
零、写在前面
记录一下CS336 assignment1 的实验部分
保证所有test都过了,其他的限于时间就不做了。
作业代码:assignment1
一、Byte-Pair Encoding
1.1 Unicode 与 UTF-8
- Unicode 把字符映射到 code point。
- UTF-8 把 Unicode 字符编码成字节序列。
- byte-level tokenizer 的好处是永远不会出现 OOV(out of vocabulary),因为任意文本都可以表示成 0–255 的字节序列。
但也有一个问题就是,byte-level的tokenizer encode出来太长了,所以第一个实验就是去实现BPE(Byte-Pair Encoding)。
1.2 BPE 训练
1.2.1 BPE思想
BPE的思想很简单:
- 刚开始的vocabulary 就是 256个单字节,然后可能会有一些人为定义的特殊token。
- 然后对于给定文本,统计token词频以及 相邻pair 词频
- 每次选出一个词频最高的pair出来,构造pair为一个新的token
- 然后更新一些用于维护的表(pair的词频,token词频等)
- 因为vocab的size会一直变大,所以当达到目标size的时候就结束
- 特殊 token,如 <|endoftext|>,要作为 hard boundary,不能跨越它合并。
1.2.2 Problem (train_bpe): BPE Tokenizer Training (15 points)
这一部分需要实现adapters.py 中的run_train_bpe函数,该函数就是读取指定路径的文本然后在文本上面训练BPE。
大概说一下我的做法:
- 首先就是初始化vocab为256个单字节token
- 然后把给定的special_tokens加入vocab
- 然后用讲义给定的正则表达式对输入文本进行分词
- 然后就是对文本统计词频以及pair词频
- 然后就该训练了,因为每次取最高频,我用了懒删除堆来实现
- 然后每次从懒删除堆中取出一个best pair,对原来的一些表的更新就写的比较暴力了,应该可以多维护一些信息进一步优化这里我太困了就不做了
def run_train_bpe(
input_path: str | os.PathLike,
vocab_size: int,
special_tokens: list[str],
**kwargs,
) -> tuple[dict[int, bytes], list[tuple[bytes, bytes]]]:
"""Given the path to an input corpus, run train a BPE tokenizer and
output its vocabulary and merges.
Args:
input_path (str | os.PathLike): Path to BPE tokenizer training data.
vocab_size (int): Total number of items in the tokenizer's vocabulary (including special tokens).
special_tokens (list[str]): A list of string special tokens to be added to the tokenizer vocabulary.
These strings will never be split into multiple tokens, and will always be
kept as a single token. If these special tokens occur in the `input_path`,
they are treated as any other string.
Returns:
tuple[dict[int, bytes], list[tuple[bytes, bytes]]]:
vocab:
The trained tokenizer vocabulary, a mapping from int (token ID in the vocabulary)
to bytes (token bytes)
merges:
BPE merges. Each list item is a tuple of bytes (<token1>, <token2>),
representing that <token1> was merged with <token2>.
Merges are ordered by order of creation.
"""
# validation
if not isinstance(vocab_size, int) or vocab_size <= 0:
raise ValueError("vocab_size must be a positive integer")
# -------------------------
# 1. Initialize vocab
# -------------------------
vocab: dict[int, bytes] = {i: bytes([i]) for i in range(256)}
merges: list[tuple[bytes, bytes]] = []
# add special tokens to vocab
cnt_id = 256
token_set = set(vocab.values())
for s in special_tokens:
if len(vocab) >= vocab_size: break
s2bytes = s.encode("utf-8")
if s2bytes not in token_set:
token_set.add(s2bytes)
vocab[cnt_id] = s2bytes
cnt_id += 1
if len(vocab) >= vocab_size:
return vocab, merges
# -------------------------
# 2. Load corpus
# -------------------------
try:
with open(input_path, "r", encoding="utf-8", errors="ignore") as f:
text = f.read() # the whole file
except FileNotFoundError:
text = ""
# -------------------------
# 3. Pretokenization
# -------------------------
chunks = regex.split('|'.join(map(regex.escape, special_tokens)), text)
# re
PAT = r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
token_freq = Counter()
for chunk in chunks:
for word in regex.findall(PAT, chunk):
word_bytes = word.encode("utf-8")
bytes_lst = [bytes([x]) for x in word_bytes] #e.g. ['h', 'e', 'l', 'l', 'o']
token_freq[tuple(bytes_lst)] += 1
# -------------------------
# 4. Initialize pair_freq
# -------------------------
pair_freq: Counter[tuple[bytes, bytes]] = Counter()
for token, freq in token_freq.items():
for l, r in pairwise(token):
pair_freq[(l, r)] += freq
# -------------------------
# 5. Max heap with lazy deletion
# -------------------------
class MaxHeapItem:
def __init__(self, cnt: int, p1: bytes, p2: bytes):
self.cnt = cnt
self.p1 = p1
self.p2 = p2
def __lt__(self, other):
# Python heapq 是小根堆,这里反过来实现大根堆
# tie-breaking: larger pair wins lexicographically
return (self.cnt, self.p1, self.p2) > (other.cnt, other.p1, other.p2)
def __eq__(self, other):
return (self.cnt, self.p1, self.p2) == (other.cnt, other.p1, other.p2)
@property
def pair(self) -> tuple[bytes, bytes]:
return self.p1, self.p2
def __repr__(self):
return f"({self.cnt}, ({self.p1}, {self.p2}))"
# (cnt, p1, p2)
lzheap: list[MaxHeapItem] = []
for (l, r), c in pair_freq.items():
heapq.heappush(lzheap, MaxHeapItem(c, l, r))
# -------------------------
# Helper functions
# -------------------------
def contains_pair(
seq: tuple[bytes, ...],
target_pair: tuple[bytes, bytes],
) -> bool:
for i in range(len(seq) - 1):
if seq[i] == target_pair[0] and seq[i + 1] == target_pair[1]:
return True
return False
# new seq after merge
def merge_seq_once(
seq: tuple[bytes, ...],
target_pair: tuple[bytes, bytes],
) -> tuple[bytes, ...]:
"""
Left-to-right non-overlapping merge.
Example:
seq = (A, A, A), target = (A, A)
result = (AA, A), not (AA, AA)
"""
merged = []
i = 0
while i < len(seq):
if i < len(seq) - 1 \
and seq[i] == target_pair[0] \
and seq[i + 1] == target_pair[1]:
merged.append(seq[i] + seq[i + 1])
i += 2
else:
merged.append(seq[i])
i += 1
return tuple(merged)
# upd pair Counter
def add_pair_count(pair: tuple[bytes, bytes], amount: int):
pair_freq[pair] += amount
def sub_pair_count(pair: tuple[bytes, bytes], amount: int):
new_count = pair_freq[pair] - amount
if new_count <= 0:
del pair_freq[pair]
else:
pair_freq[pair] = new_count
# -------------------------
# 6. Main BPE loop
# -------------------------
while len(vocab) < vocab_size:
best_item = None
while lzheap:
item = heapq.heappop(lzheap)
pair = item.pair
# check
if pair in pair_freq and pair_freq[pair] == item.cnt:
best_item = item
break
if best_item is None:
break
cur_pair = best_item.pair
# record merge
merges.append(cur_pair)
# add new mapping
new_token_bytes = cur_pair[0] + cur_pair[1]
vocab[cnt_id] = new_token_bytes
cnt_id += 1
# all seqs containing cur_pair
affected_seqs = [
seq for seq in token_freq.keys()
if contains_pair(seq, cur_pair)
]
updated_pairs: set[tuple[bytes, bytes]] = set()
new_seq_freq_delta: Counter[tuple[bytes, ...]] = Counter()
for old_seq in affected_seqs:
freq = token_freq[old_seq]
# remove old sequence pair contributions
for old_pair in pairwise(old_seq):
updated_pairs.add(old_pair)
sub_pair_count(old_pair, freq)
# remove old sequence from token_freq
del token_freq[old_seq]
# merge old sequence
new_seq = merge_seq_once(old_seq, cur_pair)
# defer adding new sequence to token_freq
new_seq_freq_delta[new_seq] += freq
# add all new token sequences
for new_seq, freq in new_seq_freq_delta.items():
token_freq[new_seq] += freq
# add new sequence pair contributions
for new_pair in pairwise(new_seq):
updated_pairs.add(new_pair)
add_pair_count(new_pair, freq)
# Push updated true counts into heap
for pair in updated_pairs:
if pair in pair_freq:
heapq.heappush(
lzheap,
MaxHeapItem(pair_freq[pair], pair[0], pair[1]),
)
return (vocab, merges)
测试结果:
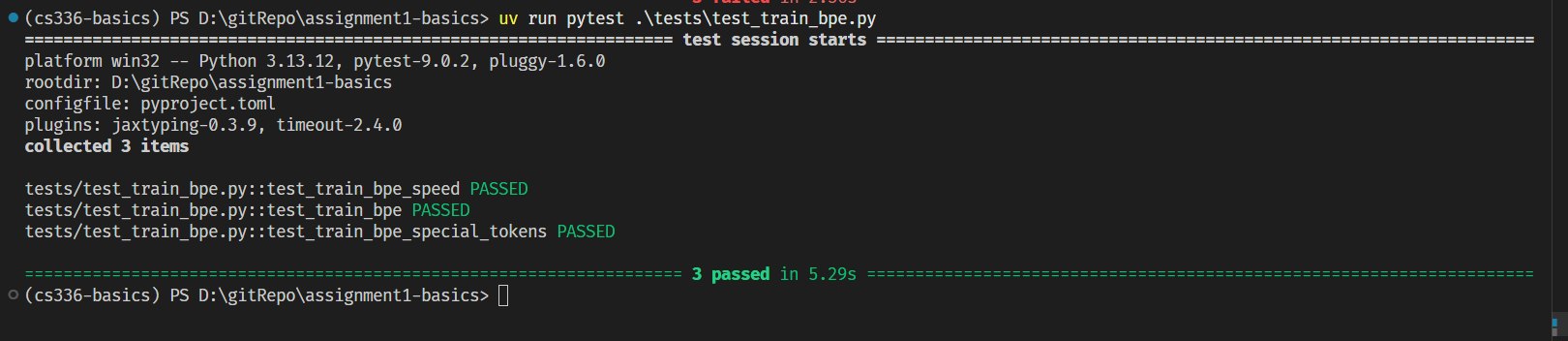
1.3 BPE Tokenizer
1.3.1 Encoding and Decoding
tokenizer做encoding和BPE的训练非常相似:
- Pre-tokenize
- Apply the merges
然后tokenizer要能处理 Special tokens
Memory considerations
然后因为文本可能会很大,我们有必要将文本拆成可以放进内存的chunk。
decoding就是把token ID改回原文本
然后对于不能得到正确Unicode bytes的id,要将其替换成 U+FFFD。
然后讲义还特地说明了一下需要把 bytes.decode 的参数errors置成 ‘replace’
1.3.2 Problem (tokenizer): Implementing the tokenizer (15 points)
这个实验需要在Linux下跑,我这里连的WSL
实现一个 Tokenizer类,然后讲义里面有要实现的接口
具体实现如下:
import json
import ast
import regex
from itertools import pairwise
from typing import Iterable, Iterator
PAT = r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
class Tokenizer:
def __init__(
self,
vocab: dict[int, bytes],
merges: list[tuple[bytes, bytes]],
special_tokens: list[str] = None,
):
self.vocab = dict(vocab)
self.merges = merges
self.special_tokens = special_tokens or []
self.cache = {}
token_set = set(self.vocab.values())
next_id = max(self.vocab.keys()) + 1 if self.vocab else 0
# append user-provided special tokens if they are not already in vocab
for token in self.special_tokens:
token_bytes = token.encode("utf-8")
if token_bytes not in token_set:
self.vocab[next_id] = token_bytes
token_set.add(token_bytes)
next_id += 1
self.bytes2id = {bts: id for id, bts in self.vocab.items()}
self.merge_priority = {merge: i for i, merge in enumerate(self.merges)}
@classmethod
def from_files(
cls,
vocab_filepath: str,
merges_filepath: str,
special_tokens: list[str] = None,
):
def bytes_to_unicode():
bs = (
list(range(ord("!"), ord("~") + 1))
+ list(range(ord("¡"), ord("¬") + 1))
+ list(range(ord("®"), ord("ÿ") + 1))
)
cs = bs[:]
n = 0
for b in range(256):
if b not in bs:
bs.append(b)
cs.append(256 + n)
n += 1
cs = [chr(c) for c in cs]
return dict(zip(bs, cs))
byte_encoder = bytes_to_unicode()
byte_decoder = {v: k for k, v in byte_encoder.items()}
def gpt2_str_to_bytes(s: str):
return bytes(byte_decoder[c] for c in s)
def to_bytes(x):
if isinstance(x, bytes):
return x
if isinstance(x, list):
return bytes(x)
if isinstance(x, int):
return bytes([x])
if isinstance(x, str):
if x.startswith("b'") or x.startswith('b"'):
try:
y = ast.literal_eval(x)
if isinstance(y, bytes):
return y
except Exception:
pass
try:
return gpt2_str_to_bytes(x)
except Exception:
pass
try:
return x.encode("latin-1")
except UnicodeEncodeError:
return x.encode("utf-8")
raise ValueError(f"Cannot convert {x} to bytes")
# load vocab
with open(vocab_filepath, "r", encoding="utf-8") as f:
raw_vocab = json.load(f)
vocab: dict[int, bytes] = {}
if isinstance(raw_vocab, dict):
for k, v in raw_vocab.items():
# format: {"0": [0], "1": [1], ...}
if isinstance(k, str) and k.isdigit():
vocab[int(k)] = to_bytes(v)
# GPT-2 format: {"token": id}
elif isinstance(v, int):
vocab[v] = to_bytes(k)
else:
raise ValueError("Unsupported vocab format")
elif isinstance(raw_vocab, list):
