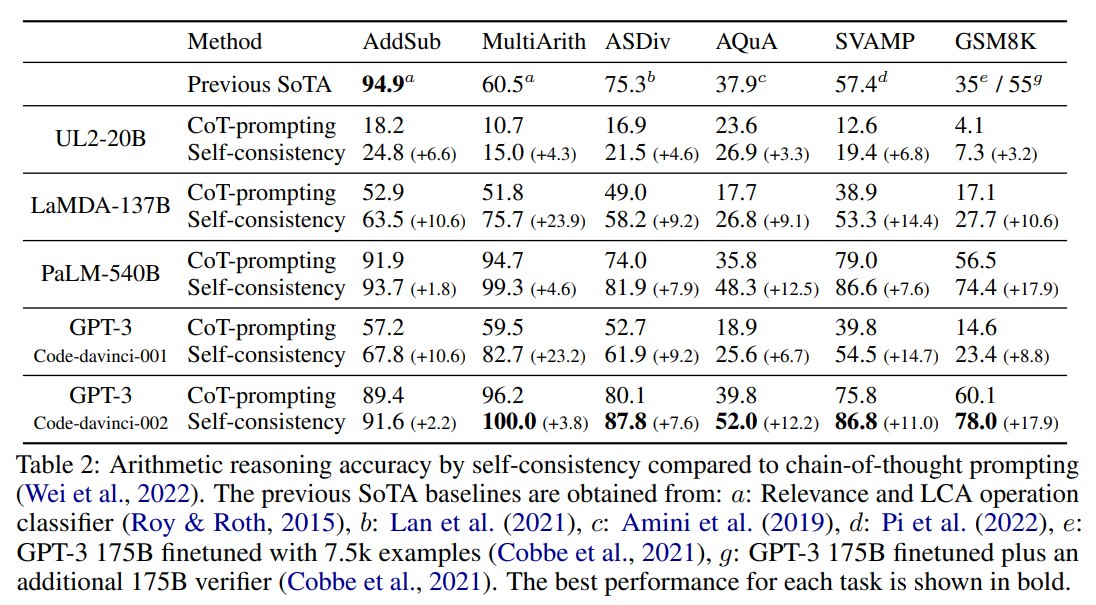
Table 2 显示,Self-Consistency 在算术推理上提升非常明显。
几个关键结果:
| 模型 | 任务 | CoT greedy | Self-Consistency |
|---|---|---|---|
| PaLM-540B | GSM8K | 56.5 | 74.4 (+17.9) |
| PaLM-540B | AQuA | 35.8 | 48.3 (+12.5) |
| Code-davinci-002 | GSM8K | 60.1 | 78.0 (+17.9) |
| Code-davinci-002 | SVAMP | 75.8 | 86.8 (+11.0) |
| LaMDA-137B | MultiArith | 51.8 | 75.7 (+23.9) |
这些数字说明两点:
第一,Self-Consistency 对大模型尤其有效。论文指出,UL2-20B 上提升通常是 +3% 到 +6%,而 LaMDA-137B 和 GPT-3 上可以达到 +9% 到 +23%。
第二,即使 PaLM-540B / GPT-3 已经有较强 CoT 能力,Self-Consistency 仍然能带来额外提升。例如 GSM8K 上 PaLM-540B 从 56.5 -> 74.4 (+17.9)。
6.3 Commonsense 与 Symbolic Reasoning
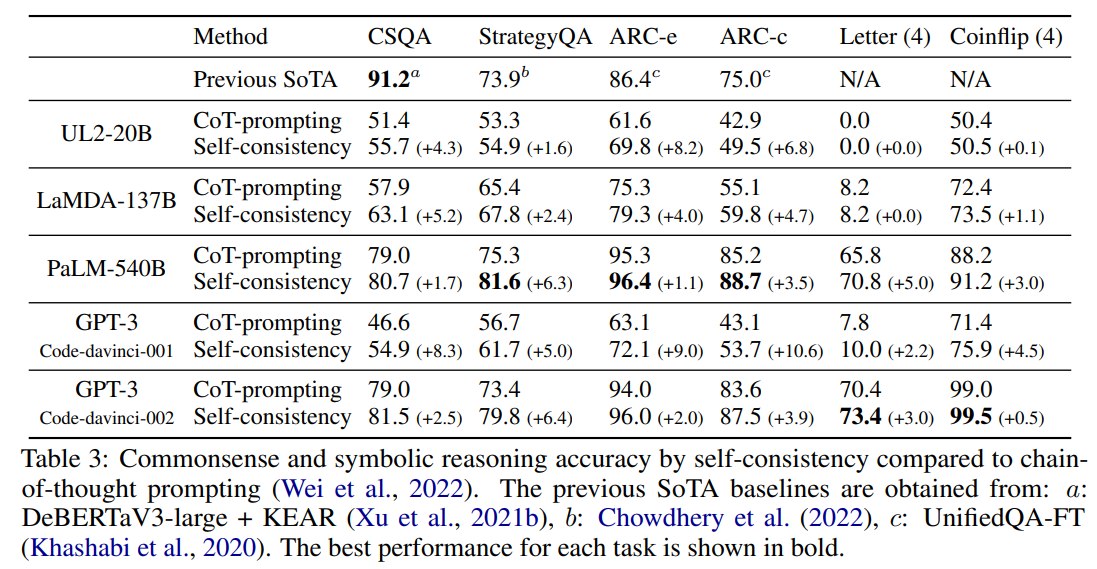
Table 3 显示,Self-Consistency 不只对数学有用,对 commonsense 和 symbolic tasks 也有效。
关键结果:
| 模型 | 任务 | CoT greedy | Self-Consistency |
|---|---|---|---|
| Code-davinci-002 | StrategyQA | 73.4 | 79.8 (+6.4) |
| Code-davinci-002 | ARC-c | 83.6 | 87.5 (+3.9) |
| PaLM-540B | Letter OOD | 65.8 | 70.8 (+5.0) |
| PaLM-540B | Coinflip OOD | 88.2 | 91.2 (+3.0) |
