
零、写在前面
B站上有论文一作作者做的汇报:MiniGPT-4、表格推理、代码生成、生成式推理-来自斯坦福、北大、阿卜杜拉、达摩院的四位论文一作思辨大模型。大概十几分钟就能了解清楚本文的动机、技术路线。
MiniGPT-4 和 BLIP-2 的架构几乎一样,只是把llm侧用了更强的Vicuna(一个基于 LLaMA 微调的开源模型)。
本文提出 把一个 frozen visual encoder 与 frozen advanced LLM Vicuna 对齐,中间只训练一个 projection layer 就可以释放llm的视觉对话能力。
一、标题
MINIGPT-4: ENHANCING VISION-LANGUAGE UNDERSTANDING WITH ADVANCED LARGE LANGUAGE MODELS
标题其实就表明本文在探索复现 GPT-4 展示过的视觉-语言生成能力的方式。
二、摘要
摘要从 GPT-4 的多模态展示切入:GPT-4 能从手写草图生成网站,也能理解图像中的幽默元素,这些能力在以前的 vision-language models 中很少出现。但 GPT-4 的技术细节没有公开,因此作者提出一个假设:GPT-4 的增强型多模态生成能力可能来自 sophisticated LLM 的使用。
为了检验这个假设,论文提出 MiniGPT-4。它把一个 frozen visual encoder 与 frozen advanced LLM Vicuna 对齐,中间只训练一个 projection layer。摘要强调两个核心发现:
- 如果把视觉特征正确对齐到强 LLM,模型可以表现出类似 GPT-4 demo 的多模态能力,例如详细图像描述和根据手绘草图创建网站。
- 仅用短 caption pairs 训练会导致不自然输出,例如重复、句子碎片、无关内容;因此作者第二阶段构造详细图像描述数据来微调模型,从而提升生成可靠性和可用性。
三、引言
引言从 LLM 的快速发展写起。GPT-3、ChatGPT、LLaMA、Vicuna 等模型已经在纯文本任务上表现出很强的 zero-shot 和 instruction following 能力;GPT-4 进一步展示了图像描述、异常现象解释、从手写文本生成网页等视觉语言能力。
但 GPT-4 的方法没有公开,因此开源社区需要一个可研究的替代系统。

论文的核心假设是:GPT-4 式多模态能力可能来自 LLM 的 emergent abilities。当语言模型足够强时,它已经会写诗、写网页、解释笑话、生成菜谱、组织事实知识;如果视觉模块能把图像内容转换成 LLM 可用的信息,那么这些语言侧能力就可能与视觉理解组合,形成图像条件下的新任务能力。
MiniGPT-4 的设计因此非常克制:
- 语言侧使用 Vicuna。Vicuna 基于 LLaMA,并被报告在 GPT-4 评测中达到接近 ChatGPT 的质量。
- 视觉侧使用 BLIP-2 的预训练视觉组件,包括 EVA-CLIP 的 ViT-G/14 与 Q-Former。
- 中间只加入一个 single projection layer,把视觉特征对齐到 Vicuna 的语言空间。
- 训练时冻结视觉编码器和 LLM,只训练 projection layer。
- 第一阶段用 LAION、Conceptual Captions、SBU 等图文 caption 数据训练 20k steps,batch size 256,覆盖约 5M image-text pairs。
- 第二阶段额外收集约 3,500 个高质量 detailed image description pairs,并配合 conversational template 做微调。