# format: [[0, [0]], [1, [1]], ...]
for item in raw_vocab:
if isinstance(item, list) and len(item) == 2:
idx, token = item
vocab[int(idx)] = to_bytes(token)
else:
raise ValueError("Unsupported vocab format")
else:
raise ValueError("Unsupported vocab format")
# load merges
merges: list[tuple[bytes, bytes]] = []
with open(merges_filepath, "r", encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
line = line.strip()
if not line:
continue
# GPT-2 merges.txt 第一行通常是版本声明
if line.startswith("#"):
continue
try:
item = ast.literal_eval(line)
if len(item) != 2:
raise ValueError("Unsupported merges format")
merges.append((to_bytes(item[0]), to_bytes(item[1])))
continue
except Exception:
pass
parts = line.split()
if len(parts) != 2:
raise ValueError("Unsupported merges format")
merges.append((to_bytes(parts[0]), to_bytes(parts[1])))
return cls(vocab, merges, special_tokens)
def _bpe_merge(self, words: bytes) -> list[bytes]:
if words in self.cache:
return self.cache[words]
wordsbytes = [bytes([x]) for x in words]
merge_priority = self.merge_priority
while len(wordsbytes) > 1:
good_pairs = set(
(l, r) for l, r in pairwise(wordsbytes)
if (l, r) in merge_priority
)
if not good_pairs:
break
best_pair = min(good_pairs, key=lambda x: merge_priority[x])
# O(1) space implementation
i = 0
for x in wordsbytes:
wordsbytes[i] = x
i += 1
if i > 1 \
and wordsbytes[i - 2] == best_pair[0] \
and wordsbytes[i - 1] == best_pair[1]:
wordsbytes[i - 2] += wordsbytes[i - 1]
i -= 1
del wordsbytes[i:]
self.cache[words] = wordsbytes
return wordsbytes
def encode(self, text: str) -> list[int]:
if not text:
return []
special_tokens = self.special_tokens
bytes2id = self.bytes2id
if special_tokens:
special_tokens_sorted = sorted(special_tokens, key=len, reverse=True)
special_pattern = "|".join(map(regex.escape, special_tokens_sorted))
chunks = regex.split(f"({special_pattern})", text)
else:
chunks = [text]
ids = []
for chunk in chunks:
if not chunk:
continue
if chunk in special_tokens:
ids.append(bytes2id[chunk.encode("utf-8")])
continue
for word in regex.findall(PAT, chunk):
if not word:
continue
merged_word = self._bpe_merge(word.encode("utf-8"))
for s in merged_word:
ids.append(bytes2id[s])
return ids
def encode_iterable(self, iterable: Iterable[str]) -> Iterator[int]:
for text in iterable:
yield from self.encode(text)
def decode(self, ids: list[int]) -> str:
all2bytes = b"".join(self.vocab[id] for id in ids)
return all2bytes.decode("utf-8", errors="replace")
- 初始化函数就是存一下 bytes2id 以及 id2bytes的映射,merges
- encode 就是分词,然后做合并,合并那里可以O(1)空间实现,也算是算法题基本功了
- 合并那里我开了个cache做优化,实测不加也能过
- decode 直接映射就行
测试结果
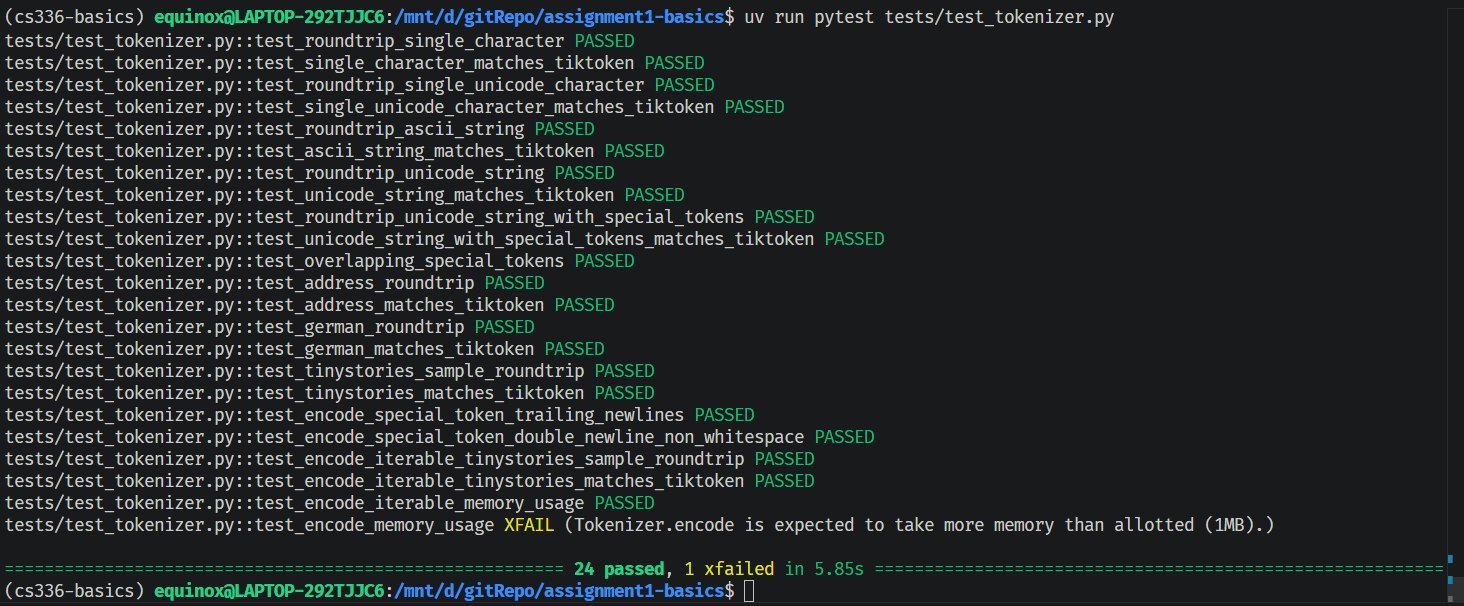
XFAIL 是作者预期不通过,正常。
二、Transformer Language Model Architecture
一些前置知识:
这一部分的总体目标是从零实现一个 decoder-only Transformer 语言模型,也就是类似 GPT/LLaMA 这类自回归语言模型的核心架构。从高层结构到每个基础模块,最后把它们组装成完整的 Transformer LM。
讲义先定义了语言模型的输入输出:
- 输入:一批 token ID,形状为
- 输出:每个位置对下一个 token 的预测 logits / 概率分布,形状为
模型的大致流程是:
- Token Embedding:把离散 token ID 映射成连续向量;
- 多个 Transformer Block:进行上下文建模;
- Final RMSNorm:最后归一化;
- LM Head / Output Projection:映射到词表大小,得到 next-token logits;
- 训练时用这些 logits 计算交叉熵,推理时用最后一个位置的分布生成下一个 token。
2.1 Basic Building Blocks: Linear and Embedding Modules
因为这个课nn.Linear 和 nn.Embedding这些东西ban了,所以要我们自己手搓,好在nn.Module、ModuleList这些东西还能用。
2.1.1 Implementing the linear module (1 points)
手写一个Linear Module,值得注意的是:
- 权重初始化要用讲义指定的方式
- 然后讲义还特别强调了下:•construct and store your parameter as$ W$ (not $W^T$),也就是说我们前向传播应该写成 x @ W
实现:
Linear.py
import torch
from torch import nn
class Linear(nn.Module):
def __init__(self, in_features: int, out_features: int, device: torch.device=None, dtype: torch.dtype=None):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.device = device
self.dtype = dtype
self.W = nn.Parameter(torch.rand(out_features, in_features, device=device, dtype=dtype))
# no bias
# approximate initializations given in handout
std = (2 / (in_features + out_features)) ** 0.5
nn.init.trunc_normal_(self.W, std=std, a=-3*std, b=3*std)
def forward(self, x: torch.tensor) -> torch.tensor:
return x @ self.W.T
adapters.py
def run_linear(
d_in: int,
d_out: int,
weights: Float[Tensor, " d_out d_in"],
in_features: Float[Tensor, " ... d_in"],
) -> Float[Tensor, " ... d_out"]:
"""
Given the weights of a Linear layer, compute the transformation of a batched input.
