
一、Transformer
1.1 Seq2Seq
**Seq2Seq(序列到序列)**模型输入和输出都是一个序列,输入与输出序列长度之间的关系有两种情况。
- 输入跟输出的长度一样
- 机器决定输出的长度。
序列到序列模型的常见应用:
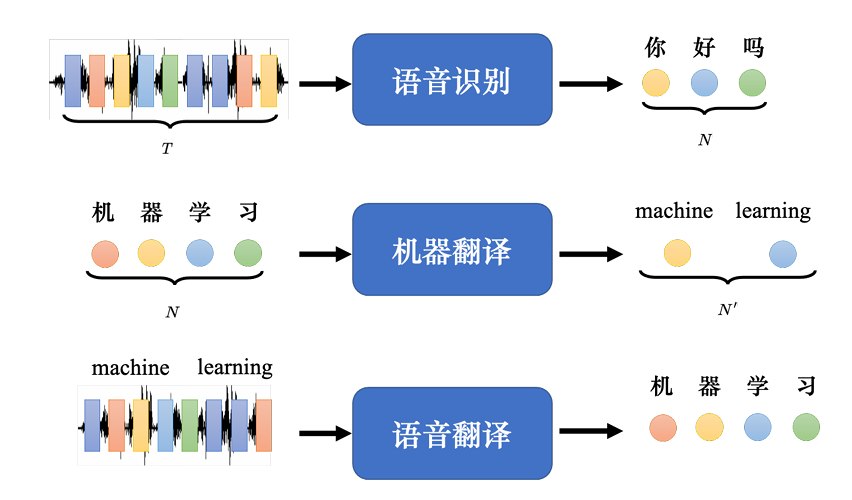
Q:既然把语音识别系统跟机器翻译系统接起来就能达到语音翻译的效果,那么为什么 要做语音翻译?
A:世界上很多语言是没有文字的,无法做语音识别。因此需要对这些语言做语音翻译, 直接把它翻译成文字。
1.2 Transformer 结构
一般的序列到序列模型会分成Encoder(编码器)和Decoder(解码器)。编码器负责处理输入的序列,再把处理好的结果“丢”给解码器,由解码器决定要输出的序列。
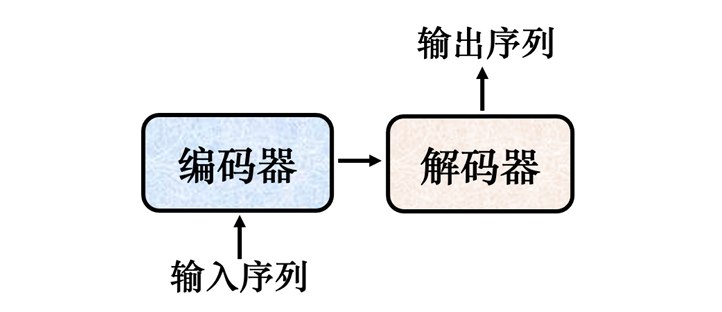
序列到序列典型的模型就 是Transformer,其有一个编码器架构和一个解码器架构:
1.3 Transformer 编码器
Transformer 的编码器使用的是自注意力,输入一排向量,输出另外一个同样长度的向量。
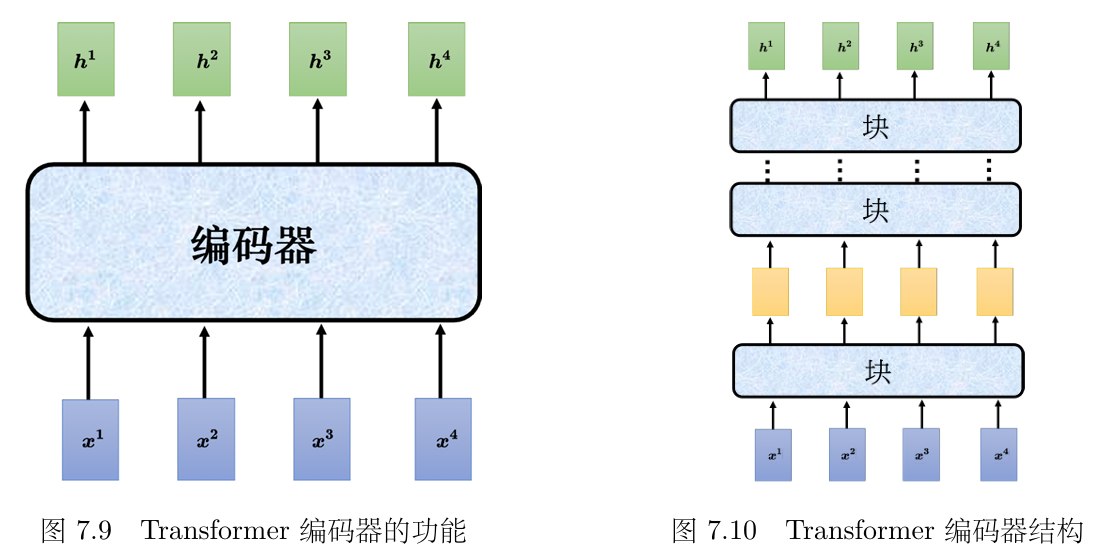
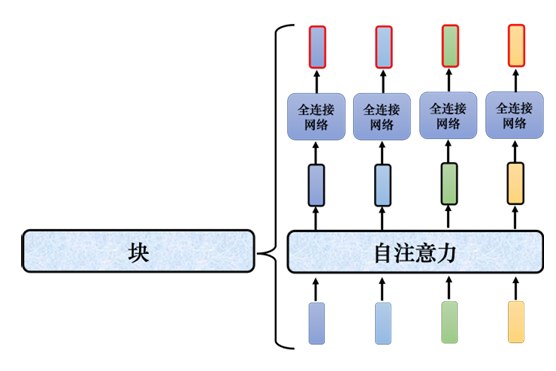
编码器里面会分成很多的块(block),每一个块都是输入一排向量,输出一排向量。输入一排向量到第一个块,第一个块输出另外一排向量,以此类推,最后一个块会输出最终的向量序列。
