
零、写在前面
CLIP 这篇文章的工作很厉害也很有趣,利用自然语言作为监督学习,进行图文对比学习,学习图片和文本在共享语义空间中的匹配关系。然后在下游任务中即使是 zero-shot 也能取得很好的效果。
CLIP 打破了之前固定种类数据集预训练的范式,只需要有图片文本的配对,然后去做无监督训练计算相似性或者去生成之类的任务就行了。而且用单个模型就可以在很多任务上取得很好的zero-shot 的结果,泛化性非常好。
一、标题
Learning Transferable Visual Models From Natural Language Supervision
从自然语言监督中学习可迁移的视觉模型。作者来自OpenAI团队。
二、引言
Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision.
CLIP(Contrastive Language-Image Pre-training),核心目标是让视觉模型摆脱传统图像分类中“固定类别标签”的限制,转而从自然语言监督中学习更通用、可迁移的视觉表示。
研究动机:传统视觉监督太受限
传统计算机视觉模型通常被训练为预测一个预先定义好的类别集合,例如 ImageNet 的 1000 类。这种方式有两个问题:
- 泛化能力有限:模型只能识别训练标签中出现过的类别。
- 使用不灵活:如果要识别新的视觉概念,通常需要重新收集标注数据并训练模型。
论文认为,互联网上大量的图像-文本对包含丰富的视觉语义信息,可以作为一种更广泛、更自然的监督来源。
Method:用图像-文本匹配进行预训练
CLIP 的预训练任务非常简单:
- 给定一批图像和文本描述;
- 模型需要判断哪段文本与哪张图像匹配;
- 通过这种方式,同时训练:
- 一个 图像编码器;
- 一个 文本编码器;
- 让匹配的图像和文本在嵌入空间中更接近,不匹配的更远。
论文使用了来自互联网的 4 亿个图像-文本对进行训练。
CLIP 训练完成后,不需要针对下游任务重新训练分类头,而是可以用自然语言描述类别,例如:
- “a photo of a dog”
- “a photo of a car”
- “a satellite photo of a forest”
模型通过比较图像与这些文本描述的相似度来完成分类。
这使得 CLIP 具备 **零样本迁移(zero-shot transfer)**能力:即在没有使用目标数据集训练样本的情况下,直接迁移到新任务。
实验结果:覆盖广泛任务,表现接近监督模型
作者在 30 多个计算机视觉数据集上评估 CLIP,任务包括:
- OCR;
- 视频动作识别;
- 地理定位;
- 细粒度图像分类;
- 通用图像分类等。
结果显示,CLIP 在多数任务上都能实现非平凡迁移,并且经常可以与全监督基线模型竞争。
也就是说,CLIP 在 没有使用 ImageNet 的 128 万训练样本的情况下,零样本达到原始 ResNet-50 在 ImageNet 上的准确率。
CLIP 将计算机视觉从传统的“固定类别分类”推进到了更灵活的 **开放词汇视觉识别(open-vocabulary visual recognition)**范式。
三、引言
3.1 传统视觉监督的问题
论文开篇指出,当时主流的计算机视觉系统通常被训练为预测一组预先定义好的固定类别。例如,一个 ImageNet 分类器被训练为在 1000 个类别中选择答案。这种范式很成功,但也有明显限制:
- 类别空间固定:模型只能识别训练标签集合中定义过的概念。
- 迁移需要额外标注数据:如果要识别新类别或新任务,通常需要收集新数据并训练新的分类头或微调模型。
- 监督形式过窄:人工标注的 1-of-N 类别标签虽然干净,但表达能力远弱于自然语言。
- 输出接口不灵活:固定 softmax 分类器无法动态适配用户用语言提出的新视觉概念。
这意味着传统视觉模型虽然在封闭 benchmark 上表现强,但其“可用性”和“通用性”受到限制。它们更像是为特定数据集训练出来的专家系统,而不是能用自然语言理解任务需求的通用视觉模型。
3.2 NLP 预训练范式对视觉的启发
CLIP 的问题意识明显受到 NLP 大模型发展的启发。论文提到,NLP 中的任务无关预训练目标,例如自回归语言建模和 masked language modeling,已经展示出很强的可扩展性。GPT 系列进一步说明,当模型、数据和算力扩大后,模型可以通过统一的文本接口在多个任务上进行 zero-shot 或 few-shot 迁移。
作者由此提出一个自然问题:
如果大规模文本预训练可以让语言模型获得通用迁移能力,那么计算机视觉是否也能从 web-scale 的自然语言监督中获得类似突破?
这里的关键是,互联网上存在大量图片及其相关文本,例如标题、描述、alt text、网页上下文等。这些文本虽然噪声大,却覆盖了远比人工标签更丰富的视觉概念。与其让模型只学习“这张图片属于 1000 个 ImageNet 类别中的哪一个”,不如让模型学习“这张图片和哪段自然语言描述匹配”。
2.3 CLIP
论文要解决的问题可以表述为:能否直接利用大规模互联网图文对中的自然语言监督,训练出能够迁移到多种视觉任务的通用视觉模型?