引言最后列出了三点主要发现:
- 将视觉特征与 Vicuna 这类 advanced LLM 对齐后,MiniGPT-4 能获得类似 GPT-4 demo 的高级视觉语言能力。
- 只训练一个 projection layer 就能有效完成视觉编码器与 LLM 的对齐,训练成本约为 4 张 A100 训练 10 小时。
- 只用短 caption pairs 做对齐不足以得到好用的视觉聊天模型,会导致不自然语言输出;少量高质量详细描述数据能显著提升可用性。
引言的关键洞察在于,作者没有把多模态问题理解成“必须从头训练一个大视觉语言模型”,而是把它拆成两个已经存在的能力:视觉表征和语言生成。MiniGPT-4 的任务就是学习一个足够好的连接器,让 frozen visual encoder 的输出进入 frozen LLM 的上下文。
四、相关工作
相关工作分成两条主线。
第一条是 large language models。论文回顾了 BERT、GPT-2、T5、GPT-3、Chinchilla、PaLM、OPT、BLOOM、LLaMA 等模型,并强调 scaling 带来的 emergent abilities。InstructGPT、ChatGPT、Alpaca、Vicuna 则说明预训练 LLM 经过 instruction tuning 或人类意图对齐后,可以更自然地与用户对话。
这条线为 MiniGPT-4 的语言侧选择服务:如果复杂语言能力来自强 LLM,那么视觉语言模型不一定需要重新学习写诗、写网页、解释笑话等能力,只需要让 LLM 看见图像信息。
第二条是 leveraging pre-trained LLMs in vision-language tasks。论文提到 VisualGPT、Frozen、Flamingo、BLIP-2、PaLM-E、GPT-4 等工作。这里最关键的参照是 Flamingo 和 BLIP-2:
- Flamingo 用 gated cross-attention 对齐视觉编码器和语言模型,并在海量图文数据上训练,展示了强 few-shot vision-language learning 能力。
- BLIP-2 使用 Q-Former 高效连接 frozen vision foundation model 和 LLM,说明冻结大模型并训练桥接模块是一条有效路线。
- PaLM-E 将真实世界连续传感器模态接入 LLM,代表更大规模的 embodied / multimodal LLM 方向。
论文还区分了另一类系统:Visual ChatGPT、MM-REACT、ChatCaptioner、ViperGPT 等把 ChatGPT 作为协调器,让它调用外部视觉模型或程序来解决复杂视觉问题。MiniGPT-4 与它们不同:它不是工具编排系统,而是直接把视觉信息对齐到语言模型内部,让 LLM 自身生成多模态回答。
这个定位很重要。MiniGPT-4 的贡献不在于提出复杂的新视觉模块,而在于证明:在 BLIP-2-style 视觉编码器和 Vicuna 之间加入一个很小的可训练连接器,就能让 LLM 直接承担多种视觉语言生成任务。
五、Method
MiniGPT-4 的方法可以概括为一句话:冻结一个强视觉编码器,冻结一个强语言模型,只训练一个线性投影层,把视觉特征作为 soft prompt 注入 LLM。
5.1 总体架构
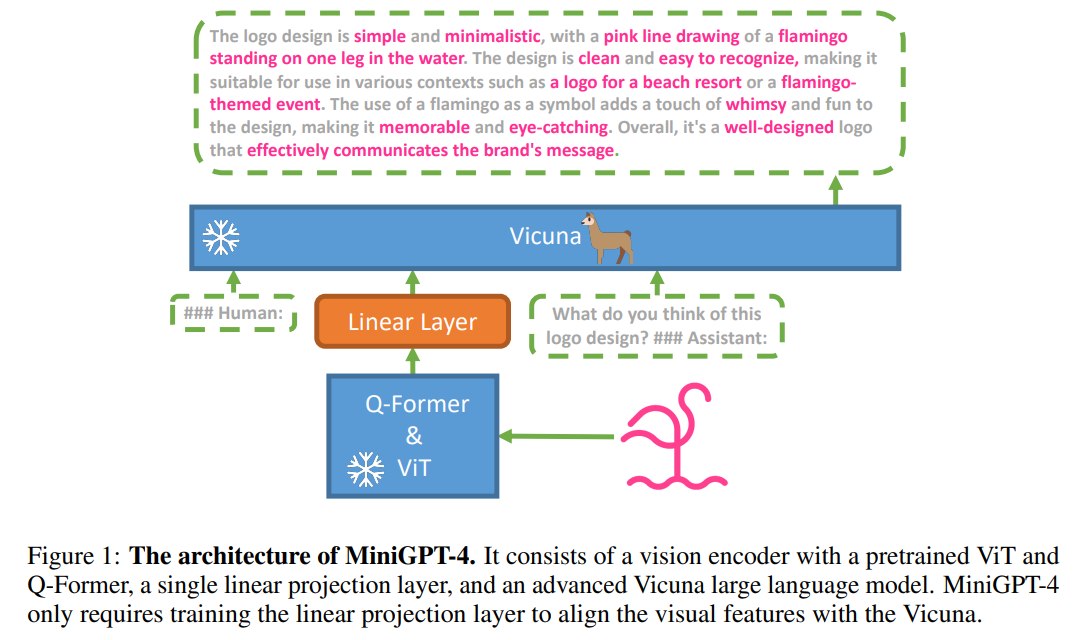
模型包含三部分:
-
视觉编码器与 Q-Former
论文使用 BLIP-2 的视觉模块:EVA-CLIP 的 ViT-G/14 作为视觉 backbone,并配合预训练 Q-Former 提取适合语言模型消费的视觉表示。 -