Transformer的编码器的每个块并不是神经网络的一层,,在每个块里面,输入一排向量后做自注意力,考虑整个序列的信息,输出另外一排向量:
Transformer 里面加入了**残差连接(residual connection)**的设计:
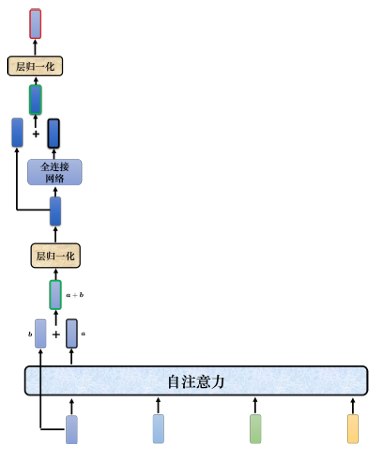
最左边的向量b输入到自注意力层后得到向量a,输出向量a加上其输入向量b得到新的输出。得到残差的结果以后,再做层归一化(layer normalization)。层归一化不需要考虑批量的信息,而批量归一化需要考虑批量的信息。
- Batch Norm 是“纵向”归一化: 它沿着 Batch 维度 ($N$) 进行计算。对于 $D$ 个特征中的每一个特征,BN 会计算这 $N$ 个样本在该特征上的均值和方差。
- Layer Norm 是“横向”归一化: 它沿着 Feature 维度 ($D$) 进行计算。对于 $N$ 个样本中的每一个样本,LN 会计算这个样本在所有 $D$ 个特征上的均值和方差。
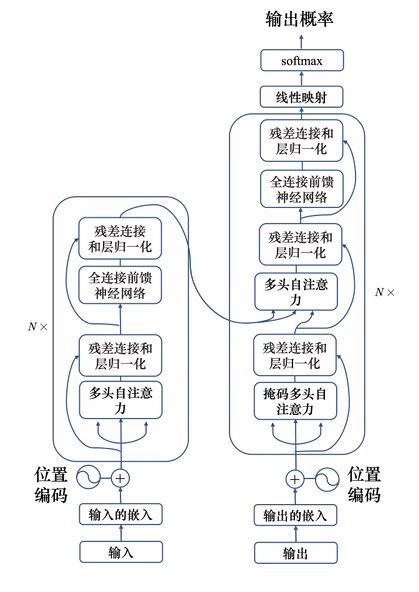
Transformer 的编码器结构:
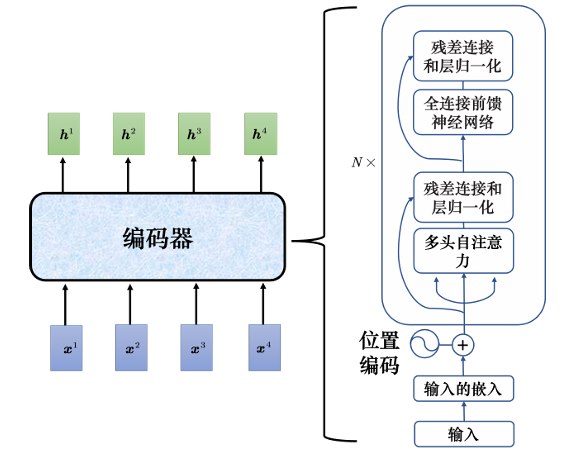
其中 N× 表示重复 N 次。
- 在输入的地方需要加上位置编码。
- 多头自注意力就是自注意力的块。
- 经过自注意力后,还要加上残差连接和层归一化。
- 接下来还要经过全连接的前馈神经网络。
- 接着再做一次残差连接和层归一化。