Args:
in_dim (int): The size of the input dimension
out_dim (int): The size of the output dimension
weights (Float[Tensor, "d_out d_in"]): The linear weights to use
in_features (Float[Tensor, "... d_in"]): The output tensor to apply the function to
Returns:
Float[Tensor, "... d_out"]: The transformed output of your linear module.
"""
device = 'cuda' if torch.cuda.is_available() else 'cpu'
mlp = Linear(in_features=d_in, out_features=d_out, device=device, dtype=torch.float32)
mlp.W = nn.Parameter(weights)
return mlp(in_features)
测试结果:
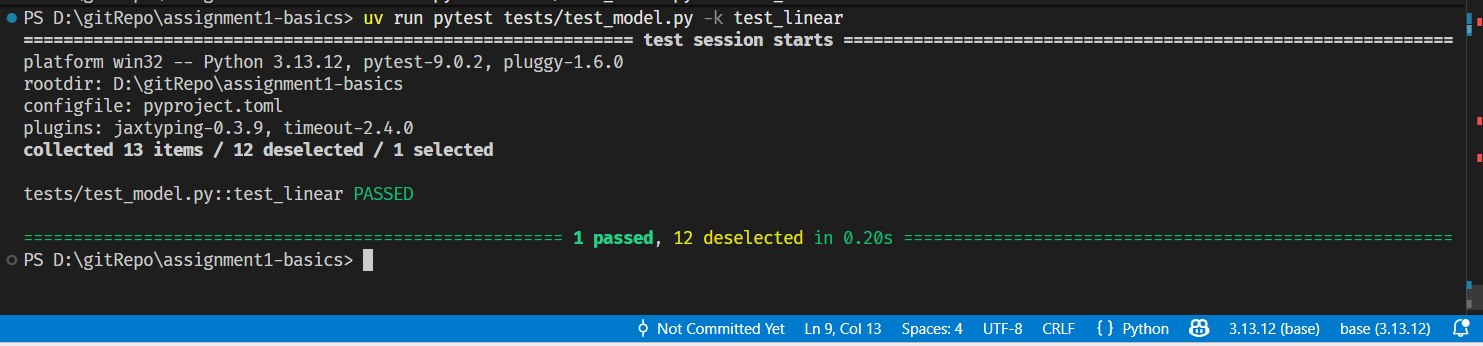
2.1.2 Implement the embedding module (1 points)
embedding就是查表,然后初始化方式按讲义指定的来就好。
Embedding.py
import torch
from torch import nn
class Embedding(nn.Module):
def __init__(self, num_embeddings: int, embedding_dim: int, device: torch.device=None, dtype: torch.dtype=None):
super().__init__()
self.num_embeddings = num_embeddings
self.embedding_dim = embedding_dim
self.device = device
self.dtype = dtype
# also row main vector
self.embeddings = nn.Parameter(torch.rand(num_embeddings, embedding_dim, device=device, dtype=dtype))
std = 1
nn.init.trunc_normal_(self.embeddings, std=std, a=-3*std, b=3*std)
def forward(self, token_ids: torch.Tensor) -> torch.Tensor:
return self.embeddings[token_ids]
adapters.py
def run_embedding(
vocab_size: int,
d_model: int,
weights: Float[Tensor, " vocab_size d_model"],
token_ids: Int[Tensor, " ..."],
) -> Float[Tensor, " ... d_model"]:
"""
Given the weights of an Embedding layer, get the embeddings for a batch of token ids.
Args:
vocab_size (int): The number of embeddings in the vocabulary
d_model (int): The size of the embedding dimension
weights (Float[Tensor, "vocab_size d_model"]): The embedding vectors to fetch from
token_ids (Int[Tensor, "..."]): The set of token ids to fetch from the Embedding layer
Returns:
Float[Tensor, "... d_model"]: Batch of embeddings returned by your Embedding layer.
"""
device = 'cuda' if torch.cuda.is_available() else 'cpu'
emb = Embedding(vocab_size, d_model, device=device, dtype=torch.float32)
emb.embeddings = nn.Parameter(weights)
return emb(token_ids)
测试结果:
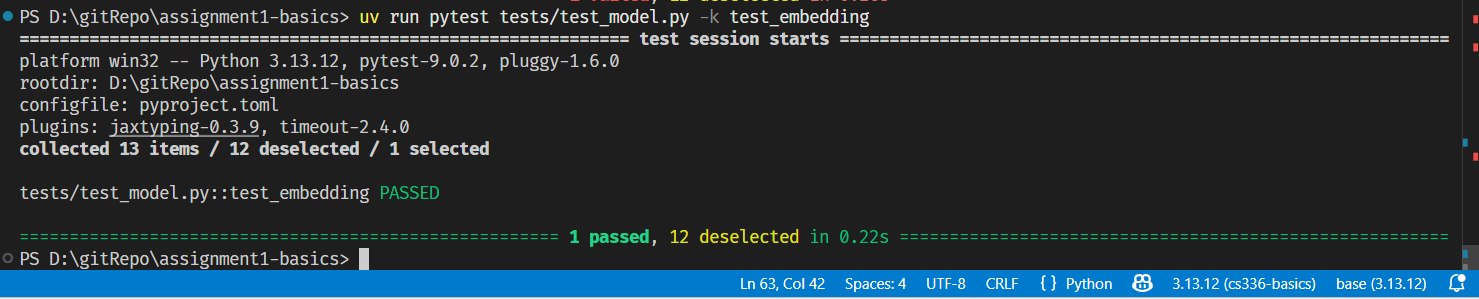
2.2 Pre-Norm Transformer Block
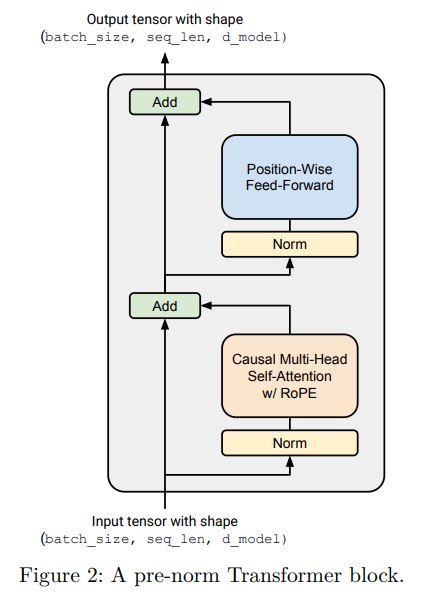
最经典的Transformer结构是在子模块后面做norm,但有很多工作发现,我们在子模块之前就做norm,有利于提升Transformer 的训练稳定性。
一个直觉上的解释就是在子模块之前做norm,那么残差连接的数据流可以包含一些不经过任何norm的信息流,比较干净。
pre-norm Transformer是现在很多语言模型的标准,如 GPT-3、LLaMA、PaLM等。
2.2.1 Root Mean Square Layer Normalization
$$ RMSNorm(a_i) = \frac{a_i}{RMS(a)}g_i $$标准的layernorm是经典的 减去均值,然后除以标准差。
讲义让我们实现另一种norm的方式 RMSnorm,见上式。
其中,
$$ \text{RMS}(a) = \sqrt{\frac{1}{d_{model}} \sum_{i=1}^{d_{model}} a_i^2 + \epsilon} $$即,不减均值, 然后仅根据均方根来缩放。好处是计算更简单,现代LLM如 LLaMA 使用RMSNorm。
下面就要手搓这个模块了,讲义特地提醒,为了避免数值溢出,计算前要把输入转成 float32,然后再转回原 dtype。
RMSnorm.py
import torch
from torch import nn
class RMSNorm(nn.Module):
def __init__(self, d_model: int, eps: float = 1E-5, device: torch.device = None, dtype: torch.dtype = None):
super().__init__()
self.d_model = d_model
self.eps = eps
self.device = device
self.dtype = dtype
self.g = nn.Parameter(torch.ones(d_model, device=device, dtype=dtype))
def forward(self, x: torch.Tensor) -> torch.Tensor:
x_type = x.dtype
x = x.to(torch.float32)
den = (x**2).mean(dim=-1, keepdim=True)
x = x / torch.sqrt(den + self.eps)
# 注意是hadamard乘积
return (self.g * x).to(x_type)
adapters.py
def run_rmsnorm(
d_model: int,
eps: float,
weights: Float[Tensor, " d_model"],
in_features: Float[Tensor, " ... d_model"],
) -> Float[Tensor, " ... d_model"]:
"""Given the weights of a RMSNorm affine transform,
return the output of running RMSNorm on the input features.
Args:
d_model (int): The dimensionality of the RMSNorm input.
eps: (float): A value added to the denominator for numerical stability.
weights (Float[Tensor, "d_model"]): RMSNorm weights.
in_features (Float[Tensor, "... d_model"]): Input features to run RMSNorm on. Can have arbitrary leading
dimensions.
Returns:
Float[Tensor,"... d_model"]: Tensor of with the same shape as `in_features` with the output of running
RMSNorm of the `in_features`.
"""
device = 'cuda' if torch.cuda.is_available() else 'cpu'
norm = RMSNorm(d_model=d_model, eps=eps, device=device, dtype=torch.float32)
norm.g = nn.Parameter(weights)
return norm(in_features)
测试结果:
2.2.2 Position-Wise Feed-Forward Network
Attention is All you Need 那篇论文的 Feed Forward network 是两个线性层中间夹了一个ReLU,原始架构中,内层的feed forward层的维度一般是输入 * 4。
然后现代的LLM对原架构做了两个改变:
-
用SwiGLU代替 ReLU
-
e.g. Llama 3 [A. Grattafiori et al., 2024] and Qwen 2.5 [A. Yang et al., 2024
-
SwiGLU 就是将SiLU 结合 GLU(Gated Linear Unit)
-
e.g. PaLM [A. Chowdhery et al., 2022] and LLaMA [H. Touvron et al., 2023].
-
-
省略有时会在线性层中用到的bias
- PaLM [A. Chowdhery et al., 2022] and LLaMA [H. Touvron et al., 2023].