围绕这个问题,CLIP 的主要工作包括:
-
构建大规模图文预训练数据集 WIT
- 作者收集了约 400 million 个图文对,称为 WebImageText(WIT)。
- 数据来自公开互联网资源,并通过约 500,000 个查询词覆盖广泛视觉概念。
-
采用高效的图文对比学习目标
- 模型不生成 caption,而是判断 batch 内哪张图片与哪段文字真实配对。
- 这种目标比逐词生成文本更高效,适合大规模训练。
-
训练双编码器结构
- 图像编码器负责把图片映射到视觉嵌入。
- 文本编码器负责把自然语言描述映射到文本嵌入。
- 两者在共享多模态嵌入空间中通过相似度进行匹配。
-
实现自然语言驱动的 zero-shot 分类
- 下游类别不再需要训练分类头,而是被写成文本 prompt,例如 “a photo of a dog”。
- 文本编码器把类别描述编码成分类器权重,图像编码器输出图像特征,二者相似度最高的类别即为预测结果。
-
系统评估迁移、表征和鲁棒性
- 论文在 30 多个视觉数据集上评估 CLIP,覆盖 OCR、动作识别、地理定位、细粒度分类等任务。
- 结果显示,CLIP zero-shot 在 ImageNet 上达到 76.2% top-1 accuracy,匹配原始 ResNet-50,且不使用 ImageNet 的 1.28 million 训练样本。
需要注意,论文并没有声称 CLIP 完全解决视觉泛化问题。相反,作者在实验和局限性部分明确指出:CLIP 在许多细粒度、抽象、真正分布外任务上仍然明显不足。
四、模型
4.1 整体框架:图像编码器 + 文本编码器
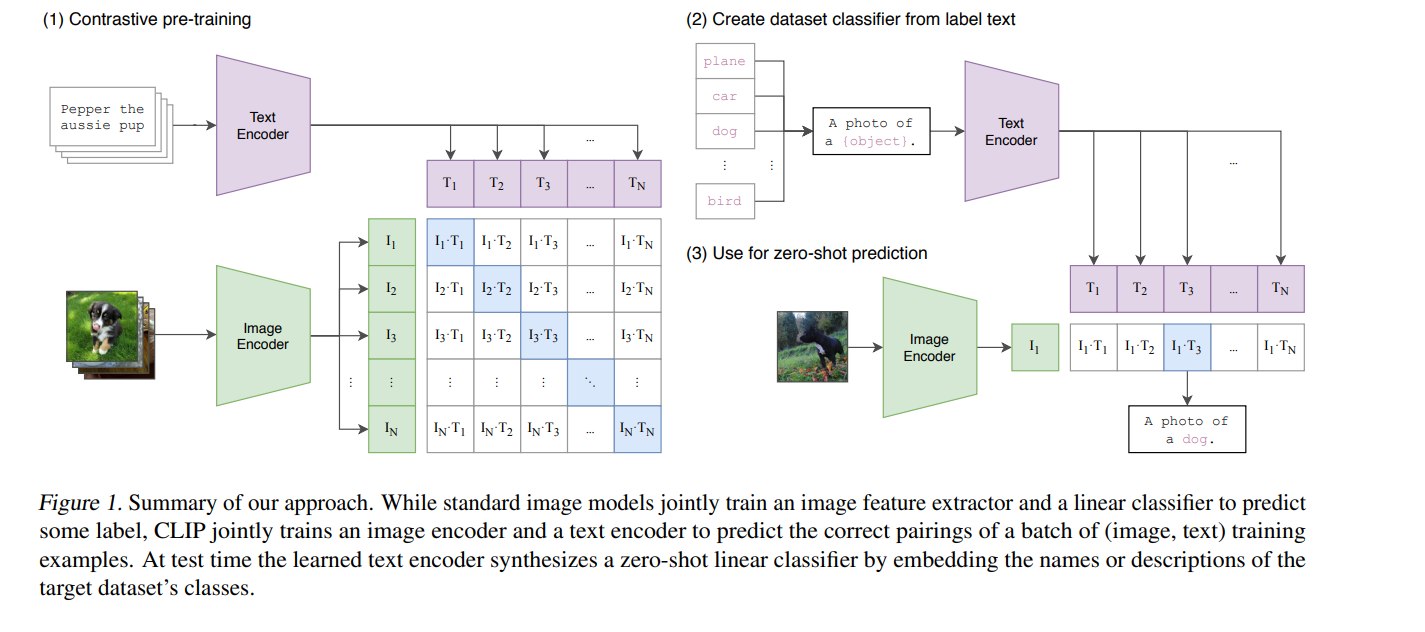
CLIP 是一个双编码器架构:
- 图像编码器(Image Encoder):输入图片,输出图像向量。
- 文本编码器(Text Encoder):输入文本,输出文本向量。
- 共享嵌入空间:图像向量和文本向量被投影到同一个多模态空间中,通过 cosine similarity 判断匹配程度。
与早期视觉语言模型不同,CLIP 并不使用复杂的跨模态 attention 来让图片 token 和文本 token 深度交互。论文明确指出,CLIP 中图像和文本之间的交互非常简单:在共享嵌入空间中做一次余弦相似度计算。
这种设计有两个重要好处:
- 训练和检索效率高:图片和文本可以分别编码,适合大规模图文匹配。
- 迁移接口清晰:文本编码器可以把任意类别描述转化为分类器权重,使下游任务可以由自然语言定义。
从架构角度看,CLIP 并不是“视觉问答模型”或“图文生成模型”,而是一个通过图文匹配训练出来的通用表征模型。
4.2 训练目标:图文对比学习
CLIP 的训练目标是整篇论文的技术核心。给定一个 batch,其中包含 N 个真实图文对,模型会计算所有图片和所有文本之间的相似度,形成一个 N×N 相似度矩阵:
- 对角线上的 N 个元素是真实图文配对。
- 非对角线上的 N²−N 个元素是错误配对。
训练时,CLIP 要做到:
- 提高真实图文对的相似度。
- 降低错误图文对的相似度。
- 同时优化 image-to-text 和 text-to-image 两个方向的分类损失。
可以把训练过程理解为:
-
输入:一个 batch 的 N 个图文对
-
用图像编码器编码 N 张图片
-
用文本编码器编码 N 段文本
-
计算 N×N 的图文相似度矩阵
-
对每张图片,预测哪段文本与它匹配
-
对每段文本,预测哪张图片与它匹配
-
用对称交叉熵优化两个方向的匹配结果
这里的对称交叉熵就是对最终得到的那个矩阵,分别以图片角度和文本角度求一次交叉熵,然后二者加起来求平均。
事实上,论文还给出了CLIP实现伪代码:

论文指出,这类目标与 deep metric learning 中的 multi-class N-pair loss、对比学习中的 InfoNCE loss 有关系。其关键优势在于:模型不需要生成文本中的每个词,只需要判断整体图文配对是否正确,因此训练效率更高。