Transformer 的编码器其实不一定要这样设计,论文**“On Layer Normalization in the Transformer Architecture”**提出了另一种设计,结果比原始的 Transformer 要好。原始的Transformer 的架构并不是一个最优的设计,永远可以思考看看有没有更好的设计方式。
Q:为什么Transformer 中使用层归一化,而不使用批量归一化?
A:论文“PowerNorm: Rethinking Batch Normalization in Transformers”解释了在 Transformers 里面批量归一化不如层归一化的原因,并提出能量归一化(power normalization)。能量归一化跟层归一化性能差不多,甚至好一点。
1.4 Transformer 解码器
1.4.1 自回归解码器
以语音识别为例。把一段声音(“机器学习”)输入给编码器,输出会变成一排向量。
解码器把编码器的输出先“读”进去。但是要让解码器产生输出,我们还要做额外的输入。
首先要先给它一个代表开始的特殊符号**(Begin Of Sentence),这是一个特殊的token**。
假定每一个token都用one-hot vector,那么 也是用one-hot vector来表示。
解码器接收到 后,跟做分类一样,通常会先进行一个softmax 操作。这个向量里面的分数是一个分布,该向量里面的值全部加起 来,总和是1。这个向量会给每一个中文字一个分,分数最高的中文字就是最终的输出。“机” 的分数最高,所以“机”就当做是解码器的第一个输出。
Q:解码器输出的单位是什么?