SiLU的定义:
$$ SiLU(x) = x \cdot \sigma(x) = \frac{x}{1 + e^{-x}} $$GLU 是一种门控机制;定义为:一个经过 sigmoid 函数的线性变换,与另一个线性变换之间的逐元素乘积:
$$ GLU(x, W_1, W_2) = \sigma(W_1x) \odot W_2x $$- $\odot$ 是逐元素相乘
- 门控线性单元被认为可以:通过为梯度提供一条线性路径,同时保留非线性能力,从而减少深层架构中的梯度消失问题。
总之,原始 FFN 通常是:
$$ \text{FFN}(x) = W_2 \text{ReLU}(W_1x) $$本章使用:
$$ \text{FFN}(x) = SwiGLU(x, W_1, W_2, W_3) = W_2(\text{SiLU}(W_1x) \odot W_3x) $$其中:
$$ x\in \mathbb{R}^{d_{\text{model}}} $$$$ W_1,W_3\in \mathbb{R}^{d_{\text{ff}}\times d_{\text{model}}} $$$$ W_2\in \mathbb{R}^{d_{\text{model}}\times d_{\text{ff}}} $$通常情况下:
$$ d_{\text{ff}}=\frac{8}{3}d_{\text{model}} $$在具体实现中,为了提高硬件效率,可以将这个维度四舍五入到接近的 64 的倍数。
Shazeer 首先提出将 SiLU / Swish 激活函数与 GLU 结合起来,并通过实验表明,在语言建模任务上,SwiGLU 的表现优于 ReLU 和没有门控机制的 SiLU 等基线方法。
讲义里面提到了一些关于这些组件的启发式解释,并且相关论文也提供了更多支持性证据,但最好还是保持一种经验主义视角:Shazeer 论文中有一句现在很有名的话:
“我们并没有解释为什么这些架构看起来有效;我们把它们的成功归因于……”
2.2.3 Implement the position-wise feed-forward network (2 points)
实现方面,就是把公式封装成module,然后讲义说了可以用torch.sigmoid
SwiGLUFFN.py
import torch
from torch import nn
from Linear import Linear
# 注意运算都是 Hadamard 乘积
class SwiGLUFFN(nn.Module):
def __init__(self, d_model: int, d_ff: int):
super().__init__()
self.d_model = d_model
self.d_ff = d_ff
self.W1 = Linear(d_model, d_ff)
self.W2 = Linear(d_ff, d_model)
self.W3 = Linear(d_model, d_ff)
def forward(self, x: torch.Tensor):
w1x = self.W1(x)
w3x = self.W3(x)
return self.W2(self._SiLU(w1x) * w3x)
def _SiLU(self, x: torch.Tensor):
return x * torch.sigmoid(x)
adapters.py
def run_swiglu(
d_model: int,
d_ff: int,
w1_weight: Float[Tensor, " d_ff d_model"],
w2_weight: Float[Tensor, " d_model d_ff"],
w3_weight: Float[Tensor, " d_ff d_model"],
in_features: Float[Tensor, " ... d_model"],
) -> Float[Tensor, " ... d_model"]:
"""Given the weights of a SwiGLU network, return
the output of your implementation with these weights.
Args:
d_model (int): Dimensionality of the feedforward input and output.
d_ff (int): Dimensionality of the up-project happening internally to your swiglu.
w1_weight (Float[Tensor, "d_ff d_model"]): Stored weights for W1
w2_weight (Float[Tensor, "d_model d_ff"]): Stored weights for W2
w3_weight (Float[Tensor, "d_ff d_model"]): Stored weights for W3
in_features (Float[Tensor, "... d_model"]): Input embeddings to the feed-forward layer.
Returns:
Float[Tensor, "... d_model"]: Output embeddings of the same shape as the input embeddings.
"""
# Example:
# If your state dict keys match, you can use `load_state_dict()`
# swiglu.load_state_dict(weights)
# You can also manually assign the weights
# swiglu.w1.weight.data = w1_weight
# swiglu.w2.weight.data = w2_weight
# swiglu.w3.weight.data = w3_weight
ffn = SwiGLUFFN(d_model=d_model, d_ff=d_ff)
ffn.W1.W = nn.Parameter(w1_weight)
ffn.W2.W = nn.Parameter(w2_weight)
ffn.W3.W = nn.Parameter(w3_weight)
return ffn(in_features)
测试结果:
2.3 Relative Positional Embeddings
2.3.1 RoPE
讲义介绍了一种位置编码的实现方法:旋转位置嵌入(Rotary Position Embeddings),通常称为 RoPE。
对于位于 token 位置 $i$ 的某个 query token:
$$ q^{(i)} = W_q x^{(i)} \in \mathbb{R}^d $$我们会对它应用一个成对旋转矩阵 $R_i$,得到:
$$ q'^{(i)} = R_i q^{(i)} = R_i W_q x^{(i)} $$这里,$R_i$ 会把 embedding 元素中的成对分量:
$$ q^{(i)}_{2k-1:2k} $$看作二维向量,并将其旋转一个角度:
$$ \theta_{i,k} = \frac{i}{\Theta^{(2k-2)/d}} $$其中:
$$ k \in \{1,\dots,d/2\} $$$\Theta$ 是某个常数。
因此,我们可以把 $R_i$ 看成一个大小为 $d\times d$ 的块对角矩阵。这个矩阵由若干个小块组成,每个小块对应一个 $R_{i,k}$,其中:
$$ k \in \{1,\dots,d/2\} $$并且:
$$ R_i^k = \begin{pmatrix} \cos(\theta_{i,k}) & \sin(\theta_{i,k}) \\ -\sin(\theta_{i,k}) & \cos(\theta_{i,k}) \end{pmatrix} $$于是,我们得到完整的旋转矩阵:
$$ R_i = \begin{pmatrix} R_i^1 & 0 & 0 & \cdots & 0 \\ 0 & R_i^2 & 0 & \cdots & 0 \\ 0 & 0 & R_i^3 & \cdots & 0 \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \cdots & R_i^{d/2} \end{pmatrix} $$其中,$0$ 表示 $2\times2$ 的零矩阵。
虽然可以显式构造完整的 $d\times d$ 矩阵,但一个好的实现应该利用这个矩阵的结构性质,更高效地完成变换。
由于我们只关心给定序列中 token 之间的相对旋转关系,所以对于:
$$ \cos(\theta_{i,k}) $$和
$$ \sin(\theta_{i,k}) $$这些已经计算好的值,可以在不同层、不同 batch 之间重复使用。
讲义给了一个优化实现,可以使用一个被所有层共享引用的 RoPE 模块。这个模块可以在初始化时创建一个二维的、预先计算好的 sin 和 cos buffer,并使用:
self.register_buffer(persistent=False)
来注册它们,而不是使用:
nn.Parameter
因为这些固定的常数没有必要通过梯度下降来学习。
2.3.2 Implement RoPE (2 points)
- 实现思路主要就是,提前生成 [max_seq_len, d_k / 2] 的cos 和 sin,存起来
- 然后对于输入x,两两行向量去做对应的旋转变换
实现过程中的维度变换还是值得深究的。
RoPE.py
import torch
from torch import nn
class RoPE(nn.Module):
def __init__(self, theta: float, d_k: int, max_seq_len: int, device: torch.device = None):
super().__init__()
self.theta = theta
if d_k % 2 > 0:
raise ValueError("d_k must be an even positive integer")
self.theta = theta
self.d_k = d_k # dimension of query and key
self.max_seq_len = max_seq_len
self.device = device
exps = 1 / (theta ** (torch.arange(0, d_k, 2, dtype=torch.float32, device=device) / d_k))
positions = torch.arange(max_seq_len, device=device)
# outer(a[0..n), b[0..n)) =>c_ij = ai * bj
vals = torch.outer(positions, exps)
self.register_buffer("cos_memo", vals.cos(), persistent=False)
self.register_buffer("sin_memo", vals.sin(), persistent=False)
def forward(self, x: torch.Tensor, token_positions: torch.Tensor) -> torch.Tensor:
x = x.to(self.device)
x_e = x[..., 0::2]
x_o = x[..., 1::2]
cos = self.cos_memo[token_positions]
sin = self.sin_memo[token_positions]
# [1, max_seq_len, d_k//2] => [max_seq_len, d_k//2]
# to make use of broadcast
cos = cos.unsqueeze(0)
sin = sin.unsqueeze(0)
# [batch, max_seq_len, d_k//2]
new_x_e = x_e * cos - x_o * sin
new_x_o = x_o * cos + x_e * sin
# [batch, max_seq_len, d_k//2,2]
res = torch.stack([new_x_e, new_x_o], dim=-1)
# [batch, max_seq_len, d_k], 然后flatten恰好会把奇偶交错排列
return res.flatten(-2)
adapters.py
def run_rope(
d_k: int,
theta: float,
max_seq_len: int,
in_query_or_key: Float[Tensor, " ... sequence_length d_k"],
token_positions: Int[Tensor, " ... sequence_length"],
) -> Float[Tensor, " ... sequence_length d_k"]:
"""
Run RoPE for a given input tensor.
Args:
d_k (int): Embedding dimension size for the query or key tensor.
theta (float): RoPE parameter.
max_seq_len (int): Maximum sequence length to pre-cache if your implementation does that.
in_query_or_key (Float[Tensor, "... sequence_length d_k"]): Input tensor to run RoPE on.
token_positions (Int[Tensor, "... sequence_length"]): Tensor of shape (batch_size, sequence_length) with the token positions
Returns:
Float[Tensor, " ... sequence_length d_k"]: Tensor with RoPEd input.
"""
device = 'cuda' if torch.cuda.is_available() else 'cpu'
rope = RoPE(theta=theta, d_k=d_k, max_seq_len=max_seq_len, device=device)
return rope(in_query_or_key, token_positions)
测试结果:
2.4 Scaled Dot-Product Attention
然后就是搓一下经典的缩放点积注意力。
2.4.1 Implement softmax (1 point)
- softmax 的参数会指定在哪个维度上面做softmax
- 其次,因为指数爆炸很容易发生,所以我们要对输入进行norm,具体来说就是减去dim这一维度的最大值,这下指数就非正,也就不会发生指数爆炸,数值上溢了
softmax.py
import torch
from torch import nn
def softmax(x: torch.Tensor, dim: int) -> torch.Tensor:
'''
x: [batch_size, seq_len, d_model]
x.max is a tuple: (values, indices)
so x.max()[0] is a scalar, or 1x1 tensor
'''
ma = x.max(dim=dim, keepdim=True)[0]
x_exp = torch.exp(x - ma)
Z_theta = x_exp.sum(dim=dim, keepdim=True)
return x_exp / Z_theta
adapters.py
def run_softmax(in_features: Float[Tensor, " ..."], dim: int) -> Float[Tensor, " ..."]:
"""
Given a tensor of inputs, return the output of softmaxing the given `dim`
of the input.
Args:
in_features (Float[Tensor, "..."]): Input features to softmax. Shape is arbitrary.
dim (int): Dimension of the `in_features` to apply softmax to.
Returns:
Float[Tensor, "..."]: Tensor of with the same shape as `in_features` with the output of
softmax normalizing the specified `dim`.