这里的 Letter 和 Coinflip 是 OOD setting:prompt 中是 2 letters 或 2 flips,但测试是 4 letters 或 4 flips。这比 in-distribution 更难,因为模型不能只照搬 prompt 长度。
Self-Consistency 在 OOD symbolic reasoning 上仍然提升,说明它确实利用了多条 sampled reasoning paths 的优势。
6.4 Sample 数量的影响
论文比较了 1, 5, 10, 20, 40 条 sampled reasoning paths。
总体趋势是:sampled paths 越多,accuracy 越高,但提升会逐渐饱和。
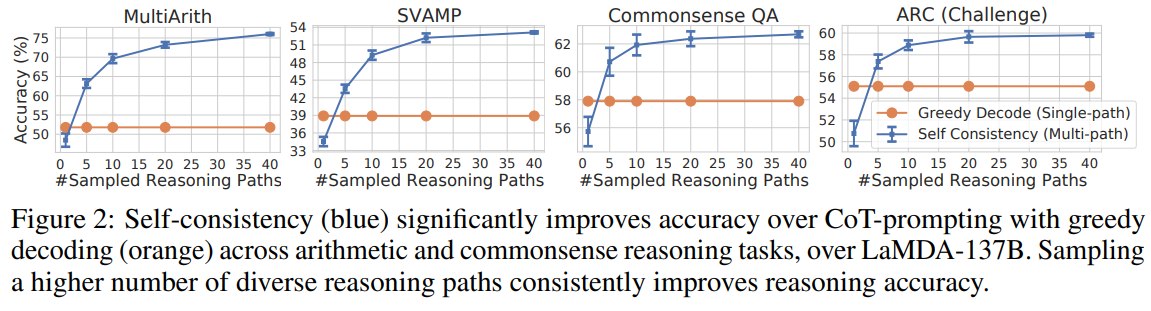
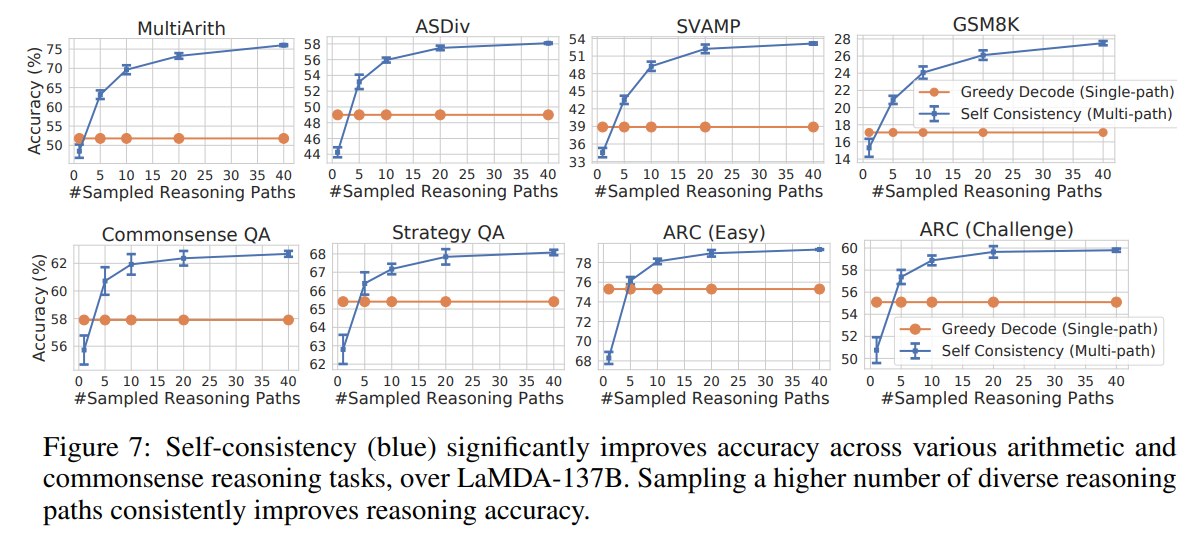
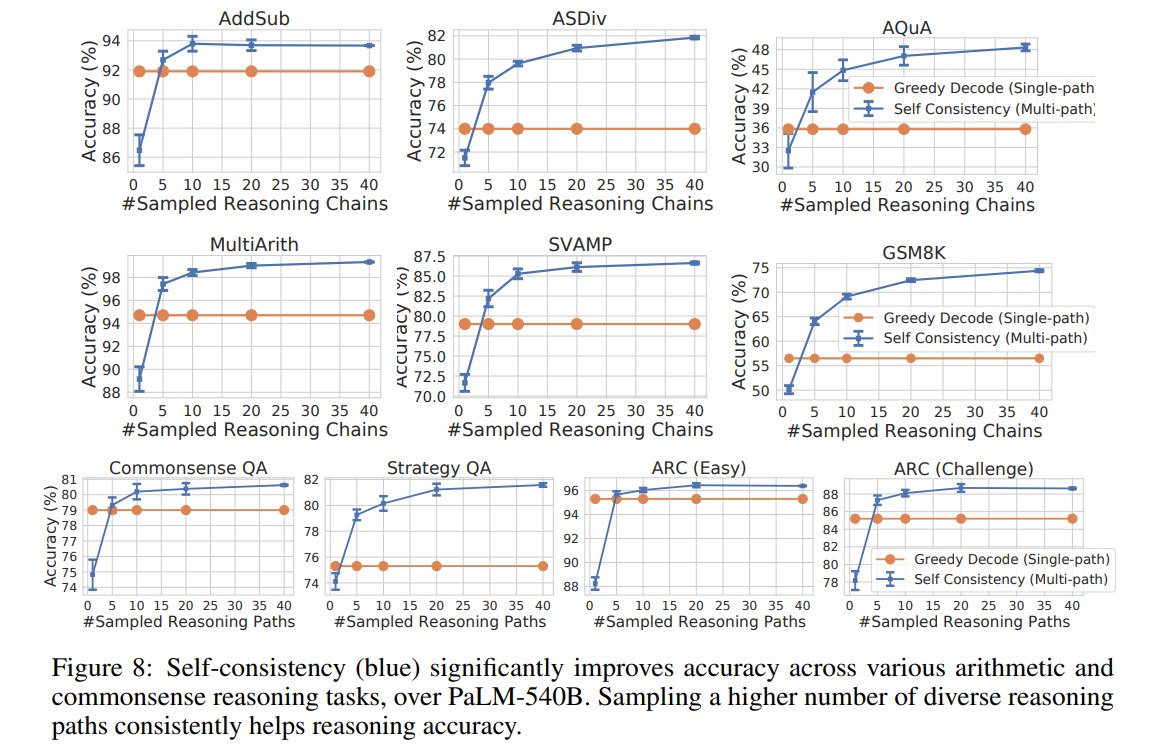
这很好理解:
- 采样 1 条时,本质上接近 single sampled generation,不稳定。
- 采样 5 或 10 条时,已经能捕捉一部分答案共识。
- 采样 40 条时,投票更稳定,但计算成本也更高。
论文在 conclusion 中也建议,实际使用时可以从 5 或 10 条 paths 开始,通常能拿到大部分收益,同时避免太高成本。
6.5 CoT 有时会 hurt,Self-Consistency 能补回来
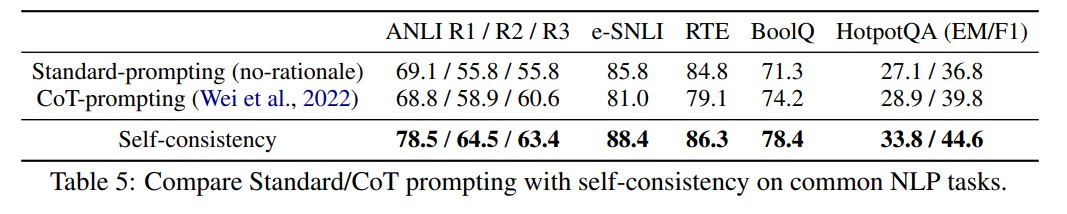
Ye & Durrett 指出,某些 NLP tasks 上 CoT prompting 可能比 standard prompting 更差。论文在 Table 5 中测试了 common NLP tasks,包括:
- ANLI
- e-SNLI
- RTE
- BoolQ
- HotpotQA
结果显示,某些任务上 CoT greedy 确实会 hurt。例如:
| 方法 | e-SNLI | RTE |
|---|---|---|
| Standard prompting | 85.8 | 84.8 |
| CoT prompting | 81.0 | 79.1 |
| Self-Consistency | 88.4 | 86.3 |