论文中的效率消融显示:相比图像条件语言模型式的 caption 预测,CLIP 这种对比目标在 ImageNet zero-shot 迁移学习速度上显著更快。作者先发现逐词生成 caption 学得较慢,又发现 bag-of-words 预测更快,最终发现对比学习目标进一步带来约 4 倍效率提升。

4.3 数据:WIT 400M 图文对
CLIP 使用的数据集称为 WIT(WebImageText),包含约 400 million 个互联网图文对。
论文强调,已有图文数据集不足以支撑这种研究:
- MS-COCO 和 Visual Genome 质量较高,但规模只有约 100,000 训练图片量级。
- YFCC100M 虽然规模较大,但元数据稀疏且质量参差不齐;过滤出英文自然语言标题或描述后只剩约 15 million 图片。
因此,作者构建了新的 WIT 数据集。为了覆盖更广视觉概念,他们使用约 500,000 个查询词寻找图文对,并对每个查询最多保留 20,000 个样本,以避免少数高频概念支配数据集。
这里要注意两点:
- WIT 不是人工精标数据集:它来自互联网,包含噪声、偏差和不完整描述。
- 自然语言监督不是无监督:图片旁边的文本仍然提供监督信号,只是监督形式不再是固定类别标签。
CLIP 的成功很大程度上来自这种“弱噪声但大规模”的监督形式。它牺牲了单个标签的干净程度,换来了概念覆盖范围和语言接口的灵活性。
4.4 编码器设计与训练规模
论文实验了两类图像编码器:
-
ResNet 系列
- 以 ResNet-50 为基础。
- 采用 ResNet-D 改进和 antialiased blur pooling。
- 将原始 global average pooling 替换为 attention pooling。
- 训练了 RN50、RN101、RN50x4、RN50x16、RN50x64 等规模。
-
Vision Transformer(ViT)系列
- 包括 ViT-B/32、ViT-B/16、ViT-L/14。
- 对原始 ViT 做了较小修改,例如在 patch embedding 和 position embedding 组合后增加 layer normalization。
- 最强模型为 ViT-L/14,并在 336px 分辨率上额外预训练一轮,记为 ViT-L/14@336px。
文本编码器是 Transformer:
- base 版本约 63M 参数。
- 12 层、宽度 512、8 个 attention heads。
- 使用 lower-cased byte pair encoding,词表大小 49,152。
- 最大文本长度为 76。
- 使用最后一层
[EOS]token 的表示作为文本特征,并投影到多模态嵌入空间。
训练方面,论文给出了非常关键的尺度信息:
- 所有模型训练 32 epochs。
- minibatch size 为 32,768。
- 使用 Adam、decoupled weight decay、cosine learning rate schedule。
- 最大 ResNet 模型 RN50x64 在 592 张 V100 上训练 18 天。
- 最大 ViT 模型在 256 张 V100 上训练 12 天。
这些数字说明,CLIP 的突破并不是低成本实现的。它的范式简洁,但依赖大规模数据和大规模算力。
3.5 Zero-shot 分类如何实现
CLIP 的 zero-shot 分类机制是论文最具影响力的部分。它把一个图像分类任务转化为图文匹配任务。
假设某个数据集有 K 个类别,例如 dog、cat、car。CLIP 不训练新的分类头,而是执行如下步骤:
- 将每个类别名称写成自然语言 prompt,例如:
- “a photo of a dog”
- “a photo of a cat”
- “a photo of a car”
- 用文本编码器编码这 K 个类别描述,得到 K 个文本向量。
- 用图像编码器编码待分类图片,得到图像向量。
- 计算图像向量与每个文本向量的相似度。