"""
return softmax(in_features, dim)
测试结果:
2.4.2 Implement scaled dot-product attention (5 points)
经典的 缩放点积注意力 公式:
$$ \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$其中:
$$ Q \in \mathbb{R}^{n \times d_k} $$$$ K \in \mathbb{R}^{m \times d_k} $$$$ V \in \mathbb{R}^{m \times d_v} $$这里,$Q$、$K$ 和 $V$ 都是该操作的输入。注意,它们不是可学习参数。$W_q, W_k, W_v $才是
Masking:掩码
有时候,对 attention 操作的输出进行 mask 是很方便的。
一个 mask 的形状应为:
$$ M \in \{\text{True}, \text{False}\}^{n \times m} $$这个布尔矩阵的每一行 $i$ 表示:query $i$ 应该关注哪些 key。
按照惯例,虽然这有点容易让人困惑:
位置 (i,j) 上的值为 True,表示 query i 会关注 key j;
位置 (i,j) 上的值为 False,表示 query i 不会关注 key j。
换句话说,在值为 True 的 $(i,j)$ 对上,“信息可以流动”。
例如,考虑一个 $1\times3$ 的 mask 矩阵:
[[True, True, False]]
这个单独的 query 向量只会关注前两个 key。
从计算角度看,使用 mask 会比在子序列上分别计算 attention 高效得多。我们可以这样实现:取 softmax 之前的值:
$$ \frac{QK^T}{\sqrt{d_k}} $$然后对 mask 矩阵中值为 False 的任意位置加上:
$$-\infty$$。这样这些位置在经过 softmax 后,其注意力概率就会变成 0。
然后就是实现部分:
有一个坑就是 torch.sqrt 的参数类型得是 nn.Tensor,但是 nn.Tensor(d_k) 返回的是长度为d_k的Tensor,用 nn.tensor(d_k)才使用d_k 的值来创建一个对应的Tensor
scaled_dot_product_attention.py
import torch
from torch import nn
from softmax import softmax
def scaled_dot_product_attention(Q: torch.Tensor, K: torch.Tensor, V: torch.Tensor, mask: torch.Tensor | None = None):
d_k = Q.shape[-1]
# batch mat mul and batch mat transpose
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1E9)
attn_weights = softmax(scores, dim=-1)
return torch.matmul(attn_weights, V)
adapters.py
def run_scaled_dot_product_attention(
Q: Float[Tensor, " ... queries d_k"],
K: Float[Tensor, " ... keys d_k"],
V: Float[Tensor, " ... keys d_v"],
mask: Bool[Tensor, " ... queries keys"] | None = None,
) -> Float[Tensor, " ... queries d_v"]:
"""
Given key (K), query (Q), and value (V) tensors, return
the output of your scaled dot product attention implementation.
Args:
Q (Float[Tensor, " ... queries d_k"]): Query tensor
K (Float[Tensor, " ... keys d_k"]): Key tensor
V (Float[Tensor, " ... keys d_v"]): Values tensor
mask (Bool[Tensor, " ... queries keys"] | None): Mask tensor
Returns:
Float[Tensor, " ... queries d_v"]: Output of SDPA
"""
return scaled_dot_product_attention(Q, K, V, mask)
测试结果:

2.5 Causal Multi-Head Self-Attention
原来的自注意力机制是直接一次得到所有的 q,k,v,然后在高维做注意力计算。
多头自注意力机制就是说,开多个头,每个头将输入数据变换到低维空间,然后做注意力计算,每个头的结果拼接起来,就是和原来维度一样的注意力。
这样做,相当于在不同的特征空间去寻找关系,让模型能够同时捕捉局部依赖、全局依赖、长距离依赖、句法/语义等不同层级的信息。
然后就是实现:
有一些细节:
- 因为多头注意力要对权重矩阵做一些维度变换,pytorch中,做维度变换后其实就不连续了(视图变了,和底层存储不一致),加减乘除操作不要求张量内存存储连续,但是view 要求连续,所以如果做view的时候,张量不连续,需要先 contiguous
- 多头注意力做缩放的时候,分母应该是每个头的维度,即 d_model / num_heads
multihead_self_attention.py
import torch
from torch import nn
from softmax import softmax
class multihead_self_attention(nn.Module):
def __init__(self, d_model: int, num_heads: int):
super().__init__()
self.d_model = d_model # input dim
self.num_heads = num_heads # num of head
self.head_dim = d_model // num_heads # dim of each head
def _attention(self, Q: torch.Tensor, K: torch.Tensor, V: torch.Tensor, mask: torch.Tensor | None = None):
d_k = self.head_dim # 注意,每个头的维度是 head_dim
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k))
if mask is not None:
scores = scores.masked_fill(mask == 1, -1E9)
attn_weights = softmax(scores, dim=-1)
return torch.matmul(attn_weights, V)
def forward(self, x: torch.Tensor, Wq: torch.Tensor, Wk: torch.Tensor, Wv: torch.Tensor, Wo: torch.Tensor) -> torch.Tensor:
batch_size, seq_len, self.d_model = x.shape
q = x @ Wq.T # (batch_size, seq_len, d_model) @ (d_model, d_k) -> (batch_size, seq_len, d_k)
k = x @ Wk.T # (batch_size, seq_len, d_model) @ (d_model, d_k) -> (batch_size, seq_len, d_k)
v = x @ Wv.T # (batch_size, seq_len, d_model) @ (d_model, d_k) -> (batch_size, seq_len, d_k)
q = q.view(batch_size, seq_len, self.num_heads, self.head_dim)
k = k.view(batch_size, seq_len, self.num_heads, self.head_dim)
v = v.view(batch_size, seq_len, self.num_heads, self.head_dim)
q = q.transpose(1, 2)
k = k.transpose(1, 2)
v = v.transpose(1, 2)
# 对角线上方第一条对角往上都是1
mask = torch.triu(torch.ones(seq_len, seq_len, dtype=torch.bool, device=x.device), diagonal=1)
mask = mask.unsqueeze(0).unsqueeze(0) # [1, 1, seq_len, seq_len]
attn = self._attention(q, k, v, mask) # [batch_size, num_heads, seq_len, self.head_dim]
attn = attn.transpose(1, 2) # # [batch_size, seq_len, num_heads, self.head_dim]
attn = attn.contiguous().view(batch_size, seq_len, self.d_model)
return attn @ Wo.T
adapters.py
def run_multihead_self_attention(
d_model: int,
num_heads: int,
q_proj_weight: Float[Tensor, " d_model d_model"],
k_proj_weight: Float[Tensor, " d_model d_model"],
v_proj_weight: Float[Tensor, " d_model d_model"],
o_proj_weight: Float[Tensor, " d_model d_model"],
in_features: Float[Tensor, " ... sequence_length d_model"],
) -> Float[Tensor, " ... sequence_length d_model"]:
"""
Given the key, query, and value projection weights of a naive unbatched
implementation of multi-head attention, return the output of an optimized batched
implementation. This implementation should handle the key, query, and value projections
for all heads in a single matrix multiply.
This function should not use RoPE.
See section 3.2.2 of Vaswani et al., 2017.
Args:
d_model (int): Dimensionality of the feedforward input and output.
num_heads (int): Number of heads to use in multi-headed attention.
max_seq_len (int): Maximum sequence length to pre-cache if your implementation does that.
q_proj_weight (Float[Tensor, "d_model d_model"]): Weights for the Q projection
k_proj_weight (Float[Tensor, "d_model d_model"]): Weights for the K projection
v_proj_weight (Float[Tensor, "d_model d_model"]): Weights for the V projection
o_proj_weight (Float[Tensor, "d_model d_model"]): Weights for the output projection
in_features (Float[Tensor, "... sequence_length d_model"]): Tensor to run your implementation on.
Returns:
Float[Tensor, " ... sequence_length d_model"]: Tensor with the output of running your optimized, batched multi-headed attention
implementation with the given QKV projection weights and input features.
"""
model = multihead_self_attention(d_model, num_heads)
return model(in_features, q_proj_weight, k_proj_weight, v_proj_weight, o_proj_weight)
测试结果:
然后是加上位置编码版本的实现,讲义里面要求只对 q 和 k 做位置编码。
multihead_self_attention_rope.py
import torch
from torch import nn
from softmax import softmax
from RoPE import RoPE
class multihead_self_attention_rope(nn.Module):
def __init__(self, d_model: int, num_heads: int, max_seq_len: int, theta: float, device: torch.device | None = None):
super().__init__()
self.d_model = d_model # input dim
self.num_heads = num_heads # num of head
self.head_dim = d_model // num_heads # dim of each head
self.rope = RoPE(theta, self.head_dim, max_seq_len, device)
def _attention(self, Q: torch.Tensor, K: torch.Tensor, V: torch.Tensor, mask: torch.Tensor | None = None):
d_k = self.head_dim # 注意,每个头的维度是 head_dim
scores = torch.matmul(Q, K.transpose(-2, -1)) / (d_k ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 1, -1E9)
attn_weights = softmax(scores, dim=-1)
return torch.matmul(attn_weights, V)
def forward(self, x: torch.Tensor, Wq: torch.Tensor, Wk: torch.Tensor, Wv: torch.Tensor, Wo: torch.Tensor, token_positions: torch.Tensor) -> torch.Tensor:
batch_size, seq_len, self.d_model = x.shape
q = x @ Wq.T # (batch_size, seq_len, d_model) @ (d_model, d_k) -> (batch_size, seq_len, d_k)
k = x @ Wk.T # (batch_size, seq_len, d_model) @ (d_model, d_k) -> (batch_size, seq_len, d_k)
v = x @ Wv.T # (batch_size, seq_len, d_model) @ (d_model, d_k) -> (batch_size, seq_len, d_k)
q = q.view(batch_size, seq_len, self.num_heads, self.head_dim)
k = k.view(batch_size, seq_len, self.num_heads, self.head_dim)
v = v.view(batch_size, seq_len, self.num_heads, self.head_dim)
q = q.transpose(1, 2)
k = k.transpose(1, 2)
v = v.transpose(1, 2)
q = self.rope(q, token_positions)
k = self.rope(k, token_positions)
# 对角线上方第一条对角往上都是1
mask = torch.triu(torch.ones(seq_len, seq_len, dtype=torch.bool, device=x.device), diagonal=1)
mask = mask.unsqueeze(0).unsqueeze(0) # [1, 1, seq_len, seq_len]
attn = self._attention(q, k, v, mask) # [batch_size, num_heads, seq_len, self.head_dim]
attn = attn.transpose(1, 2) # # [batch_size, seq_len, num_heads, self.head_dim]
attn = attn.contiguous().view(batch_size, seq_len, self.d_model)
return attn @ Wo.T
adapters.py
def run_rope(
d_k: int,
theta: float,
max_seq_len: int,
in_query_or_key: Float[Tensor, " ... sequence_length d_k"],
token_positions: Int[Tensor, " ... sequence_length"],
) -> Float[Tensor, " ... sequence_length d_k"]:
"""
Run RoPE for a given input tensor.