这说明,直接加 rationale 不一定总是好;如果只生成一条错误或不稳定 rationale,可能伤害结果。但 Self-Consistency 通过多路径投票,能把 CoT 的风险降低,并超过 standard prompting。
6.6 与 Sample-and-Rank 对比
sample-and-rank 会采样多个 outputs,然后选 log probability 最高的一条。
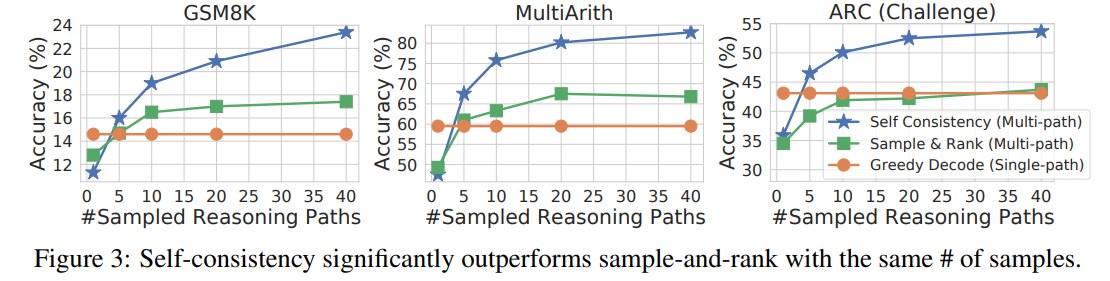
论文在 Figure 3 中比较了 sample-and-rank 和 Self-Consistency。结论是:sample-and-rank 虽然比 greedy 有一些提升,但远低于 Self-Consistency。
原因是:高概率 path 不等于正确 path。
模型可能对错误推理也很自信。因此,只按模型概率选 top-ranked sequence,不如对 final answers 做 consistency voting。
6.7 与 Beam Search 对比
Table 6 比较了 beam search 和 Self-Consistency。
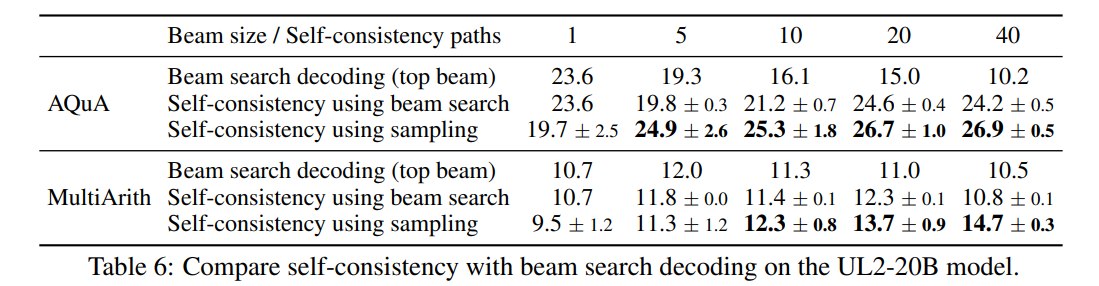
在 UL2-20B 上,AQuA 任务中:
- beam search top beam 从 beam size
1到40并没有变好,甚至从23.6降到10.2。 - Self-Consistency using sampling 在
40paths 时达到26.9。
MultiArith 上也类似:
- beam search top beam 在
40beams 时为10.5。 - Self-Consistency using sampling 在
40paths 时为14.7。
这说明 beam search 的多 beams 不等于真正多样的 reasoning paths。它可能只是围绕高概率局部区域展开,缺乏不同解法。
6.8 与 Ensemble 对比
论文比较了几类 ensemble。
第一类是 prompt-level ensemble:
- 3 sets of prompts
- 40 prompt permutations
Table 7 在 LaMDA-137B 上显示:

Self-Consistency 的提升明显更大。