A:假设做的是中文的语音识别,解码器输出的是中文。词表的大小可能就是中文的方块字的数量。
有人可能会选择输出英语的词汇, 英语的词汇是用空白作为间隔的。但如果都用词汇当作输出又太多了,有一些方法可以把英语的词根、词缀做单位。
- 接下来把“机”当成解码器新的输入。根据两个输入:特殊符号 和“机”,解码器输出一个蓝色的向量。
- 蓝色的向量里面会给出每一个中文字的分数,假设“器” 的分数最高,“器”就是输出。
- 解码器接下来会拿“器”当作输入,其看到了、“机”、“器”, 可能就输出“学”。
- 解码器看到、“机”、“器”、“学”,它会输出一个向量。这个向量里面“习” 的分数最高的,所以它就输出“习”。这个过程就反复地持续下去。
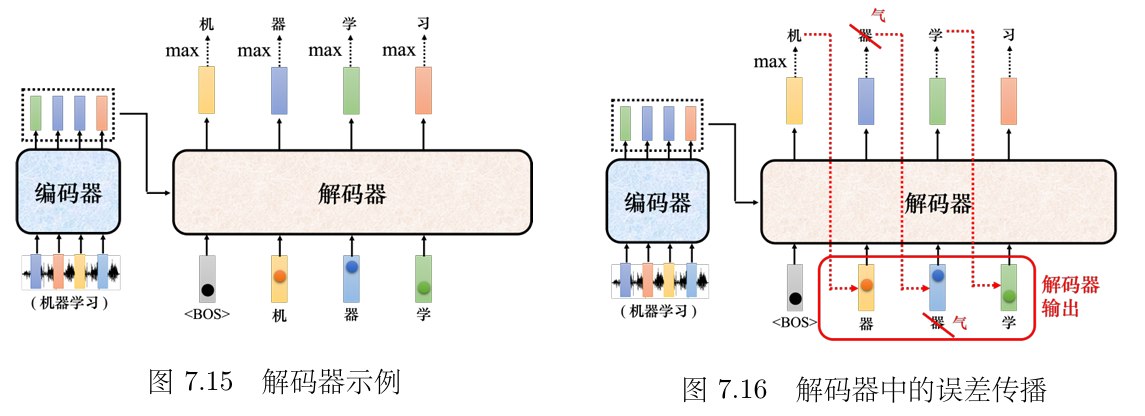
但预测显然可能会出错,造成**误差传播(errorpropagation)**的问题,一步错导致步步错,接下来可能无法再产生正确的词汇。
Transformer 里面的解码器内部的结构如图:
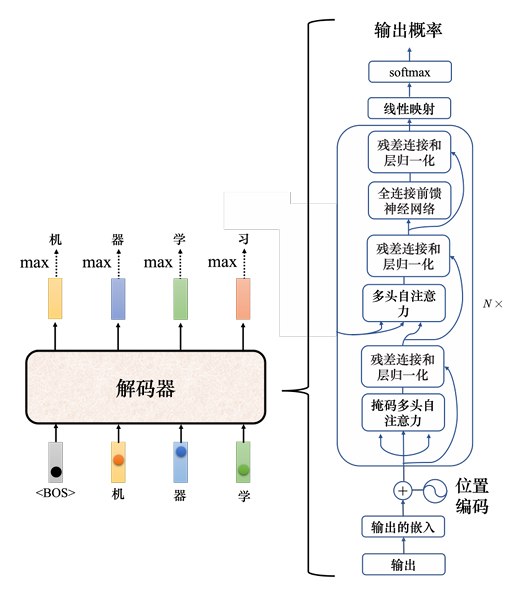
类似于编码器,解码器也有多头注意力、残差连接和层归一化、前馈神经网络。解码器最后再做一个softmax,使其输出变成一个概率。
此外,解码器使用了掩蔽自注意力(maskedself-attention),掩蔽自注意力可以通过一个**掩码(mask)**来阻止每个位置选择其后面的输入信息。
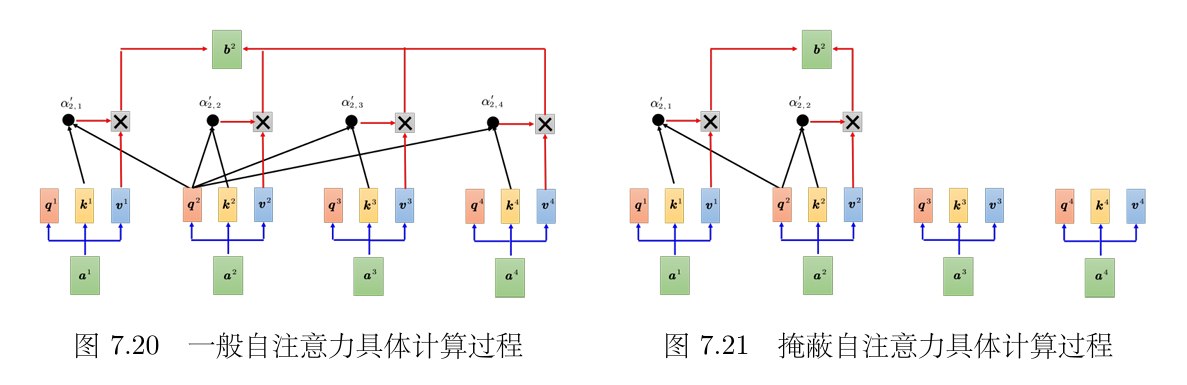
Q: 为什么需要在注意力中加掩码?