Args:
d_k (int): Embedding dimension size for the query or key tensor.
theta (float): RoPE parameter.
max_seq_len (int): Maximum sequence length to pre-cache if your implementation does that.
in_query_or_key (Float[Tensor, "... sequence_length d_k"]): Input tensor to run RoPE on.
token_positions (Int[Tensor, "... sequence_length"]): Tensor of shape (batch_size, sequence_length) with the token positions
Returns:
Float[Tensor, " ... sequence_length d_k"]: Tensor with RoPEd input.
"""
device = 'cuda' if torch.cuda.is_available() else 'cpu'
rope = RoPE(theta=theta, d_k=d_k, max_seq_len=max_seq_len, device=device)
return rope(in_query_or_key, token_positions)
测试结果:
2.6 The Full Transformer LM
2.6.1 Implement the Transformer block (3 points)
根据模块图拼接即可。
不过这里刚开始测的时候一直没过,排查半天发现是 RMS那里:
x = x / torch.sqrt(den + self.eps)
我写成了:
x /= torch.sqrt(den + self.eps)
这种原地修改会导致变量直接改了,说明有的测试点的输入复用了?
实现:
transformer_block.py
import torch
from torch import nn
from SwiGLUFFN import SwiGLUFFN
from multihead_self_attention_rope import multihead_self_attention_rope
from RMSNorm import RMSNorm
class transformer_block(nn.Module):
def __init__(self, d_model: int, num_heads: int, d_ff: int, max_seq_len: int, theta: float, attn_q_proj_weight: torch.Tensor, attn_k_proj_weight: torch.Tensor, attn_v_proj_weight: torch.Tensor, attn_o_proj_weight: torch.Tensor, ln1_weight: torch.Tensor, ln2_weight: torch.Tensor, ffn_w1_weight: torch.Tensor, ffn_w2_weight: torch.Tensor, ffn_w3_weight: torch.Tensor, device=None):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_ff = d_ff
self.max_seq_len = max_seq_len
self.device = device
self.theta = theta
self.attn_q_proj_weight = attn_q_proj_weight
self.attn_k_proj_weight = attn_k_proj_weight
self.attn_v_proj_weight = attn_v_proj_weight
self.attn_o_proj_weight = attn_o_proj_weight
self.rms1 = RMSNorm(d_model, eps=1E-5, device=device)
self.rms2 = RMSNorm(d_model, eps=1E-5, device=device)
self.rms1.load_state_dict({"g": ln1_weight})
self.rms2.load_state_dict({"g": ln2_weight})
self.ffn = SwiGLUFFN(d_model, d_ff)
self.ffn.load_state_dict({"W1.W": ffn_w1_weight, "W2.W": ffn_w2_weight, "W3.W": ffn_w3_weight})
self.MHA = multihead_self_attention_rope(d_model, num_heads, max_seq_len, theta, device)
def forward(self, in_features: torch.Tensor) -> torch.Tensor:
# [batch_size, seq_len, ...]
# shape[1] = seq_len
token_positions = torch.arange(in_features.shape[-2], device=in_features.device)
x1 = self.rms1(in_features)
x1 = self.MHA(x1, self.attn_q_proj_weight, self.attn_k_proj_weight, self.attn_v_proj_weight, self.attn_o_proj_weight, token_positions)
x1 = in_features + x1
x2 = self.rms2(x1)
x2 = self.ffn(x2)
return x1 + x2
adapters.py
def run_transformer_block(
d_model: int,
num_heads: int,
d_ff: int,
max_seq_len: int,
theta: float,
weights: dict[str, Tensor],
in_features: Float[Tensor, " batch sequence_length d_model"],
) -> Float[Tensor, " batch sequence_length d_model"]:
"""
Given the weights of a pre-norm Transformer block and input features,
return the output of running the Transformer block on the input features.
This function should use RoPE.
Depending on your implementation, you may simply need to pass the relevant args
to your TransformerBlock constructor, or you may need to initialize your own RoPE
class and pass that instead.
Args:
d_model (int): The dimensionality of the Transformer block input.
num_heads (int): Number of heads to use in multi-headed attention. `d_model` must be
evenly divisible by `num_heads`.
d_ff (int): Dimensionality of the feed-forward inner layer.
max_seq_len (int): Maximum sequence length to pre-cache if your implementation does that.
theta (float): RoPE parameter.
weights (dict[str, Tensor]):
State dict of our reference implementation.
The keys of this dictionary are:
- `attn.q_proj.weight`
The query projections for all `num_heads` attention heads.
Shape is (d_model, d_model).
The rows are ordered by matrices of shape (num_heads, d_k),
so `attn.q_proj.weight == torch.cat([q_heads.0.weight, ..., q_heads.N.weight], dim=0)`.
- `attn.k_proj.weight`
The key projections for all `num_heads` attention heads.
Shape is (d_model, d_model).
The rows are ordered by matrices of shape (num_heads, d_k),
so `attn.k_proj.weight == torch.cat([k_heads.0.weight, ..., k_heads.N.weight], dim=0)`.
- `attn.v_proj.weight`
The value projections for all `num_heads` attention heads.
Shape is (d_model, d_model).
The rows are ordered by matrices of shape (num_heads, d_v),
so `attn.v_proj.weight == torch.cat([v_heads.0.weight, ..., v_heads.N.weight], dim=0)`.
- `attn.output_proj.weight`
Weight of the multi-head self-attention output projection
Shape is (d_model, d_model).
- `ln1.weight`
Weights of affine transform for the first RMSNorm
applied in the transformer block.
Shape is (d_model,).
- `ffn.w1.weight`
Weight of the first linear transformation in the FFN.
Shape is (d_ff, d_model).
- `ffn.w2.weight`
Weight of the second linear transformation in the FFN.
Shape is (d_model, d_ff).
- `ffn.w3.weight`
Weight of the third linear transformation in the FFN.
Shape is (d_ff, d_model).
- `ln2.weight`
Weights of affine transform for the second RMSNorm
applied in the transformer block.
Shape is (d_model,).
in_features (Float[Tensor, "batch sequence_length d_model"]):
Tensor to run your implementation on.
Returns:
Float[Tensor, "batch sequence_length d_model"] Tensor with the output of
running the Transformer block on the input features while using RoPE.
"""
device = 'cuda' if torch.cuda.is_available() else 'cpu'
dtype = in_features.dtype
attn_q_proj_weight = weights["attn.q_proj.weight"].to(device=device, dtype=dtype)
attn_k_proj_weight = weights["attn.k_proj.weight"].to(device=device, dtype=dtype)
attn_v_proj_weight = weights["attn.v_proj.weight"].to(device=device, dtype=dtype)
attn_o_proj_weight = weights["attn.output_proj.weight"].to(device=device, dtype=dtype)
ln1_weight = weights["ln1.weight"].to(device=device, dtype=dtype)
ln2_weight = weights["ln2.weight"].to(device=device, dtype=dtype)
ffn_w1_weight = weights["ffn.w1.weight"].to(device=device, dtype=dtype)
ffn_w2_weight = weights["ffn.w2.weight"].to(device=device, dtype=dtype)
ffn_w3_weight = weights["ffn.w3.weight"].to(device=device, dtype=dtype)
model = transformer_block(d_model, num_heads, d_ff, max_seq_len, theta, attn_q_proj_weight, attn_k_proj_weight, attn_v_proj_weight, attn_o_proj_weight, ln1_weight, ln2_weight, ffn_w1_weight, ffn_w2_weight, ffn_w3_weight, device)
return model(in_features)
测试结果:
2.6.2 Implementing the Transformer LM (3 points)
然后就是根据架构图搭一个Transformer LM了,非常简单。
transformer_lm.py
import torch
from torch import nn
from transformer_block import transformer_block
from Embedding import Embedding
from Linear import Linear
from RoPE import RoPE
from RMSNorm import RMSNorm
from SwiGLUFFN import SwiGLUFFN
from softmax import softmax
class Transformer_LM(nn.Module):
def __init__(
self,
vocab_size: int,
context_length: int,
d_model: int,
num_layers: int,
num_heads: int,
d_ff: int,
rope_theta: float,
weights: dict[str, torch.Tensor],
):
super().__init__()
self.vocab_size = vocab_size
self.context_length = context_length
self.d_model = d_model
self.num_layers = num_layers
self.num_heads = num_heads
self.d_ff = d_ff
self.rope_theta = rope_theta
self.weights = weights
def forward(self, in_indices: torch.Tensor) -> torch.Tensor:
token_embedding = Embedding(self.vocab_size, self.d_model)
token_embedding.load_state_dict({'embeddings': self.weights['token_embeddings.weight']})
x = token_embedding(in_indices)
for i in range(self.num_layers):
attn_q_proj_weight = self.weights[f"layers.{i}.attn.q_proj.weight"]
attn_k_proj_weight = self.weights[f"layers.{i}.attn.k_proj.weight"]
attn_v_proj_weight = self.weights[f"layers.{i}.attn.v_proj.weight"]
attn_o_proj_weight = self.weights[f"layers.{i}.attn.output_proj.weight"]
ln1_weight = self.weights[f"layers.{i}.ln1.weight"]
ln2_weight = self.weights[f"layers.{i}.ln2.weight"]
ffn_w1_weight = self.weights[f"layers.{i}.ffn.w1.weight"]
ffn_w2_weight = self.weights[f"layers.{i}.ffn.w2.weight"]
ffn_w3_weight = self.weights[f"layers.{i}.ffn.w3.weight"]
trans_block = transformer_block(self.d_model, self.num_heads, self.d_ff, self.context_length, self.rope_theta, attn_q_proj_weight, attn_k_proj_weight, attn_v_proj_weight, attn_o_proj_weight, ln1_weight, ln2_weight, ffn_w1_weight, ffn_w2_weight, ffn_w3_weight)
x = trans_block(x)
rms_norm = RMSNorm(self.d_model)
rms_norm.load_state_dict({'g': self.weights["ln_final.weight"]})
x = rms_norm(x)
linear_layer = Linear(self.d_model, self.vocab_size)
linear_layer.load_state_dict({'W': self.weights['lm_head.weight']})
x = linear_layer(x)
# handout说最终输出logits即可
return x
adapters.py
def run_transformer_lm(
vocab_size: int,
context_length: int,
d_model: int,
num_layers: int,
num_heads: int,
d_ff: int,
rope_theta: float,
weights: dict[str, Tensor],
in_indices: Int[Tensor, " batch_size sequence_length"],
) -> Float[Tensor, " batch_size sequence_length vocab_size"]:
"""Given the weights of a Transformer language model and input indices,
return the output of running a forward pass on the input indices.
This function should use RoPE.
Args:
vocab_size (int): The number of unique items in the output vocabulary to be predicted.
context_length (int): The maximum number of tokens to process at once.
d_model (int): The dimensionality of the model embeddings and sublayer outputs.
num_layers (int): The number of Transformer layers to use.
num_heads (int): Number of heads to use in multi-headed attention. `d_model` must be
evenly divisible by `num_heads`.
d_ff (int): Dimensionality of the feed-forward inner layer (section 3.3).
rope_theta (float): The RoPE $\\Theta$ parameter.
weights (dict[str, Tensor]):
State dict of our reference implementation. {num_layers} refers to an
integer between `0` and `num_layers - 1` (the layer index).