第二类是 model ensemble。Table 10 显示:
Single model PaLM-540B, greedy / self-consistency: 56.5 / 74.4
而多个模型 ensemble 在 GSM8K 上明显更差,例如 LaMDA-137B + PaLM-540B 只有 36.9。原因是弱模型会拖累强模型。
Table 11 还显示,Self-Consistency 可以和 prompt ensemble 结合:

主要增益仍然来自 Self-Consistency 本身。
6.9 Robustness:采样策略、prompt、equation、Zero-Shot-CoT
论文做了很多 robustness 分析。
第一,Self-Consistency 对 sampling parameters 比较鲁棒。它在不同 temperature、top-k、nucleus sampling 设置下都能提升。关键不是某个特定采样参数,而是要产生足够 diverse reasoning paths。
第二,它对不同 prompt sets 也鲁棒。Table 9 在 PaLM-540B 的 GSM8K 上显示:
| Prompt set | CoT | Self-Consistency |
|---|---|---|
| Prompt set 1 | 56.5 | 74.4 (+17.9) |
| Prompt set 2 | 54.6 | 72.1 (+17.5) |
| Prompt set 3 | 54.0 | 70.4 (+16.4) |
换成完整的提升形式就是:56.5 -> 74.4、54.6 -> 72.1、54.0 -> 70.4。这说明 Self-Consistency 的收益并不依赖某一组特别幸运的 prompts。
第三,它能缓解 imperfect prompts。Table 8 中:
Correct CoT prompt: 17.1
Imperfect CoT prompt: 14.9
Imperfect CoT prompt + Self-consistency: 23.4
也就是 imperfect CoT prompt 会让 greedy decoding 从 17.1 -> 14.9,但加 Self-Consistency 后能到 23.4。