单线性投影层
这是 MiniGPT-4 唯一主要训练的桥接模块。它把视觉模块输出映射到 Vicuna 的 embedding space。作者把 projection layer 输出看作 LLM 的 soft prompt。 -
Vicuna LLM
Vicuna 作为语言 decoder,负责根据视觉 soft prompt 和用户指令生成自然语言回答。训练中 Vicuna 保持 frozen。
这种结构的最强假设是:视觉特征不需要通过复杂多层 adapter 才能接入 LLM;在已有强视觉表征和强 LLM 的前提下,一个线性投影层可能已经足够完成跨模态空间对齐。
5.2 stage-1:大规模图文对齐预训练
第一阶段的目标是让 projection layer 学会基本 vision-language knowledge。训练时:
- frozen visual encoder;
- frozen Vicuna;
- 只训练 linear projection layer;
- 数据来自 Conceptual Captions、SBU、LAION 的组合;
- 共训练 20,000 steps;
- batch size 为 256;
- 覆盖约 5 million image-text pairs;
- 训练成本约为 4 张 A100 80GB GPU 训练 10 小时。
训练形式上,projection layer 输出被当作 soft prompt,促使 LLM 生成对应 ground-truth texts。这个阶段相当于让 LLM 学会“看到”图像的基本语义。
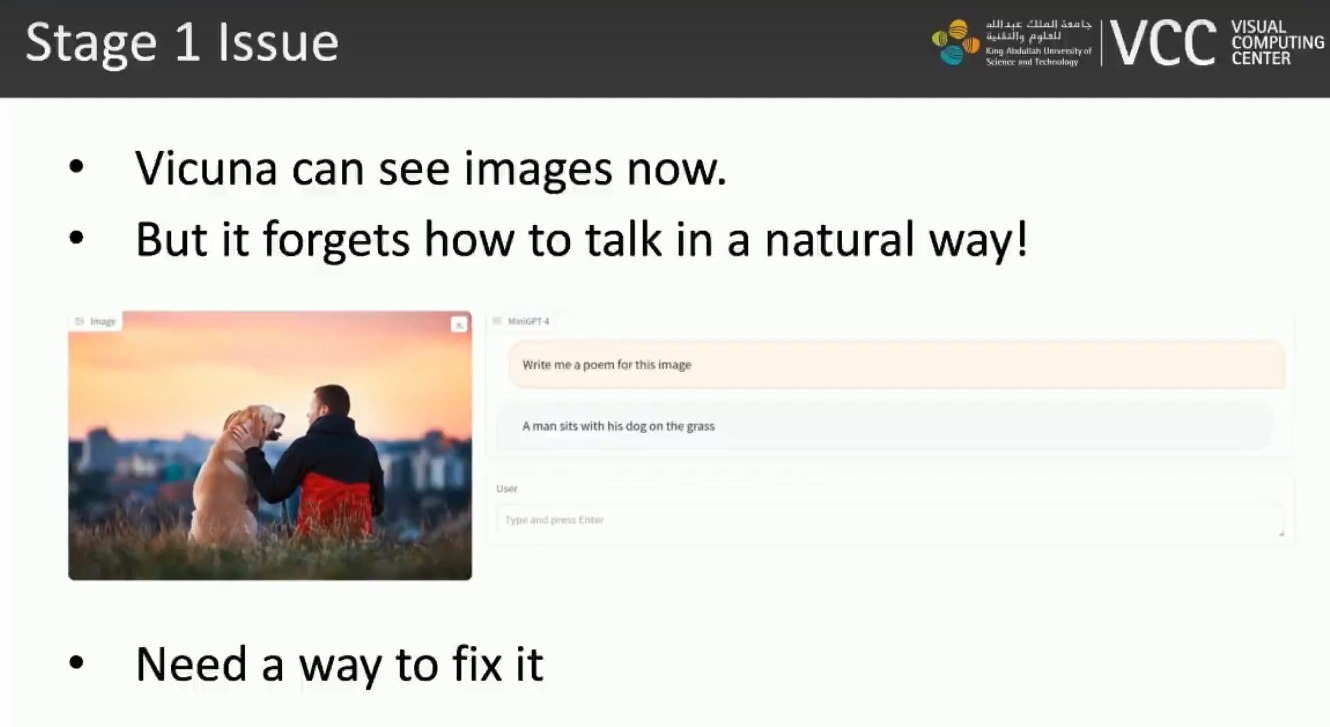
但第一阶段后模型存在明显问题:**虽然能回答一些问题,也有一定视觉语言知识,但输出会出现重复词句、句子碎片、不相关内容等不自然现象。**论文把这类问题类比到 GPT-3 到 InstructGPT / ChatGPT 的转变:纯预训练并不等于符合用户意图的对话模型,仍然需要 alignment。
5.3 stage-2:高质量详细描述数据对齐
第二阶段的动机是提升语言自然性、可靠性和交互可用性。视觉语言领域当时缺少类似 Alpaca / ShareGPT 那样易得的 instruction tuning 数据,因此作者构造了一批 detailed image description pairs。

数据构造流程是:
- 从 Conceptual Captions 中随机选择 5,000 张图像。
- 用第一阶段模型根据 prompt 生成详细图像描述。prompt 采用 Vicuna 对话格式,例如:
###Human: <Img><ImageFeature></Img> Describe this image in detail... ###Assistant:。 - 如果生成句子少于 80 tokens,则追加
###Human: Continue ###Assistant:让模型继续生成,并拼接两步输出。 - 使用 ChatGPT 修复自动生成描述中的重复、无意义字符、非英文句子和不完整句子。
- 通过规则过滤常见错误,例如 “I’m sorry I made a mistake…” 或 “I apologize…” 等异常回答。
- 人工进一步检查和清理冗余内容。
- 最终保留约 3,500 个高质量 image-text pairs。