The keys of this dictionary are:
- `token_embeddings.weight`
Token embedding matrix. Shape is (vocab_size, d_model).
- `layers.{num_layers}.attn.q_proj.weight`
The query projections for all `num_heads` attention heads.
Shape is (num_heads * (d_model / num_heads), d_model).
The rows are ordered by matrices of shape (num_heads, d_k),
so `attn.q_proj.weight == torch.cat([q_heads.0.weight, ..., q_heads.N.weight], dim=0)`.
- `layers.{num_layers}.attn.k_proj.weight`
The key projections for all `num_heads` attention heads.
Shape is (num_heads * (d_model / num_heads), d_model).
The rows are ordered by matrices of shape (num_heads, d_k),
so `attn.k_proj.weight == torch.cat([k_heads.0.weight, ..., k_heads.N.weight], dim=0)`.
- `layers.{num_layers}.attn.v_proj.weight`
The value projections for all `num_heads` attention heads.
Shape is (num_heads * (d_model / num_heads), d_model).
The rows are ordered by matrices of shape (num_heads, d_v),
so `attn.v_proj.weight == torch.cat([v_heads.0.weight, ..., v_heads.N.weight], dim=0)`.
- `layers.{num_layers}.attn.output_proj.weight`
Weight of the multi-head self-attention output projection
Shape is ((d_model / num_heads) * num_heads, d_model).
- `layers.{num_layers}.ln1.weight`
Weights of affine transform for the first RMSNorm
applied in the transformer block.
Shape is (d_model,).
- `layers.{num_layers}.ffn.w1.weight`
Weight of the first linear transformation in the FFN.
Shape is (d_ff, d_model).
- `layers.{num_layers}.ffn.w2.weight`
Weight of the second linear transformation in the FFN.
Shape is (d_model, d_ff).
- `layers.{num_layers}.ffn.w3.weight`
Weight of the third linear transformation in the FFN.
Shape is (d_ff, d_model).
- `layers.{num_layers}.ln2.weight`
Weights of affine transform for the second RMSNorm
applied in the transformer block.
Shape is (d_model,).
- `ln_final.weight`
Weights of affine transform for RMSNorm applied to the output of the final transformer block.
Shape is (d_model, ).
- `lm_head.weight`
Weights of the language model output embedding.
Shape is (vocab_size, d_model).
in_indices (Int[Tensor, "batch_size sequence_length"]) Tensor with input indices to run the language model on. Shape is (batch_size, sequence_length), where
`sequence_length` is at most `context_length`.
Returns:
Float[Tensor, "batch_size sequence_length vocab_size"]: Tensor with the predicted unnormalized
next-word distribution for each token.
"""
model = Transformer_LM(vocab_size, context_length, d_model, num_layers, num_heads, d_ff, rope_theta, weights)
return model(in_indices)
测试结果:
三、Training a Transformer LM
现在可以有了处理文本的tokenizer,以及 Transformer,接下来要做的就是写一些用于训练的代码。
- Loss:实现cross-entropy
- Optimizer:用于最小化loss的AdamW
- Training loop:加载数据,保存checkpoint,训练
3.1 Implement cross-entropy (1 point)
讲义说了尽可能避免使用log和exp,以保证数值稳定。
事实上,虽然之前实现的softmax已经减去了最大值,但是softmax出的概率再去取log还是可能导致数值溢出,所以一个合理的做法是对式子进行变形:
$$ \begin{align} -\log \frac{e^{x_y}}{\sum_j e^{x_j}} &= -x_y + \log \sum_j e^{x_j}\\ &= - (x_y - m) + \log \sum_j e^{x_j - m} \end{align} $$其中:
$$ m = \max_j x_j $$然后就是无情的实现了:
cross_entropy.py
import torch
'''
-log {e^xi / sum e^xj}
= -xi - log {sum e^xj}
= -(xi - m) + log{sum e^{xj-m}}
'''
def CrossEntropyLoss(inputs: torch.Tensor, targets: torch.Tensor) -> torch.Tensor:
max_logits = inputs.max(dim=-1, keepdim=True)[0]
inputs = inputs - max_logits
log_sum = torch.log(torch.exp(inputs).sum(dim=-1))
target_sum = inputs.gather(dim=-1, index=targets.unsqueeze(-1))
loss = log_sum - target_sum
return loss.mean()
adapters.py
def run_cross_entropy(
inputs: Float[Tensor, " batch_size vocab_size"], targets: Int[Tensor, " batch_size"]
) -> Float[Tensor, ""]:
"""Given a tensor of inputs and targets, compute the average cross-entropy
loss across examples.
Args:
inputs (Float[Tensor, "batch_size vocab_size"]): inputs[i][j] is the
unnormalized logit of jth class for the ith example.
targets (Int[Tensor, "batch_size"]): Tensor of shape (batch_size,) with the index of the correct class.
Each value must be between 0 and `num_classes - 1`.
Returns:
Float[Tensor, ""]: The average cross-entropy loss across examples.
"""
return CrossEntropyLoss(inputs, targets)
测试结果:
3.2 The SGD Optimizer
**随机梯度下降,Stochastic Gradient Descent (SGD)**是最简单的优化器。
从随机初始化的参数$\theta_0$开始,然后对于每一步:$t = 0,\dots,T-1$
执行如下更新:
$$ \theta_{t+1} \leftarrow \theta_t - \alpha_t \nabla L( \theta_t; B_t) $$其中:
- $B_t$是从数据集 $D$ 中随机采样得到的一个batch;
- 学习率 $\alpha_t$ 和 batch 大小 $|B_t|$ 是超参数。
为了实现优化器,需要继承 PyTorch 的:torch.optim.Optimizer类。
一个 Optimizer 子类必须实现两个方法:
- __init__(self, params, …)
这个方法用于初始化优化器。
其中,params 是需要被优化的参数集合;也可以是参数组。如果用户希望模型的不同部分使用不同的超参数,例如不同学习率,就可以使用参数组。
你需要确保将 params 传给基类的 _init_ 方法。基类会保存这些参数,以便在 step 中使用。
你也可以根据优化器的需要传入额外参数,比如学习率就是一个常见参数。然后将这些参数作为字典传给基类构造函数:
- 字典的
key是你为这些参数选择的名称,也就是字符串; value是对应的超参数值。
- step(self)
这个方法用于对参数执行一次更新。
在训练循环中,它会在反向传播之后被调用,因此此时可以访问上一个 batch 上计算出的梯度。
PyTorch 优化器 API 有一些细节,所以用一个例子来解释会更容易。
为了让例子更丰富,我们将实现 SGD 的一个轻微变体:学习率会随着训练过程衰减。它从初始学习率 α 开始,然后随着时间推移,更新步长逐渐变小:
$$ \theta_{t+1} = \theta_t - \frac{\alpha}{\sqrt{t+1}} \nabla L(\theta_t;B_t) $$实现:
from collections.abc import Callable, Iterable
from typing import Optional
import torch
import math
class SGD(torch.optim.Optimizer):
def __init__(self, params, lr=1e-3):
if lr < 0:
raise ValueError(f"Invalid learning rate: {lr}")
defaults = {"lr": lr}
super().__init__(params, defaults)
def step(self, closure: Optional[Callable] = None):
loss = None if closure is None else closure()
for group in self.param_groups:
lr = group["lr"] # 获取学习率
for p in group["params"]:
if p.grad is None:
continue
state = self.state[p] # 获取与参数 p 关联的状态
t = state.get("t", 0) # 从状态中获取迭代次数;如果没有则为 0
grad = p.grad.data # 获取损失相对于 p 的梯度
p.data -= lr / math.sqrt(t + 1) * grad # 原地更新权重张量
state["t"] = t + 1 # 迭代次数加 1
return loss
API 规定,用户可以传入一个可调用对象 closure,用于在优化器执行 step 之前重新计算 loss。我们将使用的优化器并不需要这个功能,但为了符合 PyTorch API,我们仍然加上它。
为了观察它是否正常工作,可以使用下面这个最小训练循环示例:
weights = torch.nn.Parameter(5 * torch.randn((10, 10)))
opt = SGD([weights], lr=1)
for t in range(300):
opt.zero_grad()
loss = (weights**2).mean()
print(loss.cpu().item())
loss.backward()
opt.step()
3.3 AdamW
3.3.1 AdamW 原理
AdamW = Adam + decoupled weight decay
即:
- Adam 负责根据一阶矩、二阶矩自适应调整更新步长;
- Weight decay 负责正则化,把参数往 0 拉;
- AdamW 的关键改进是:weight decay 与梯度更新解耦。
普通 Adam 中,weight decay 往往会被混进梯度里,相当于优化:
$$ g_t = \nabla_\theta L(\theta_t) + \lambda \theta_t $$然后再用 Adam 的动量和自适应缩放处理这个梯度。
但 AdamW 的做法是:
- 先单独做 weight decay:$\theta \leftarrow \theta - \alpha \lambda \theta$
- 再做 Adam 风格的梯度更新:$\theta \leftarrow \theta - \alpha_t \frac{m}{\sqrt{v}+\epsilon}$
这就是所谓的 decoupled weight decay:权重衰减不再作为梯度的一部分,而是作为独立步骤作用在参数上。
AdamW 维护了以下状态:
对于每个参数 θ,AdamW 维护两个张量:
- 一阶矩估计
m
它类似于梯度的 指数滑动平均,可以理解为带动量的平均梯度。
直观上理解其合理性:
- 当前梯度 g 可能有噪声;
- m 汇总了过去梯度方向;
- 更新方向更平滑、更稳定。
- 二阶矩估计
它是梯度平方的指数滑动平均。
直观上理解其合理性:
- 如果某个参数方向上梯度长期很大,说明这个方向变化剧烈;
- AdamW 会用 $\sqrt{v}$ 缩放更新量;
- 这样每个参数都有自适应学习率。
- AdamW 的完整更新流程

3.3.2 Implement AdamW (2 points)
因为前面SGD讲义给了个优化器的实现模板,那么按照公式实现就行了:
AdamW.py
import torch
from torch.optim import Optimizer
class AdamW(Optimizer):
def __init__(
self,
params,
lr: float = 1e-3,
betas: tuple[float, float] = (0.9, 0.999),
eps: float = 1e-8,
weight_decay: float = 0.01,
):
if lr < 0:
raise ValueError(f"Invalid learning rate: {lr}")
if eps < 0:
raise ValueError(f"Invalid epsilon value: {eps}")
if not 0 <= betas[0] < 1:
raise ValueError(f"Invalid beta1 value: {betas[0]}")
if not 0 <= betas[1] < 1:
raise ValueError(f"Invalid beta2 value: {betas[1]}")
if weight_decay < 0:
raise ValueError(f"Invalid weight_decay value: {weight_decay}")
defaults = {
"lr": lr,
"betas": betas,
"eps": eps,
"weight_decay": weight_decay,
}
super().__init__(params, defaults)
def step(self, closure=None):
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
with torch.no_grad():
for group in self.param_groups:
lr = group["lr"]
beta1, beta2 = group["betas"]
eps = group["eps"]
weight_decay = group["weight_decay"]
for p in group["params"]:
if p.grad is None:
continue
grad = p.grad
if grad.is_sparse:
raise RuntimeError("AdamW does not support sparse gradients")
state = self.state[p]
if len(state) == 0:
state["t"] = 0
state["m"] = torch.zeros_like(p)
state["v"] = torch.zeros_like(p)
m = state["m"]
v = state["v"]
state["t"] += 1
t = state["t"]
if weight_decay != 0:
p.add_(p, alpha=-lr * weight_decay)
m.mul_(beta1).add_(grad, alpha=1 - beta1)
v.mul_(beta2).addcmul_(grad, grad, value=1 - beta2)
lr_t = lr * ((1 - beta2 ** t) ** 0.5) / (1 - beta1 ** t)
p.addcdiv_(m, v.sqrt().add(eps), value=-lr_t)
return loss
adapters.py
def get_adamw_cls() -> Any:
"""
Returns a torch.optim.Optimizer that implements AdamW.