- 选择相似度最高的文本类别作为预测结果。
论文给出了一个很重要的解释:从分类器角度看,CLIP 的文本编码器可以被理解为一个 hypernetwork(超网络),它根据类别的自然语言描述动态生成线性分类器的权重。
这就是 CLIP 与传统分类器的根本差异:
- 传统模型的分类器权重来自训练数据中的固定类别。
- CLIP 的分类器权重来自文本编码器对类别描述的编码。
因此,CLIP 的类别空间不是训练时固定死的,而是在推理时由用户通过语言指定。
3.6 Prompt Engineering 与 Prompt Ensembling
论文特别强调,zero-shot 并不意味着“直接把类别名扔给模型就完事”。类别名本身可能有歧义,也可能和预训练时的文本分布不一致。
例如:
- “crane” 可能指起重机,也可能指鹤。
- “boxer” 在 Oxford-IIIT Pets 中指一种狗,但单独看也可能指拳击手。
- 训练数据中的文本通常是完整描述,而不是孤立的单词标签。
为了解决这个问题,作者使用 prompt template。例如默认模板:
a photo of a {label}
这个简单模板在 ImageNet 上相比只使用类别名提升了 1.3% accuracy。进一步地,作者会针对任务定制 prompt:
- 宠物分类:强调 “a type of pet”。
- 食物分类:强调 “a type of food”。
- 飞机分类:强调 “a type of aircraft”。
- OCR 任务:对要识别的字符或数字加引号。
- 卫星图像:使用 “a satellite photo of …” 这样的上下文。
此外,论文还使用 prompt ensembling:为同一个类别构造多个 prompt,将它们的文本嵌入在 embedding space 中平均。ImageNet 上,作者 ensemble 了 80 个不同 prompt,在默认 prompt 基础上又提升 3.5%。整体来看,prompt engineering 和 ensembling 在 36 个数据集上平均提升接近 5 points。
这说明 CLIP 的语言接口非常灵活,但也带来一个边界:zero-shot 性能依赖任务如何被语言表达。 这不是传统意义上完全免人工设计的迁移,而是把任务设计从“标注样本和训练分类器”转移到了“设计类别描述和 prompt”。
五、实验
5.1 Zero-shot Transfer
论文将 zero-shot transfer 用作衡量 CLIP 是否真的学会“任务”的核心评估方式。这里的 zero-shot 不仅指传统意义上识别未见过的类别,还更广泛地指:模型不使用下游数据集训练样本,直接迁移到未专门训练过的数据集和任务。
CLIP 在 30 多个数据集上被评估,任务类型包括:
- 通用物体分类:ImageNet、CIFAR、STL10 等。
- 细粒度分类:Stanford Cars、Food101、Oxford Pets、Birdsnap、FGVC Aircraft 等。
- OCR:Rendered SST2 等。
- 动作识别:UCF101、Kinetics700。
- 地理定位:Country211。
- 医学和抽象任务:PatchCamelyon、CLEVR Counts 等。
结果显示,CLIP 的 zero-shot 能力并非只在单一数据集上有效。它在许多任务上可以达到非平凡甚至竞争性的表现,但不同任务之间差异很大。
5.2 与 Visual N-Grams 和 ResNet-50 的比较
论文首先与 Visual N-Grams 进行比较。Visual N-Grams 是此前少数研究“通用预训练模型 zero-shot 迁移到标准视觉分类数据集”的工作之一。
在三个数据集上,论文报告了如下对比:
| 方法 | aYahoo | ImageNet | SUN |
|---|---|---|---|
| Visual N-Grams | 72.4 | 11.5 | 23.0 |
| CLIP | 98.4 | 76.2 | 58.5 |
