
一、SVD
1.1 什么是SVD
SVD(奇异值分解) 线性代数中最重要的矩阵分解之一。
它的核心结论是:任意一个矩阵(不要求是方阵、不要求满秩),都可以分解为“旋转—缩放—旋转”三个因子的乘积。
具体地说,对于 任意 复矩阵$A_{mn} \in \mathbb{C}^{m\times n} $,存在分解:
$$ A_{mn} = U_{mm} \Sigma_{mn} V^T_{nn} $$其中:
- $UU^T = I$,$U$ 的列是$AA^T$的单位正交特征向量
- $VV^T = I$,$V$ 的列是$A^TA$的单位正交特征向量
- $\Sigma$ 是对角矩阵,对角元取$U$和$V$的特征值的非负平方根,并按从大到小排列。
满足:$\sigma_1 \ge \sigma_2 \ge \cdots \ge \sigma_r > 0$,其余对角元素为 0。
- $\sigma_1,\sigma_2,\dots,\sigma_r$ 是 $A$ 的非零奇异值
- $r = \mathrm{rank}(A)$
直观理解: 表示线性变换 \(A\) 的作用过程是:
- 先做 ($V^T$):把输入坐标系旋转到一个合适方向
- 再做 ($Sigma$):沿若干互相正交的方向做缩放
- 最后做 ($U$):把结果再旋转到输出空间中
重要应用:
- 求矩阵秩
- 求最小二乘解
- 求伪逆
- 降维(PCA)
- 数据压缩
- 去噪
- 推荐系统
- NLP / 图像处理
1.2 SVD的构造思路
设 $A \in \mathbb{R}^{m\times n}$
则有$A^T A 是一个 n\times n$ 的对称半正定矩阵,因此可以正交对角化:
$$ A^T A = V \Lambda V^T $$其中:
- $V$ 的列向量是 $A^TA$ 的标准正交特征向量
- $Lambda = \mathrm{diag}(\lambda_1,\lambda_2,\dots,\lambda_n)$
- $\lambda_i \ge 0$
令
$$ \sigma_i = \sqrt{\lambda_i} $$这些就是奇异值。
$V$ 的列向量 $v_i$ 称为 右奇异向量。
它们满足:
$$ A^T A v_i = \sigma_i^2 v_i $$对于每个 $\sigma_i > 0$,定义
$$ u_i = \frac{A v_i}{\sigma_i} $$我们就会发现:
- $u_i$ 两两正交
- $\|u_i\| = 1$
所以 $u_i$ 是一组标准正交向量,称为 左奇异向量。
并且有:
$$ A v_i = \sigma_i u_i $$同时也有:
$$ A^T u_i = \sigma_i v_i $$把这些 $u_i$ 扩展为 $\mathbb{R}^m$ 的一组标准正交基,组成矩阵 $U$,把 $v_i$ 组成矩阵 $V$。
$$ \begin{align} A &= U\Sigma V^T\\ &= AVV^T \\ &= UU^TA\\ &= A \end{align} $$
值得注意的是,$AA^T$和$A^TA$共享非零特征值,几何重数也相同,所以 $\Sigma$ 的表示是唯一的
奇异值分解表明,沿着方向 $v_i$ 输入时,矩阵 $A$ 会把向量拉伸到方向 $u_i$,长度放大为原来的 $\sigma_i$ 倍。
即:$A v_i = \sigma_i u_i$
根据2,可以理解,如果输入主轴为 $v_i$ 的单位球,那么A这一线性变换,会先将主轴旋转到 $u_i$,然后再把主轴长度拉为$\sigma_i$,也就是说,单位球被A变换后变成椭球。
SVD相比于特征值分解的优点:
- 任意矩阵都存在
- 奇异值总是非负实数
- \(U,V\) 可取正交矩阵
- 数值稳定性极好
1.3 Compact SVD
**紧奇异值分解 (Compact SVD)**仅保留非零奇异值(以及对应的奇异向量):
$$ A = U_r \Sigma_r V_r^T $$- 其中,r = rank(A)
这对于表示非满秩矩阵非常节省空间,并且依然精确。
这个表示的准确性,可以用分块矩阵乘法证明,非常简单。
1.4 Truncated SVD
**截断奇异值分解 (Truncated SVD)**只取前 k < r 个最大的奇异值及对应向量:
$$ A_k = U_k \Sigma_k V_k^T $$$A_k$ 不再是 $A$ 本身,而是一个 秩为 $k$ 的低秩逼近。
这是一个非常重要的表示:
Eckart–Young–Mirsky 定理:
在所有秩不超过 $k$ 的矩阵中,$A_k$ 是在谱范数和Frobenius 范数意义下对 $A$ 的最佳逼近:
$$ \|A-A_k\|_2 = \sigma_{k+1}\\ \|A-A_k\|_F = \sqrt{\sum_{i=k+1}^{r}\sigma_{i}^{2}}\\ $$1.5 PCA
PCA(Principal Component Analysis,主成分分析):在尽量少损失信息的前提下,把高维数据投影到低维空间。
SVD 是实现 PCA 最稳定、最常用的方法之一。
1.5.1 动机
$$ (x_1,y_1),(x_2,y_2),\dots,(x_m,y_m) $$如果这些点大致分布在一条斜线上,比如这样:
y
|
| *
| *
| *
| *
|*
+---------------- x
虽然每个点有两个坐标 \((x,y)\),但你会发现:
这些点主要沿着某一个方向变化。
也就是说,虽然数据是二维的,但它的主要信息可能集中在一维方向上。
PCA 就是在问:
能不能找到一个新的坐标轴方向,使得数据在这个方向上的变化最大?