"""
return AdamW
测试结果:
3.4 Implement cosine learning rate schedule with warmup (1 point)
余弦退火优化器就是随着迭代次数,学习率平滑上升,又平滑下降的过程。
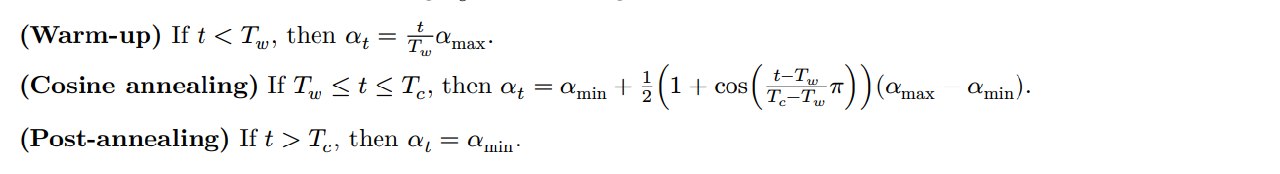
公式有了直接搓就行。
lr_cosine_shedule.py
import torch, math
from torch import nn
class CosineSchedule:
def __init__(
self,
max_learning_rate: float,
min_learning_rate: float,
warmup_iters: int,
cosine_cycle_iters: int,
):
self.max_learning_rate = max_learning_rate
self.min_learning_rate = min_learning_rate
self.warmup_iters = warmup_iters
self.cosine_cycle_iters = cosine_cycle_iters
def __call__(self, it):
if it < self.warmup_iters:
return self.max_learning_rate * it / self.warmup_iters
elif it > self.cosine_cycle_iters:
return self.min_learning_rate
else:
return self.min_learning_rate + (self.max_learning_rate - self.min_learning_rate) * (1 + math.cos(math.pi * (it - self.warmup_iters) / (self.cosine_cycle_iters - self.warmup_iters))) / 2
adapters.py
def run_get_lr_cosine_schedule(
it: int,
max_learning_rate: float,
min_learning_rate: float,
warmup_iters: int,
cosine_cycle_iters: int,
):
"""
Given the parameters of a cosine learning rate decay schedule (with linear
warmup) and an iteration number, return the learning rate at the given
iteration under the specified schedule.
Args:
it (int): Iteration number to get learning rate for.
max_learning_rate (float): alpha_max, the maximum learning rate for
cosine learning rate schedule (with warmup).
min_learning_rate (float): alpha_min, the minimum / final learning rate for
the cosine learning rate schedule (with warmup).
warmup_iters (int): T_w, the number of iterations to linearly warm-up
the learning rate.
cosine_cycle_iters (int): T_c, the number of cosine annealing iterations.
Returns:
Learning rate at the given iteration under the specified schedule.
"""
scheduler = CosineSchedule(max_learning_rate, min_learning_rate, warmup_iters, cosine_cycle_iters)
return scheduler(it)
测试结果:
3.5 Implement gradient clipping (1 point)

梯度裁剪就是对所有梯度算一下l2范式,如果超了,就乘一下系数缩小到指定上界。
实现方面值得注意的是
grad = grad * fac
不会修改原来参数的梯度,只是把局部变量指向了新值
可以写 grad.mul_ 或者 grad *=
gradient_clipping.py
import torch
from collections.abc import Iterable
def gradient_clipping(parameters: Iterable[torch.nn.Parameter], max_l2_norm: float, eps = 1E-6) -> None:
grads = [x.grad for x in parameters if x.grad is not None]
grad_vals = torch.concat([x.flatten() for x in grads])
l2 = torch.norm(grad_vals, 2)
if l2 > max_l2_norm:
fac = max_l2_norm / (l2 + eps)
for grad in grads:
# grad = grad * fac
grad.mul_(fac)
adapters.py
def run_gradient_clipping(parameters: Iterable[torch.nn.Parameter], max_l2_norm: float) -> None:
"""Given a set of parameters, clip their combined gradients to have l2 norm at most max_l2_norm.
Args:
parameters (Iterable[torch.nn.Parameter]): collection of trainable parameters.
max_l2_norm (float): a positive value containing the maximum l2-norm.
The gradients of the parameters (parameter.grad) should be modified in-place.
"""
return gradient_clipping(parameters, max_l2_norm)
测试结果:
四、Training loop
4.1 Implement data loading (2 points)
这里就是让你从一段序列中随机采样一段给定长度的子数组,作为输入x,然后x向右偏移一个元素的子数组作为x的预测y。
dataloader.py
import numpy as np
import torch
def get_batch(x: np.ndarray, batch_size: int, context_length: int, device: str):
starts = np.random.randint(0, len(x) - context_length, size=batch_size)
# starts: [batch_size]
# starts[:, None]: [batch_size, 1]
idx = starts[:, None] + np.arange(context_length)
inputs = torch.from_numpy(x[idx]).long().to(device)
targets = torch.from_numpy(x[idx + 1]).long().to(device)
return inputs, targets
adapters.py
def run_get_batch(
dataset: npt.NDArray, batch_size: int, context_length: int, device: str
) -> tuple[torch.Tensor, torch.Tensor]:
"""
Given a dataset (a 1D numpy array of integers) and a desired batch size and
context length, sample language modeling input sequences and their corresponding
labels from the dataset.
Args:
dataset (np.array): 1D numpy array of integer token IDs in the dataset.
batch_size (int): Desired batch size to sample.
context_length (int): Desired context length of each sampled example.
device (str): PyTorch device string (e.g., 'cpu' or 'cuda:0') indicating the device
to place the sampled input sequences and labels on.
Returns:
Tuple of torch.LongTensors of shape (batch_size, context_length). The first tuple item
is the sampled input sequences, and the second tuple item is the corresponding
language modeling labels.
"""
device = 'cuda' if torch.cuda.is_available() else 'cpu'
return get_batch(dataset, batch_size, context_length, device)
测试结果:

4.2 Checkpointing
就是用 torch.load 和 torch.save 实现model、optimizer权重字典以及当前迭代轮次的存储和加载。
checkpoint.py
import os
import torch
import typing
from torch import nn
def save_checkpoint(
model: nn.Module,
optimizer: torch.optim.Optimizer,
iteration: int,
out: str | os.PathLike | typing.BinaryIO | typing.IO[bytes],
):
torch.save({
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'iteration': iteration
}, out)
def load_checkpoint(
src: str | os.PathLike | typing.BinaryIO | typing.IO[bytes],
model: torch.nn.Module,
optimizer: torch.optim.Optimizer,
) -> int:
checkpoint = torch.load(src)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
iteration = checkpoint['iteration']
return iteration
adapters.py
def run_save_checkpoint(
model: torch.nn.Module,
optimizer: torch.optim.Optimizer,
iteration: int,
out: str | os.PathLike | BinaryIO | IO[bytes],
):
"""
Given a model, optimizer, and an iteration number, serialize them to disk.
Args:
model (torch.nn.Module): Serialize the state of this model.
optimizer (torch.optim.Optimizer): Serialize the state of this optimizer.
iteration (int): Serialize this value, which represents the number of training iterations
we've completed.
out (str | os.PathLike | BinaryIO | IO[bytes]): Path or file-like object to serialize the model, optimizer, and iteration to.
"""
save_checkpoint(model, optimizer, iteration, out)
def run_load_checkpoint(
src: str | os.PathLike | BinaryIO | IO[bytes],
model: torch.nn.Module,
optimizer: torch.optim.Optimizer,
) -> int:
"""
Given a serialized checkpoint (path or file-like object), restore the
serialized state to the given model and optimizer.
Return the number of iterations that we previously serialized in
the checkpoint.
Args:
src (str | os.PathLike | BinaryIO | IO[bytes]): Path or file-like object to serialized checkpoint.
model (torch.nn.Module): Restore the state of this model.
optimizer (torch.optim.Optimizer): Restore the state of this optimizer.
Returns:
int: the previously-serialized number of iterations.
"""
return load_checkpoint(src, model, optimizer)
测试结果:

五、Generating text
5.1 decode tricks
我们将使用较小的模型进行实验,而小模型有时可能会生成质量很低的文本。讲义介绍了两个简单的解码技巧可以帮助缓解这些问题。
1. Temperature scaling:温度缩放
首先,在 temperature scaling 中,我们使用一个温度参数 $\tau$ 来修改 softmax。新的 softmax 为:
$$ \text{softmax}(v,\tau)_i = \frac{\exp(v_i/\tau)} {\sum_{j=1}^{\text{vocab\_size}}\exp(v_j/\tau)} $$注意,当:
$$ \tau \to 0 $$时,$v$ 中最大的元素会占据主导地位,softmax 的输出会变成一个集中在最大元素上的 one-hot 向量。
2. Nucleus / Top-p sampling:核采样 / Top-p 采样
第二个技巧是 nucleus sampling,也叫 top-p sampling。它通过截断低概率 token 来修改采样分布。
令 $q$ 表示一个概率分布,它来自大小为 vocab_size 的经过温度缩放 softmax 后的结果。
带有超参数 $p$ 的核采样会根据下面的公式产生下一个 token:
$$ P(x_{t+1}=i\mid q) = \begin{cases} \frac{q_i}{\sum_{j\in V(p)}q_j}, & \text{if } i\in V(p) \\ 0, & \text{otherwise} \end{cases} $$其中,$V(p)$ 是满足下面条件的最小索引集合:
$$ \sum_{j\in V(p)}q_j \geq p $$这个集合很好求,按概率降序排序,然后顺序取,概率和超过p就停。

说些什么吧!