其中最受关注的是 ImageNet:CLIP zero-shot top-1 accuracy 达到 76.2%,匹配原始 ResNet-50,并且不使用 ImageNet 的 1.28 million 训练样本。CLIP 的 top-5 accuracy 也达到 95%,匹配 Inception-V4。
大佬们还是很谦虚的,声明这不是一个严格受控的直接方法比较。CLIP 与 Visual N-Grams 在数据规模、模型算力、训练算力和架构年代上都有巨大差异。因此,这个结果更适合作为历史定位:CLIP 把自然语言监督的 zero-shot 视觉分类从 proof-of-concept 推到了实际可用的水平。
论文还将 zero-shot CLIP 与 ResNet-50 feature 上训练的监督 logistic regression 分类器比较。在 27 个数据集中,zero-shot CLIP 赢了 16 个。这说明 CLIP 的 zero-shot 分类器已经能在不少任务上接近甚至超过一个经典监督视觉基线。
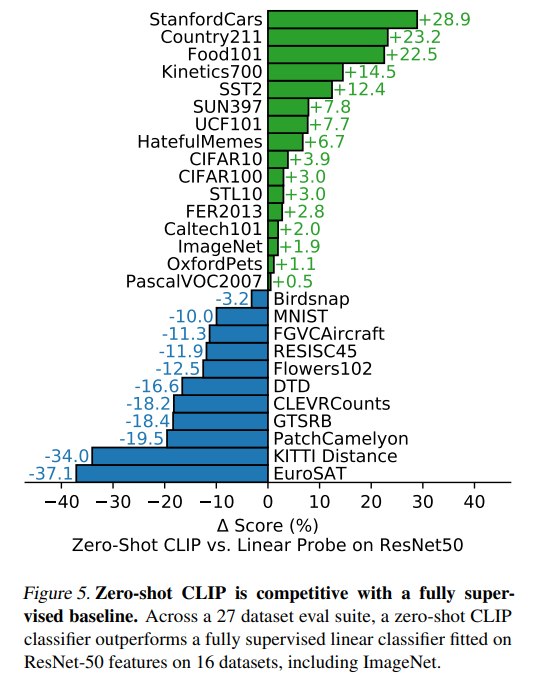
不过,具体任务差异很大:
- 在 Stanford Cars、Food101 等任务上,zero-shot CLIP 明显优于 ResNet-50 特征线性分类器。
- 在 Flowers102、FGVC Aircraft 等任务上,zero-shot CLIP 明显落后。
- 在 EuroSAT、RESISC45、PatchCamelyon、CLEVR Counts、GTSRB、KITTI Distance 等任务上,CLIP 表现较弱。
这说明 CLIP 的 zero-shot 能力高度依赖预训练数据中是否存在足够相关的视觉语言监督,也依赖任务是否容易用文本类别描述清楚。
5.3 Prompt Engineering 的作用
实验表明,prompt engineering 是 CLIP zero-shot 性能的重要组成部分,而不是可有可无的小技巧。
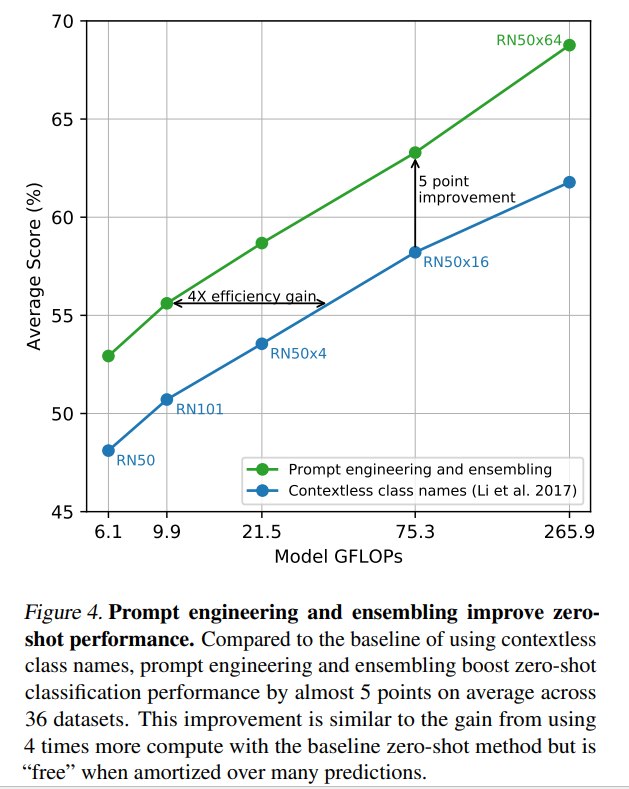
论文指出,很多视觉数据集在设计时并没有考虑自然语言 zero-shot 迁移。类别名称往往只是附带的英文字符串,甚至有些数据集发布版本中没有完整类别名映射。类别名还可能存在多义性,导致文本编码器无法判断其具体含义。
因此,prompt 有两个作用:
- 消除歧义:通过上下文指定类别含义。
- 缩小训练-测试文本分布差异:CLIP 预训练看到的文本通常是自然描述,而不是孤立标签。
在 ImageNet 上:
- “a photo of a {label}” 比直接使用类别名提升 1.3%。
- 80 个 prompt 的 ensembling 进一步提升 3.5%。
- prompt engineering + ensembling 合计带来接近 5% 的提升。
这也带来一个重要方法论启示:评价 CLIP 时,不能只看模型结构和预训练数据,还必须关注任务如何被语言化。CLIP 的下游迁移能力由视觉表征、文本表征和 prompt 设计共同决定。
5.4 Representation Learning:Linear Probe
除了 zero-shot,论文还用 linear probe(线性探测) 评估 CLIP 图像表征质量。Linear probe 的做法是:冻结预训练图像编码器,只在其输出特征上训练一个线性分类器。
作者选择 linear probe 而不是 end-to-end fine-tuning,主要有几个原因:
- linear probe 更直接反映预训练表征本身的质量。
- fine-tuning 可能掩盖预训练表征中的缺陷。
- CLIP 的 zero-shot 分类器本质上也类似一个线性分类器,因此 linear probe 便于和 zero-shot 对比。
- 在 66 个模型、27 个数据集上做 fine-tuning 成本很高且难以公平比较。
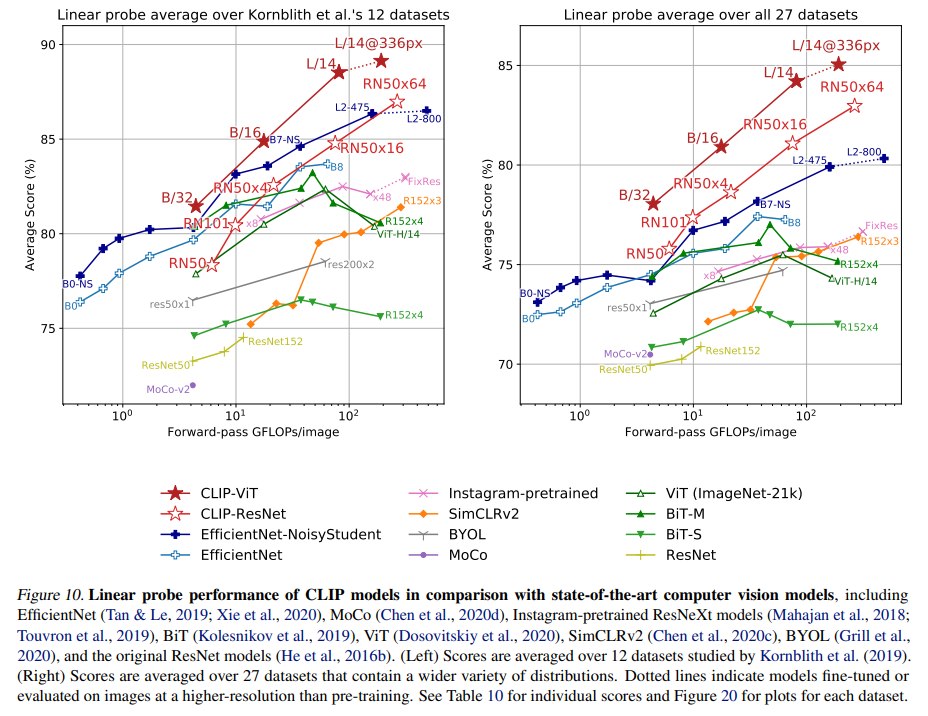