第四,它也能用于 equation prompts:
Equation prompts: 5.0 -> 6.5
不过提升较小,因为 equation reasoning paths 较短,采样时能产生的 diversity 更少。
第五,它也能和 Zero-Shot-CoT 结合。Table 8 显示:
PaLM-540B Zero-shot CoT: 43.0 -> 69.2 (+26.2)
这点很重要:Self-Consistency 不只适用于 few-shot CoT,也适用于 Zero-Shot-CoT。
6.10 Consistency 还能做 uncertainty estimate
论文还观察到,consistency 和 accuracy 高度相关。
也就是说,如果 40 条 sampled paths 中有很多条都投同一个答案,那么模型更可能答对;如果投票很分散,模型可能没把握。
因此,Self-Consistency 不只提升准确率,还可以提供一种粗略的 uncertainty estimate:
一致性高 -> 模型更有信心
一致性低 -> 模型可能不确定
这对后续 agent、tool use、human review 都很有启发。如果模型内部投票很分散,就可以触发更多搜索、更多计算或人工检查。
6.11 Limitations
论文明确指出一个主要局限:Self-Consistency increases computation cost.
如果采样 40 条 paths,推理成本大约就是单条路径的很多倍。实际使用时可以从 5 或 10 条 paths 开始,因为很多任务上性能会较快饱和。
另一个局限是 reasoning paths 可能并不真实或 factual。论文提到,模型有时会生成 incorrect 或 nonsensical reasoning paths。例如 StrategyQA 中,路径可能引用不准确的人口数字,但最后答案可能仍然正确。
因此,Self-Consistency 提升的是 answer accuracy,不保证每条 rationale 都真实可靠。
七、总结和展望
7.1 论文贡献
这篇论文的核心贡献可以总结为四点。
第一,提出 Self-Consistency,用多条 sampled reasoning paths 替代单条 greedy path。
第二,把 CoT reasoning 的 decoding 从:
choose the most likely path
改成:
choose the most consistent answer
第三,在多个 arithmetic、commonsense、symbolic reasoning benchmarks 上显著提升 CoT performance。
第四,展示 Self-Consistency 不需要额外训练、额外 verifier、额外人工标注,可以直接叠加到已有 CoT / Zero-Shot-CoT 上。
7.2 局限
Self-Consistency 的主要局限是计算成本。
如果采样 m 条 paths,推理成本大致随 m 增加。对 API 调用、长上下文、多模态输入来说,这个成本可能很明显。
第二,它依赖 answer extraction。如果 final answer 解析不稳定,投票也会受影响。
第三,它只在 final answer 层面做 consistency,不保证 rationale 本身正确。多个错误 reasoning paths 也有可能收敛到同一个错误答案。
第四,对于开放式生成任务,如果没有明确答案空间,就需要额外定义 consistency metric。
7.3 和现代 reasoning model / RL 的关系
现代 reasoning models 常常强调 test-time compute、long thinking、best-of-N、verifier、reward model、RL 等概念。Self-Consistency 是理解这些方法的一个很好的入口。
它已经包含了几个现代推理系统常见思想:
multiple samples:不只生成一次。answer aggregation:对多个候选答案聚合。implicit verification:不用外部 verifier,而用一致性作为弱验证信号。test-time compute:用更多推理计算换更高准确率。uncertainty estimate:用投票分散程度估计模型不确定性。
区别是,Self-Consistency 的 verifier 很弱,只是 majority vote;后续很多系统会加入更强的 process reward model、outcome reward model、tool execution 或 formal verifier。

说些什么吧!