第二阶段微调使用预定义 prompt template:###Human: <Img><ImageFeature></Img> <Instruction> ###Assistant:。其中 <Instruction> 从多个同义描述指令中随机采样,例如 “Describe this image in detail” 或 “Could you describe the contents of this image for me”。论文特别说明,不对 text-image prompt 本身计算 regression loss。
这个阶段非常轻量:batch size 12,训练 400 steps,单张 A100 约 7 分钟。结果是模型语言输出更自然、可靠,显著减少第一阶段后的重复和碎片化问题。
5.4 为什么一个线性层可能足够
MiniGPT-4 的设计成立依赖三个前提:
- 视觉侧已经足够强。 BLIP-2 的视觉模块已经在大规模图文数据中学习到较好的视觉语义表示。
- 语言侧已经足够强。 Vicuna 已经具备指令跟随、文本组织、常识推理和多种生成风格。
- 跨模态映射主要是接口问题。 如果视觉表示已经抽象到语义层面,那么 projection layer 不需要从像素学习语义,只需要把视觉 token 映射到 LLM 能利用的 embedding distribution。
因此,MiniGPT-4 的“极简”并不是从零开始极简,而是建立在强 pretrained components 之上。它真正训练的是组件之间的接口,而不是完整多模态能力本身。
六、实验
6.1 定性能力展示

MiniGPT-4 展示了多种传统 VLM 较少覆盖的任务:
- 详细图像描述;
- meme 幽默解释;
- 根据商品图撰写广告文案;
- 根据电影照片检索事实信息;
- 根据食物图片生成菜谱;
- 诊断植物问题并给出建议;
- 根据手写草图生成网站;
- 根据图像写诗。
论文多次与 BLIP-2 对比。作者认为 BLIP-2 使用相对较弱的 Flan-T5 XXL 作为语言模型,因此难以完成 meme explanation、website coding、poem writing 等需要复杂语言生成和开放知识组织的任务;MiniGPT-4 使用 Vicuna 后,这些能力更容易出现。
这里的关键不是 MiniGPT-4 真正学过 image-to-poem 或 sketch-to-website 数据,而是 LLM 已经会写诗、写代码、解释笑话;视觉输入只提供任务所需的图像条件。论文在 discussion 中把这解释为 compositional generalization。
6.2 Advanced vision-language tasks 小规模评测
为了量化高级视觉语言任务,作者构造了 100 张图像的小评测集,包含四类任务:
| 任务 | Prompt / 问题 | 每类图像数 |
|---|---|---|
| Meme interpretation | Explain why this meme is funny. | 25 |
| Recipe generation | How should I make something like this? | 25 |
| Advertisement creation | Help me draft a professional advertisement for this. | 25 |
| Poem composition | Can you craft a beautiful poem about this image? | 25 |
人工评估生成是否满足请求。结果显示 BLIP-2 总体只成功 5/100,而 MiniGPT-4 成功 65/100。其中 MiniGPT-4 在 recipe、advertisement、poem 上接近 80% 成功,在 meme 上为 8/25。
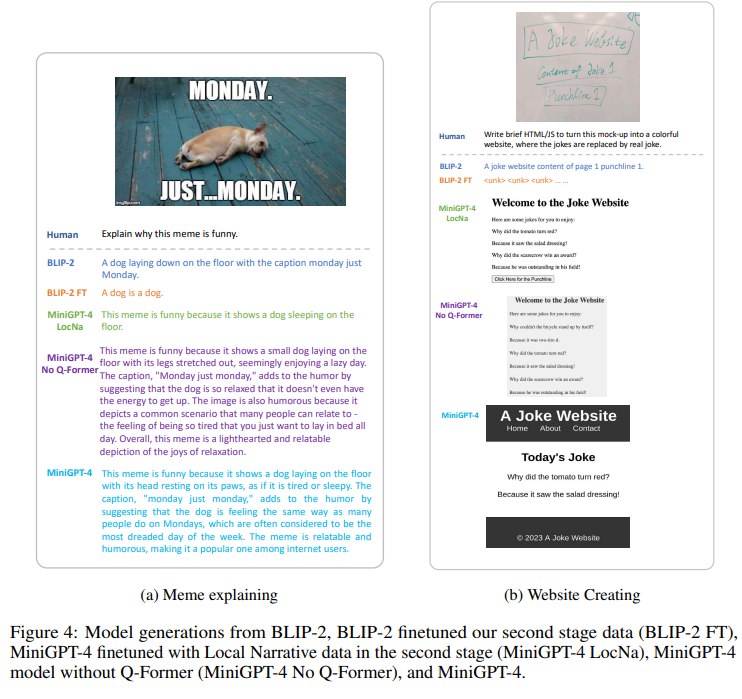