实验结论包括:
- 小规模 CLIP 模型能超过 ImageNet-1K 训练的原始 ResNet 或 BiT-S,但不一定超过 ImageNet-21K 或 EfficientNet 系列强模型。
- 随着规模扩大,CLIP 表征质量提升明显。
- 最大的 CLIP ResNet 模型 RN50x64 在 12 数据集评估上略超过 Noisy Student EfficientNet-L2。
- CLIP 的 ViT 比 CLIP ResNet 约 3 倍 compute efficient,因此在同等算力预算下达到更好表现。
- 最强模型 ViT-L/14@336px 在 broader 27 dataset suite 上相对前人系统平均提升约 5%。
- 在 27 个数据集上,CLIP 特征训练的线性分类器超过 Noisy Student EfficientNet-L2 的 21 个。
这部分实验说明,CLIP 并不是只靠文本编码器“临时拼出”zero-shot 分类器;它的图像编码器本身也学到了强迁移视觉表征。尤其在 OCR、地理定位、场景识别、动作识别等任务上,CLIP 的自然语言监督比 ImageNet 式类别监督覆盖更广。
5.5 鲁棒性:Natural Distribution Shift
论文的一个重要发现是:zero-shot CLIP 在自然分布迁移下比标准 ImageNet 模型更鲁棒。
这里的 natural distribution shift 指的是来自真实世界新采集或不同来源的数据集,而不是对原图施加噪声、模糊、对抗扰动等合成变化。论文讨论的数据集包括 ImageNetV2、ImageNet Sketch、ObjectNet、ImageNet-A、ImageNet-R、Youtube-BB、ImageNet-Vid 等。
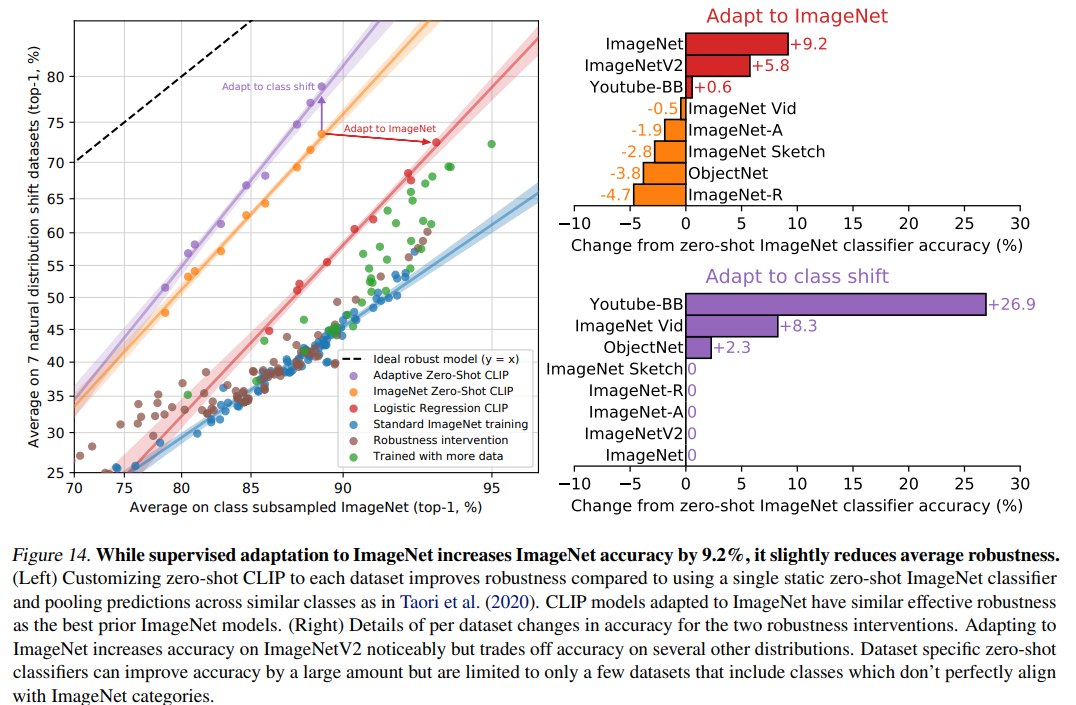
关键结论是:
- 标准 ImageNet 模型在这些自然分布迁移数据集上通常表现显著下降。
- zero-shot CLIP 能显著缩小 ImageNet accuracy 与分布迁移 accuracy 之间的 gap,最多缩小 75%。
- 当作者在 CLIP 特征上用 ImageNet 训练线性分类器时,ImageNet accuracy 提升了 9.2%,达到 85.4%,但平均分布迁移 accuracy 反而略微下降。
这说明,针对 ImageNet 分布做监督适配虽然提高了 ImageNet 内部分布表现,但不一定提升真正分布外表现。论文非常谨慎地指出,这不能直接证明“ImageNet 训练导致鲁棒性 gap”,因为 CLIP 的大规模多样数据和自然语言监督也可能是重要原因。但实验至少说明:zero-shot、任务无关预训练和广泛评估套件可能比单一 benchmark 更能反映模型真实能力。
5.6 人类表现对比与数据重叠分析
论文还做了两个补充分析:人类表现对比和数据重叠分析。
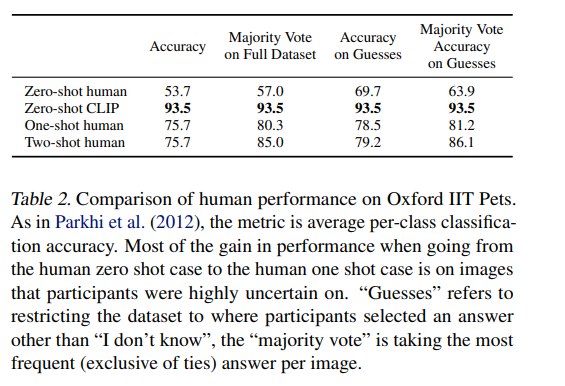
在人类表现部分,作者让 5 名人类在 Oxford-IIIT Pets 上进行 zero-shot、one-shot、two-shot 分类。结果显示:
- zero-shot human 平均 accuracy 为 53.7%。
- zero-shot CLIP 为 93.5%。
- one-shot human 提升到 75.7%。
- two-shot human 仍为 75.7%,但 majority vote 可到 85.0%。
这个实验不能简单解读为“CLIP 比人强”。更准确的理解是:在该特定任务和评价设置下,CLIP 已经从互联网图文预训练中获得了大量相关先验,因此 zero-shot 很强;但人类从 0-shot 到 1-shot 的提升显示出更强的样本效率。论文因此指出,机器 few-shot 方法与人类利用先验知识学习的方式之间仍有明显差距。
数据重叠分析则回应一个关键质疑:CLIP 使用互联网图文对训练,是否可能把评测集图片也看过,从而污染结果?