A: 一开始解码器的输出是一个一个产生的,所以是先有a1 再有a2,再有 a3,再有 a4。
而之前学的那个注意力是同时输入的。
那么我们一个位置的注意力分数的计算是无法考虑到后面还没产生的输入的,所以要加mask。
知道了运作方式,还有一个关键问题:解码器如何决定输出的序列的长度。
解码器不知道何时停下,所以需要特别准备一个特别的符号。
比如我们预期解码器输出“机器学习”,那么当解码器接收 编码器输出、“机”、“器”、“学”、“习”后,产生出来的向量里面 的概率必须是最大的。
1.4.2 非自回归解码器
自回归模型和RNN一样,串行产生输出,无法并行。所以有了非自回归(non-autoregressive)的模型。
**non-autoregressive(非自回归)**的解码器需要一次得到整个输入,比如我们一次输入一排。
因为输出的长度是未知的,所以 非自回归解码器输入的的数量也是未知的,对此有如下两个做法:
- 用分类器来预测输出长度。把编码器的输入输出到分类器,输出是一个数字,该数字代表解码器应该要输出的长度。
- 比如分类器输出4,非自回归的解码器就会输入4个的token,产生4个中文的字。
- 给编码器一堆的token。
- 假设输出的句子的长度有上限,绝对不会超过300个字。给编码器300个,就会输出300个字,输出右边的的输出就当它没有输出。
非自回归的解码器:
- 并行性强。
- 比较能够控制输出的长度。
- 比如我们做语音合成,我们想要系统讲话快一点,那么把分类器预测的输出长度减半,就可能让系统说话速度变成2倍快。
1.5 编码器-解码器注意力
编码器和解码器通过**编码器-解码器注意力(encoder-decoder attention)**传递信息,编码器-解码器注意力是连接编码器跟解码器之间的桥梁。
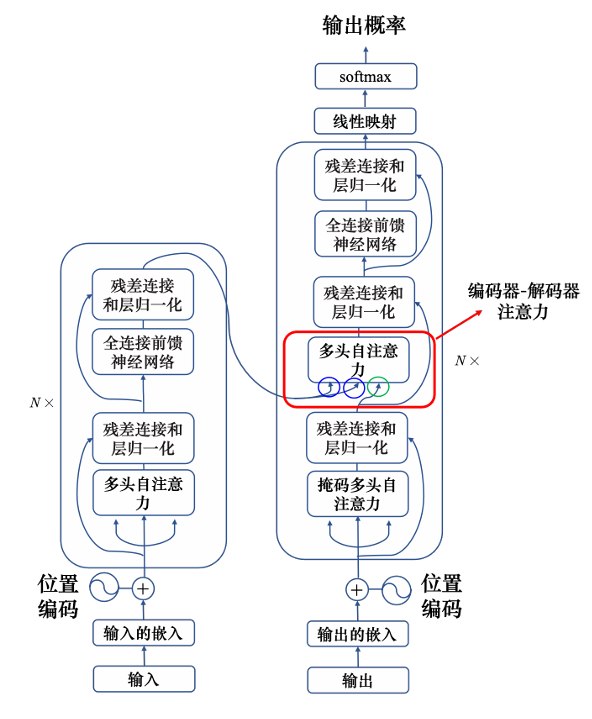
编码器-解码器注意力是这样运作的:
- 解码器输入 ,那么会先在 mask attention 层做自注意力,然后经过残差连接和layer normalize后输出q
- q进入多头自注意力层,这一层我们通常叫 cross attention:
- 编码器输出的向量$a^1、a^2、a^3$会产生key:$k^1、k^2、k^3$ 以及 value:$v^1、v^2、v^3$,那么 q 和 key 计算注意力分数,然后和 value做加权得到输出 $v'$
- 然后进入后续的残差连接 & ayer normalize、全连接前馈神经网络……
解码器的每一块的cross attention 的计算都是和 编码器的输出去计算的。
1.6 Transformer 的训练
1.6.1 Teacher-Forcing
而解码器的输出是一个概率的分布,这个概率分布跟答案的独热向量越接近越好。
所以我们会去计算输出和标准答案之间的交叉熵。交叉熵的值越小越好。