这个结果支持 MiniGPT-4 在开放式生成任务上明显强于 BLIP-2,但也要注意评测规模很小、任务定义较主观、成功标准依赖人工判断。因此它更适合作为早期能力证据,而不是完整 benchmark 结论。
6.3 COCO caption evaluation
论文还在 COCO caption 上做了量化比较。由于 MiniGPT-4 生成的 caption 更长、更细,传统 n-gram similarity metrics 不适合评价,因此作者用 ChatGPT 判断生成 caption 是否覆盖 ground-truth caption 中的对象和关系。
结果为:
| 模型 | Correctness | Percentage |
|---|---|---|
| BLIP-2 | 1376/5000 | 27.5% |
| MiniGPT-4 | 3310/5000 | 66.2% |
这个结果说明 MiniGPT-4 更擅长生成覆盖更多视觉对象和关系的详细描述。但评估方式也引入了一个问题:ChatGPT judge 本身不是标准 caption metric,判断是否覆盖所有对象和关系可能受 prompt 和模型偏差影响。附录给出了评估 prompt,要求 ChatGPT 只回答 yes/no,这增强了可复现性,但仍不等同于人工标注的严格评测。
6.4 第二阶段微调的效果
第二阶段微调是论文中较有说服力的实验之一。作者随机采样 100 张 COCO test images,比较第一阶段后模型和第二阶段后模型在两个任务上的 failure rate:详细描述生成和写诗。
| Failure rate | Detailed caption | Poem |
|---|---|---|
| Before stage-2 | 35% | 32% |
| After stage-2 | 2% | 1% |
这说明少量高质量 detailed image description pairs 对输出可用性影响很大。第一阶段模型已经有视觉语言知识,但语言形态不稳定;第二阶段并没有大幅扩充世界知识,而是恢复 / 对齐了 LLM 的自然语言生成方式。
作者还用 Localized Narratives 替换自构造第二阶段数据,得到 MiniGPT-4 LocNa。它能生成较长描述,但表达单调,在 meme explanation 等复杂任务上的泛化不如原版 MiniGPT-4。这个对比强调:第二阶段数据不只是“长”,还需要自然、多样、符合对话场景。
6.5 架构消融
论文测试了三种架构变体:
- 去掉 Q-Former,直接映射 ViT 输出到 Vicuna embedding space;
- 使用三层线性层而不是一层;
- 额外 finetune Q-Former。
AOK-VQA 和 GQA 上的结果显示,去掉 Q-Former 的变体与原始设计接近,而三层 projection 和 finetune Q-Former 反而略差。作者据此认为,在有限训练数据设置下,单线性层足以对齐 vision encoder 和 LLM;Q-Former 对 advanced skills 并非关键。
这个结论需要谨慎理解。它并不意味着 Q-Former 对所有 LVLM 都不重要,而是说明在 MiniGPT-4 的实验条件中,更复杂的 bridge 没有带来更好效果。可能原因包括训练数据太少、额外参数更难优化、强 LLM 已经能吸收投影后的语义特征,或者 benchmark 与 qualitative skills 对 bridge 复杂度不敏感。
6.6 传统 VQA benchmark 附录结果
