
零、写在前面
噪声对比估计(Noise Contrastive Estimation, 简称 NCE) 是由 Gutmann 和 Hyvärinen 在 2010 年提出的一种强大的参数估计算法。它主要用于解决**非归一化概率模型(Unnormalized Models)**中配分函数(Partition Function)难以计算的问题。
现如今,NCE 的思想深深影响了自然语言处理(如 Word2Vec)和计算机视觉(如 SimCLR、MoCo 等对比学习方法中的 InfoNCE)。
一、为什么要用 NCE?
在统计机器学习和深度学习中,我们经常需要拟合一个概率分布。对于离散数据(比如语言模型预测下一个单词),我们通常使用 Softmax 函数:
$$ P_\theta(x) = \frac{\exp(u_\theta(x))}{Z(\theta)} $$其中:
- $u_\theta(x)$ 是模型(如神经网络)输出的未归一化的分数(Logits)。
- $Z(\theta) = \sum_{x \in V} \exp(u_\theta(x))$ 是配分函数(归一化常数)。
痛点在于: 如果词表大小 $V$ 非常大(比如几十万个词),或者 $x$ 是连续的高维变量(积分代替求和),计算 $Z(\theta)$ 的成本是极高的。如果我们用传统的最大似然估计(MLE)来优化,每次梯度下降都需要计算 $Z(\theta)$ 及其梯度,这在工程上几乎不可行。
NCE 的目标:避开计算 $Z(\theta)$,依然能够准确估计模型参数 $\theta$。
二、核心思想
NCE的核心思想:将“无监督的生成问题”转化为“有监督的二分类问题”。
既然直接拟合数据分布太难,那我们就引入一个已知的、容易采样的噪声分布 $p_n(x)$。 然后,我们训练一个二分类器,让它去区分:
- 正样本(Data): 来自真实数据分布 $p_d(x)$ 的样本,标签记为 $D=1$。
- 负样本(Noise): 来自噪声分布 $p_n(x)$ 的样本,标签记为 $D=0$。
只要我们的分类器足够强大,能够完美区分真实数据和噪声,那么它实际上也就“学会”了真实数据的分布 $p_d(x)$。
三、数学推导
1. 设定先验概率
假设我们有一批真实数据,同时我们根据噪声分布 $p_n(x)$ 生成噪声数据。 设定真实数据与噪声数据的比例为 $1 : k$(即每 1 个真实样本,对应 $k$ 个噪声样本)。 那么,对于任意一个进入分类器的样本,它的先验概率为:
- 来自真实数据的概率:$P(D=1) = \frac{1}{1+k}$
- 来自噪声数据的概率:$P(D=0) = \frac{k}{1+k}$
2. 根据贝叶斯定理计算后验概率
给定一个样本 $x$,它属于真实数据($D=1$)的真实后验概率是多少?根据贝叶斯定理:
$$ P(D=1 | x) = \frac{P(x | D=1) P(D=1)}{P(x | D=1) P(D=1) + P(x | D=0) P(D=0)} $$我们知道条件概率就是分布本身:
- $P(x | D=1) = p_d(x)$ (真实数据分布)
- $P(x | D=0) = p_n(x)$ (噪声分布)
代入先验概率,得到:
$$ P(D=1 | x) = \frac{p_d(x) \cdot \frac{1}{1+k}}{p_d(x) \cdot \frac{1}{1+k} + p_n(x) \cdot \frac{k}{1+k}} = \frac{p_d(x)}{p_d(x) + k \cdot p_n(x)} $$同理,它是噪声的后验概率为:
$$ P(D=0 | x) = \frac{k \cdot p_n(x)}{p_d(x) + k \cdot p_n(x)} $$3. 用 $p_\theta(x)$替代$p_d(x)$
在现实中,我们不知道真实的 $p_d(x)$,我们的目的正是用模型 $p_\theta(x)$ 去逼近 $p_d(x)$。因此,我们将上述公式中的 $p_d(x)$ 替换为我们的模型 $p_\theta(x)$,得到分类模型预测的概率:
$$ P_\theta(D=1 | x) = \frac{p_\theta(x)}{p_\theta(x) + k \cdot p_n(x)} $$$$ P_\theta(D=0 | x) = \frac{k \cdot p_n(x)}{p_\theta(x) + k \cdot p_n(x)} $$
但是$p_\theta(x)$的计算不还是要算那个很大的配分函数吗?