Transformer 在训练时使用了 Teacher-Forcing(教师强制) 技术,结合其独特的架构,实现了并行的、极速的训练。
Teacher-Forcing:在训练的每一步,无论模型上一步预测出了什么,我们都强行(Force)把真实的、正确的标准答案(Ground Truth)作为下一步的输入喂给模型。
好处:
- 可以实现大规模并行训练,使得每一步的输入不依赖于上一步的输出。
- 防止“一步错步步错”导致的训练不稳定
缺点:Exposure Bias(曝光偏差)
在做inference的时候,就没有Teacher-Forcing了,模型不小心生成了一个错词,因为模型在训练时从来没有见过错误的上下文,它完全不知道如何从错误中纠正或恢复,接下来的生成就会彻底崩溃,产生幻觉。
学术界提出了一些方法,比如 Scheduled Sampling(计划采样): 在训练初期,100% 使用 Teacher-Forcing;随着训练进行,逐渐引入一定比例的模型自己的预测结果作为下一步输入,让模型提前适应有错误的上下文。
注:不过在如今动辄千亿参数的 GPT 等大语言模型预训练中,通常依靠海量数据暴力美学,纯粹使用 Teacher-Forcing 依然是最主流、最高效的选择。
1.6.2 复制机制
对很多任务而言,解码器没有必要自己创造输出,其可以从输入的东西里面复制一些东西,来作为其输出。
以聊天机器人为例,用户对机器说:“你好,我是库洛洛”。机器应该回答:“库洛洛你好,很高兴认识你”。
机器其实没有必要创造“库洛洛”这个词汇,“库洛洛”对机器来说一定会是一个非常怪异的词汇,所以它可能很难在训练数据里面 出现,可能一次也没有出现过,所以它不太可能正确地产生输出。
但是假设机器在学的时候, 学到的并不是它要产生“库洛洛”,它学到的是看到输入的时候说“我是某某某”,就直接把“某某某”复制出来,说“某某某你好”。这种机器的训练会比较容易。
最早有从输入复制东西的能力的模型叫做指针网络(pointer network)。
回顾一下标准的 Attention 机制:
- Decoder 生成一个查询向量 $Q$。
- $Q$ 和 Encoder 的所有隐藏状态 $K$ 计算相似度,得到一组 Attention Scores(注意力分数)。
- 对分数做 Softmax,变成加和为 1 的权重分布。
- 将权重与 Encoder 的隐藏状态 $V$ 相乘并求和,得到一个 Context Vector(上下文向量)。
- 拿这个 Context Vector 去经过全连接层,最后在全局大词汇表上算 Softmax,预测下一个词。
Pointer Network 的核心:它在第 3 步直接停下来。
Pointer Network 认为:既然经过 Softmax 后的 Attention 权重代表了“当前 Decoder 在多大程度上关注 Encoder 的各个位置”,那么我为什么还要费劲去算什么 Context Vector、还要去大词表里找词呢?