作者把这一部分放在了附录,正文的实验部分放的是比较fancy的小众测试结果hh。
**附录明确说明,MiniGPT-4 的目标不是传统视觉 benchmark。**它只训练一个线性层,并且只使用 5M image-text pairs;相比之下,BLIP-2 使用 129M image-text pairs。因此原始 MiniGPT-4 在 AOK-VQA 和 GQA 上落后于 BLIP-2 是预期内的。
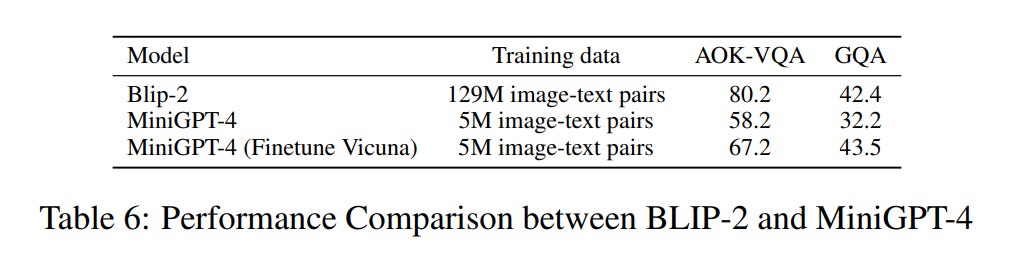
附录进一步用 LoRA unfreeze LLM 并加入 VQAv2、OKVQA、A-OKVQA 等更多训练数据,显示传统 benchmark 表现可以明显提升。例如 MiniGPT-4 从 AOK-VQA 58.2 / GQA 32.2 提升到 67.2 / 43.5。这说明 MiniGPT-4 的基础设计有扩展潜力,但原论文刻意保持 minimal setting,以突出 advanced multimodal demo 能力。
七、Limitations
论文主动讨论了两个主要局限:hallucination 和 spatial information understanding。
7.1 Hallucination
MiniGPT-4 建立在 LLM 之上,因此继承了 LLM 幻觉问题。论文例子显示,模型会错误地说图像中存在 white tablecloths。作者使用 $CHAIR_i$ 衡量 hallucination,并比较长短描述:
| 模型 / Prompt | $CHAIR_i$ | Avg. Length |
|---|---|---|
| BLIP-2 | 1.3 | 6.5 |
| MiniGPT-4 (short) | 7.2 | 28.8 |
| MiniGPT-4 (long) | 9.6 | 175 |
结果说明,描述越长,覆盖信息越多,但幻觉风险也越高。BLIP-2 短 caption 幻觉更少,但对象覆盖也更少;MiniGPT-4 详细描述能提供丰富内容,却更容易编造不存在的细节。
这揭示了 LVLM 的一个基本 trade-off:开放式生成越强,语言模型越倾向于补全和推断;如果视觉 grounding 不够强,生成流畅性会掩盖事实错误。
7.2 Spatial information understanding
MiniGPT-4 的空间理解也有限。论文例子中,模型不能正确定位 windows 的位置。作者认为这可能源于缺少为空间信息理解设计的 aligned image-text data,并提出 RefCOCO、Visual Genome 等数据可能缓解问题。
这个局限与架构有关。MiniGPT-4 把视觉信息压缩后作为 soft prompt 输入 Vicuna,并没有显式输出 bounding box,也没有 position-aware adapter 或 grounding objective。因此,它更擅长全局语义描述和开放式语言生成,不擅长细粒度定位、计数、空间关系和 OCR-like 任务。
7.3 评测体系不足
除了论文明确局限,还可以补充一个方法论层面的局限:MiniGPT-4 的核心能力证据较依赖定性 demo 和小规模人工评测。它证明了路线的可行性,但没有建立完整 benchmark suite 来衡量多模态对话能力。
这在 2023 年早期 LVLM 语境下可以理解。当时领域正在快速探索“把 LLM 接上视觉”会出现什么能力,demo 本身具有启发意义。但从后续 Qwen-VL、LLaVA-1.5、Qwen2-VL 等模型发展看,系统性评测、OCR、grounding、document/chart、多图、多语言等能力会越来越重要。

说些什么吧!