NCE 作者提出一个极其大胆的假设:将归一化常数 $Z(\theta)$ 看作是一个普通的可学习参数 $c$,甚至在神经网络能力足够强时,直接强制假设 $Z=1$(即网络输出自动趋于归一化)。
因此,在 NCE 中,我们直接让 $p_\theta(x) = \exp(u_\theta(x))$,彻底抛弃了对配分函数的全局计算。
4. 构建目标函数(交叉熵/对数似然)
既然这是一个二分类问题,我们就用标准的二元交叉熵(或者说最大化对数似然)来作为目标函数 $J(\theta)$。
对于来自真实分布 $p_d$ 的样本 $x$,我们希望 $P_\theta(D=1|x)$ 越大越好; 对于来自噪声分布 $p_n$ 的样本 $y$,我们希望 $P_\theta(D=0|y)$ 越大越好。
目标函数(期望形式)为:
$$ J(\theta) = \mathbb{E}_{x \sim p_d} [\ln P_\theta(D=1 | x)] + k \cdot \mathbb{E}_{y \sim p_n} [\ln P_\theta(D=0 | y)] $$把步骤3中的式子代入,得到 NCE 的最终目标函数公式:
$$ J(\theta) = \mathbb{E}_{x \sim p_d} \left[ \ln \frac{p_\theta(x)}{p_\theta(x) + k \cdot p_n(x)} \right] + k \cdot \mathbb{E}_{y \sim p_n} \left[ \ln \frac{k \cdot p_n(y)}{p_\theta(y) + k \cdot p_n(y)} \right] $$在实际训练中,期望 $\mathbb{E}$ 会被替换为经验平均(即在一个 Batch 内的平均值)。
这个其实还是可以理解的,基于大数定律,我们用样本均值替代期望。
四、为什么 NCE 有效?
我们对目标函数跑梯度下降,真能使得$p_\theta(x)$ 收敛到真实分布 $p_d(x)$ 吗?
我们求导来证明:
第一项的导数: $$ \begin{align} \ln \frac{p_\theta}{p_\theta + k p_n} &= \ln p_\theta - \ln(p_\theta + k p_n) \ \nabla_\theta \ln \frac{p_\theta}{p_\theta + k p_n}&=\nabla_\theta \left( \ln p_\theta - \ln(p_\theta + k p_n) \right)\ &= \nabla_\theta \ln p_\theta - \frac{1}{p_\theta + k p_n} \nabla\theta p_\theta\ &= \nabla_\theta \ln p_\theta - \frac{p_\theta}{p_\theta + k p_n} \nabla\theta \ln p_\theta\ &= \frac{kp_n}{p_\theta + k p_n} \nabla\theta \ln p_\theta\
\end{align} $$
第二项的导数:
$$ \begin{align} \ln \frac{k p_n}{p_\theta + k p_n} &= \ln(k p_n) - \ln(p_\theta + k p_n)\\ \nabla_\theta \ln \frac{k p_n}{p_\theta + k p_n} &= -\frac{p_\theta}{p_\theta + k p_n} \nabla_\theta \ln p_\theta \end{align} $$我们把期望写成积分形式:
$$ \begin{align} \nabla_\theta J(\theta) &= \mathbb{E}_{x \sim p_d} \left[ \frac{k \cdot p_n(x)}{p_\theta(x) + k \cdot p_n(x)} \nabla_\theta \ln p_\theta(x) \right] - k \cdot \mathbb{E}_{y \sim p_n} \left[ \frac{p_\theta(y)}{p_\theta(y) + k \cdot p_n(y)} \nabla_\theta \ln p_\theta(y) \right] \\ &= \int p_d(x) \left[ \frac{k \cdot p_n(x)}{p_\theta(x) + k \cdot p_n(x)} \nabla_\theta \ln p_\theta(x) \right] dx - \int p_n(x) \cdot k \cdot \left[ \frac{p_\theta(x)}{p_\theta(x) + k \cdot p_n(x)} \nabla_\theta \ln p_\theta(x) \right] dx \\ &= \int \left[ \color{blue}{p_d(x)} - \color{blue}{p_\theta(x)} \right] \color{red}{\left[ \frac{k \cdot p_n(x)}{p_\theta(x) + k \cdot p_n(x)} \nabla_\theta \ln p_\theta(x) \right]} dx \end{align} $$我们发现最大化 NCE 的目标函数,其全局最优解正是使得模型分布完全等于真实数据分布。
五、实验验证
简单写一个浅一点的神经网络,然后以一个双峰高斯分布为真实数据,选一个简单的、很宽的单峰高斯分布为噪声数据。以NCE作为loss,看看训练出来的结果如何。
5.1 如何把公式写成代码?