作者没有在训练前去重所有潜在评测集,而是在训练后检测评测集与训练集的重叠,并比较 overlap subset 与 clean subset 的性能差异。结果显示:
- 35 个数据集中有 9 个没有检测到重叠。
- median overlap 为 2.2%,average overlap 为 3.2%。
- 大多数数据集整体 accuracy 变化不超过 0.1%。
- 检测到的最大整体准确率提升为 Birdsnap 上的 0.6%。
这说明数据重叠可能存在,但在作者的检测和统计分析下,它不足以解释 CLIP 的主要实验结果。当然,论文也承认 duplicate detector 不完美,无法在 400M 训练样本上完全保证召回率。
六、 模型局限性
5.1 与 SOTA 仍有差距
论文明确指出,CLIP 仍有很多限制。虽然 zero-shot CLIP 可以在平均意义上接近 ResNet-50 特征上的简单监督线性分类器,但这个基线已经远低于当时许多任务的 state-of-the-art。
作者估计,如果仅靠 scaling,要让 zero-shot CLIP 达到整体 SOTA 表现,大约需要 1000 倍 训练 compute,而这在当时硬件条件下不可行。因此,未来必须提升 CLIP 的计算效率和数据效率,而不能只依赖继续堆规模。
这一点非常重要:CLIP 展示了自然语言监督的潜力,但论文并没有声称“规模化就是完整答案”。相反,作者认为还需要方法层面的改进。
5.2 细粒度、抽象和真正 OOD 任务不足
CLIP 在不同任务上的表现差异很大。论文明确提到,CLIP zero-shot 在以下任务上较弱:
- 细粒度分类:例如汽车型号、花的品种、飞机变体。
- 抽象和系统性任务:例如 CLEVR 中的对象计数。
- 高度专业任务:例如淋巴结肿瘤检测。
- 新颖任务:例如判断照片中最近汽车的距离。
尤其值得注意的是 MNIST。CLIP 在 Rendered SST2 这类数字渲染文本上可以学到较好的语义 OCR 表征,但在手写数字 MNIST 上 zero-shot accuracy 只有 88%,甚至被 raw pixel logistic regression 这种简单 baseline 超过。作者认为,这是因为 MNIST 这类手写数字图像几乎不出现在 CLIP 预训练数据中。
这说明 CLIP 并没有从根本上解决深度学习的脆弱泛化问题。它更像是通过非常大的、多样化的数据覆盖来把更多任务变成“训练分布内”任务。一旦遇到真正 out-of-distribution 的数据,模型仍然可能失败。
5.3 Prompt 依赖与 zero-shot 边界
CLIP 的一个优势是可以用自然语言生成分类器,但这也是限制。
首先,CLIP 只能在给定 zero-shot classifier 的候选概念中选择答案。它不像 image captioning 模型那样可以自由生成新的描述。因此,CLIP 的开放性并不是无限开放,而是受限于用户提供的类别集合。
其次,很多视觉概念并不容易只用短文本准确指定。例如复杂关系、计数、空间布局、细粒度属性或医学判断,都可能需要示例、上下文或专业知识,而不只是一个类别名。
再次,prompt 设计会显著影响结果。这意味着 CLIP 的 zero-shot 性能并不是完全自动获得的,而依赖人工设计 prompt、类别名称和 label set。论文在 broader impacts 中也强调,class design 会影响模型行为和偏见表现。
5.4 数据、算力与复现成本
CLIP 并没有解决深度学习数据效率差的问题,而是通过可扩展的自然语言监督来补偿这一问题。论文给了一个非常直观的描述:如果以每秒一张图片的速度看完 CLIP 训练过程中见过的 12.8 billion 图片,需要 405 年。
这说明:
- CLIP 的预训练成本非常高。
- WIT 数据集并非公开完整发布,复现实验存在数据门槛。
- 大规模互联网数据包含噪声、偏见和潜在版权、隐私、治理问题。