所以Pointer Network直接把这个 Attention 权重的概率分布作为这步输出的选择概率。
- 假设输入有 5 个
[A, B, C, D, E]。 - Decoder 进行到第 1 步时,算出的 Attention Softmax 概率分别是:
[0.05, 0.8, 0.05, 0.05, 0.05]。 - Pointer Network 则直接判定:概率最高的是 B,所以这一步的输出就是B。
肥肠煎蛋,它把 Attention 机制从一个**“特征融合工具”变成了一个“寻址/指针工具”**。
1.6.3 引导注意力
序列到序列模型有时候训练出来会产生莫名其妙的结果。
以语音合成**(TTS)**为例,要让机器朗读一句话:“我爱人工智能”。
- 机器显然是要从左往右逐个去读的。
- 在注意力矩阵图上(横轴是文本序列,纵轴是时间/音频帧),理想的注意力分布应该是一条完美的、从左上角到右下角的对角线。
但是我们训练过程中不加以引导的话,经常出现:
- 漏读(Skipping): 突然跳过几个字不读。
- 复读机(Repeating): 卡在一个字上一直发同样的音(因为注意力卡在那里不动了)。
- 彻底崩溃(Babbling): 根本形不成对角线,注意力碎了一地,输出全是噪音。
既然我们知道这类任务,注意力矩阵必须是对角线形状,那么就在训练的时候引导注意力:在计算 Loss(损失)的时候,加入一个“对角线惩罚项”。
具体步骤如下:
- 制造一个惩罚矩阵(Mask):
人为生成一个大小与注意力矩阵一模一样的矩阵。这个矩阵的特点是:
- 在对角线附近的区域,数值为 0(安全区)。
- 越远离对角线的区域,数值越大,逐渐趋近于 1(惩罚区)。
- 计算额外 Loss:
在训练时,模型每一步都会输出它自己算出来的 Attention 权重矩阵。我们把模型的 Attention 矩阵和我们人为造的“惩罚矩阵”相乘。
- 如果模型的注意力乖乖地集中在对角线上,乘出来的结果就是 0(因为惩罚矩阵那里是 0)。
- 如果模型的注意力跑到对角线外面去了,乘出来的结果就会很大。
- 反向传播: 把这个结果作为一个额外的 Loss(Guided Attention Loss)加到总的训练 Loss 里。 这样一来,模型在更新权重时,不仅要努力让声音合成得准,还要把注意力往对角线上拉,否则 Loss 就会居高不下。
1.6.4 束搜索
假设我们在做一个机器翻译任务,自回归模型需要一个词一个词地吐出翻译结果。每次面对一个拥有 5 万个单词的词表,模型该怎么选?
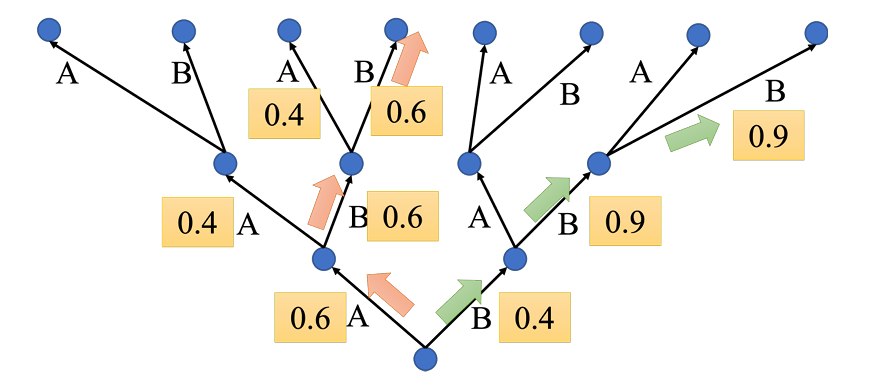
我们决策的过程可以看成一棵搜索树,那如果我们每步都选当前概率最大的节点,最终可能会错过全局最优的句子。
**Beam Search(束搜索)**是一种启发式搜索,引入一个新的参数:Beam Size(束宽),不妨记为k。
每步选择当前概率最高的k条路径走下去。
- 第一步预测一个词,保留概率最高的k个
- 第二步,k个词都各自预测出接下来的若干路径,在总的路径中我们选出概率最高的k个往下走
- ……
也就是始终维护全局的 top k 条路径。

说些什么吧!