$$ \begin{align} P_\theta(D=1|x) &= \frac{exp(u_\theta(x))}{exp(u_\theta(x) + k\cdot p_n(x))} \\ &= \frac{1}{1 + exp(log(k\cdot p_n(x)) - u_\theta(x))} \\ &= Sigmoid(u_\theta(x) - log(k \cdot p_n(x))) \end{align} $$5.2 代码验证
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
def sample_real_data(batch_size):
msk = torch.rand(batch_size) > 0.5
sample1 = torch.randn(batch_size) * 0.5 - 2.0
sample2 = torch.randn(batch_size) * 0.5 + 2.0
return torch.where(msk, sample1, sample2).unsqueeze(1)
noise_dist = torch.distributions.Normal(0.0, 4.0)
def sample_noise_data(batch_size):
return noise_dist.sample((batch_size, 1))
class EnergyModel(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(1, 32),
nn.ReLU(),
nn.Linear(32, 32),
nn.ReLU(),
nn.Linear(32, 1)
)
def forward(self, x):
return self.net(x)
model = EnergyModel()
optimizer = optim.Adam(model.parameters(), lr=1e-2)
criterion = nn.BCEWithLogitsLoss() # binary classificaion cross entropy
batch_size = 512
k = 5
epochs = 300
for epoch in range(epochs):
# 1:k sample
x_real = sample_real_data(batch_size)
x_noise = sample_noise_data(batch_size * k)
x_all = torch.cat([x_real, x_noise], dim=0)
u_theta = model(x_all)
log_p_n = noise_dist.log_prob(x_all)
logits = u_theta - np.log(k) - log_p_n
labels_real = torch.ones(batch_size, 1)
labels_noise = torch.zeros(batch_size * k, 1)
labels = torch.cat([labels_real, labels_noise], dim=0)
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 50 == 0:
print(f"Epoch {epoch + 1}/{epochs}, Loss: {loss.item():.4f}")
Epoch 50/300, Loss: 0.4031
Epoch 100/300, Loss: 0.3607
Epoch 150/300, Loss: 0.3159
Epoch 200/300, Loss: 0.3107
Epoch 250/300, Loss: 0.3240
Epoch 300/300, Loss: 0.3147
print("Training finished! Plotting results...")
model.eval()
Training finished! Plotting results...
EnergyModel(
(net): Sequential(
(0): Linear(in_features=1, out_features=32, bias=True)
(1): ReLU()
(2): Linear(in_features=32, out_features=32, bias=True)
(3): ReLU()
(4): Linear(in_features=32, out_features=1, bias=True)
)
)
x_test = torch.linspace(-8, 8, 400).unsqueeze(1)
with torch.no_grad():
u_theta_test = model(x_test)
p_theta_unnormalized = torch.exp(u_theta_test).numpy()
x_test_np = x_test.numpy()
plt.figure(figsize=(10, 6))
real_samples = sample_real_data(10000).numpy()
plt.hist(real_samples, bins=60, density=True, alpha=0.3, color='blue', label='True Data Histogram (Bimodal)')
noise_pdf = torch.exp(noise_dist.log_prob(x_test)).numpy()
plt.plot(x_test_np, noise_pdf, 'g--', label='Noise Distribution p_n(x)')
scale_factor = np.max(p_theta_unnormalized) / 0.4 # 0.4 约是直方图最高点
plt.plot(x_test_np, p_theta_unnormalized / scale_factor, 'r-', linewidth=2, label='Learned unnormalized p_theta(x)')
plt.legend()
plt.title("NCE: Learning Data Distribution via Binary Classification")
plt.show()
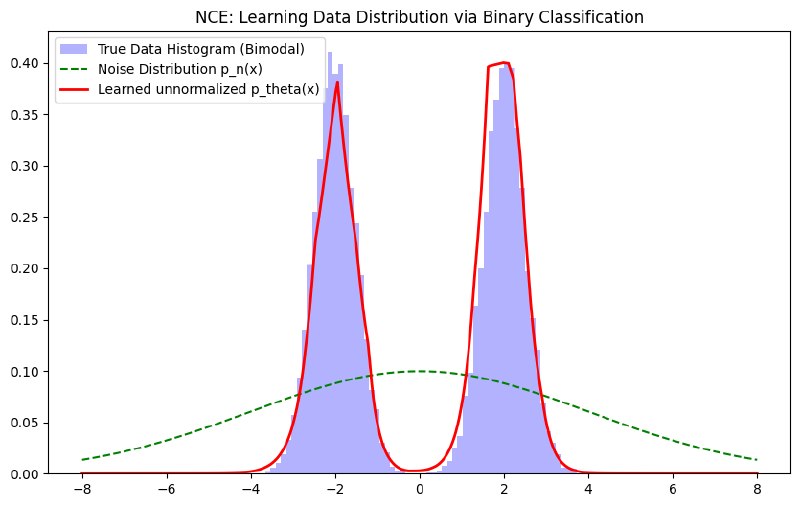
效果还不错。

说些什么吧!