- 对比学习虽然比 caption generation 高效,但仍依赖巨大 batch 和分布式训练基础设施。
因此,CLIP 更像是证明了一条有效路线,而不是提供了低成本、易复现的通用方案。
5.5 偏见、安全与社会影响
论文的 Broader Impacts 部分非常重要,因为 CLIP 的灵活性会放大部署风险。用户可以通过自然语言快速构造自己的分类器,不需要重新训练模型。这使 CLIP 具备“omni-use” 特征:同一种能力既可用于有益任务,也可用于敏感或有害场景。
论文讨论了几类风险:
-
偏见与表征伤害
- CLIP 训练于未过滤、未策展的互联网图文对,可能学习社会偏见。
- 在 FairFace 相关探测中,加入 “animal”“gorilla”“criminal”“suspicious person”等类别后,模型对不同人群的误分类率存在明显差异。
- 作者特别强调,class design 会显著改变偏见如何显现。
-
监控风险
- CLIP 可以通过自定义类别执行一些监控相关任务,例如 CCTV 场景分类或 celebrity identity recognition。
- 论文发现 CLIP 在粗粒度 CCTV 分类上有非平凡表现,但在细粒度检测上接近随机。
- 对 CelebA 上的 zero-shot celebrity identification,CLIP L/14 在 100 类设置下 top-1 accuracy 为 59.2%,在 1k 类设置下降到 43.3%。
- 论文认为 CLIP 目前相对专门监控模型并不具备全面竞争力,但它降低了构建小众、定制化监控应用的门槛。
-
部署适用性问题
- CLIP 能对几乎任意类别输出概率,但这不意味着任何类别设计都是合理的。
- 高 benchmark accuracy 不等于公平,也不等于适合真实部署。
- 模型使用场景需要具体分析,不能因为 zero-shot 灵活就默认安全可用。
这部分提醒我们:CLIP 的技术创新并不只是提高了视觉识别能力,也改变了“谁能构造视觉分类器”和“构造分类器有多容易”。这种能力转移带来的社会影响必须和模型性能一起评估。
七、结论和总结
论文最后的结论很克制:作者研究了能否把 NLP 中 task-agnostic web-scale pre-training 的成功迁移到计算机视觉,结果发现类似行为确实会在视觉领域出现。CLIP 在预训练过程中学会了执行多种任务,并能通过自然语言 prompting 在许多数据集上实现 zero-shot transfer。在足够规模下,这种方法可以与任务特定的监督模型竞争,但仍有很大改进空间。
从我这个蒟蒻学习的角度看,CLIP 的意义可以总结为四点:
-
监督信号的改变
- 从人工固定标签转向互联网自然语言。
- 视觉模型不再只能学习封闭类别,而可以学习更广泛的视觉语义概念。
-
训练目标的简化
- 不做复杂图文生成,而是做图文匹配。
- 对比学习目标足够简单、稳定、高效,适合规模化。
-
任务接口的语言化
- 文本编码器把类别描述转化为分类器权重。
- 用户可以通过 prompt 指定任务,从而实现开放词汇 zero-shot 视觉分类。
-
评估范式的扩展
- 论文不只看 ImageNet,还系统评估 zero-shot、linear probe、鲁棒性、人类表现、数据重叠和 broader impacts。
- 这种评估方式本身也推动了后来多模态基础模型的研究规范。
CLIP 最值得学习的地方不是某个单独模块,而是它的整体研究判断:当视觉模型获得自然语言接口后,视觉任务可以从“训练一个固定分类器”转变为“用语言描述想识别的概念”。 这为后续开放词汇识别、图文检索、视觉语言模型、文本到图像生成评估、多模态大模型等方向奠定了重要基础。
但同样需要保持清醒:CLIP 的成功建立在大规模数据和算力之上;它在真正 OOD、细粒度、抽象推理和安全公平方面仍有明显限制。更准确地说,CLIP 不是通用视觉智能的终点,而是证明了一个新的起点:自然语言可以成为视觉模型的监督来源,也可以成为视觉任务的交互接口。

说些什么吧!