这个方向就是第一主成分。
1.5.2 直观思路
PCA 试图找到一组新的坐标轴:
- 第一根轴:数据变化最大的方向
- 第二根轴:在与第一根轴正交的前提下,数据变化第二大的方向
- 第三根轴:在与前两根轴都正交的前提下,数据变化第三大的方向
- 依此类推
这些新坐标轴叫做:principal components(主成分方向)
什么叫“变化最大”——方差大
假设有一维数据:
1,2,3,4,5
它变化比较明显。
而另一组数据:
2.9,3.0,3.1,3.0,2.95
变化很小。
PCA 认为:
方差越大的方向,越包含主要信息。
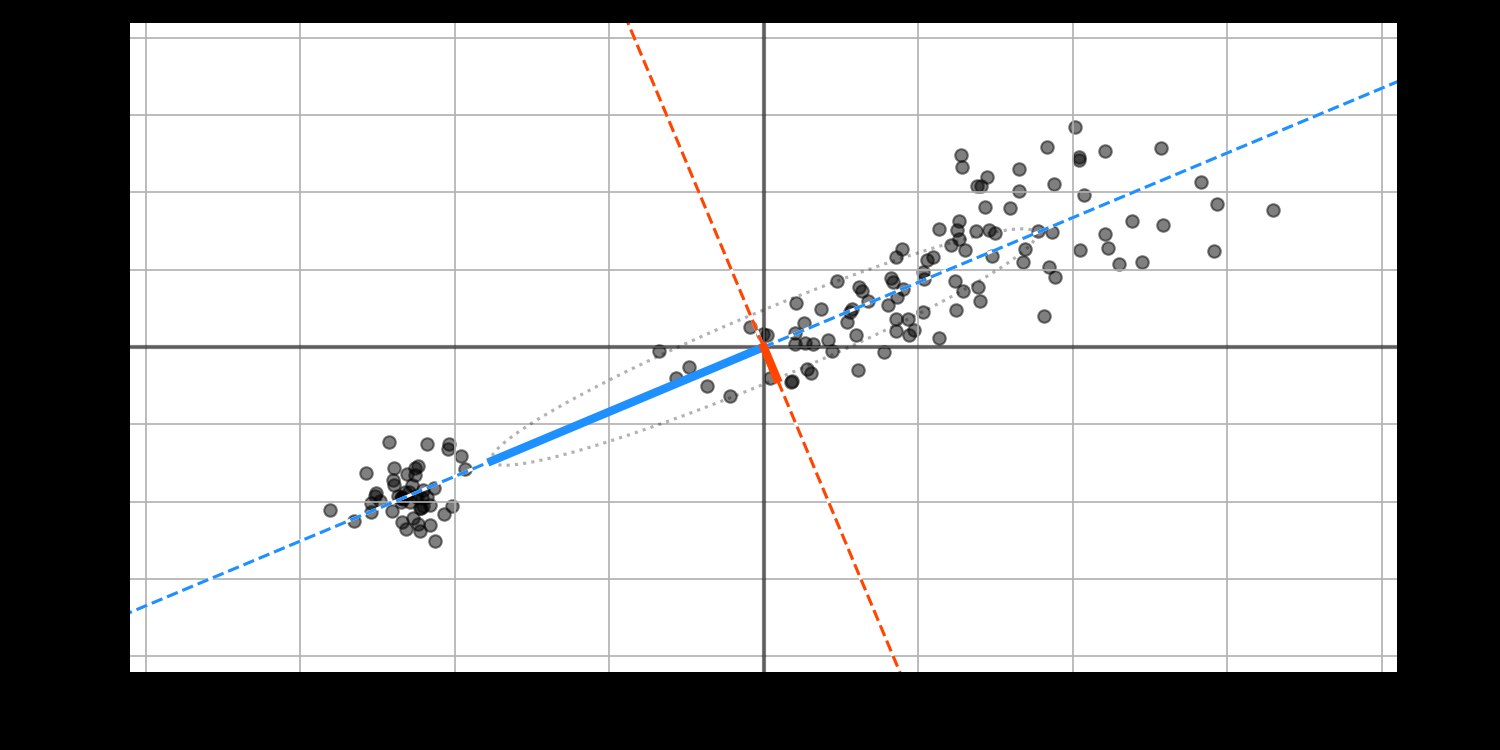
这其实是很好理解的,如上图,蓝线方向显然拟合效果更好,红线为与蓝线垂直的方向,那么数据在红线上的投影,方差特别小。
所以 PCA 的目标是找到一个方向,使得数据投影到这个方向后,投影值的方差最大。
1.5.3 PCA 流程
1、数据矩阵的表示
$$ X \in \mathbb{R}^{m \times n} $$其中:
- m:样本数量
- n:特征数量
例如有 5 个学生,每个学生有 3 个特征:身高、体重、年龄。
$$ X = \begin{bmatrix} 170 & 65 & 18\\ 172 & 70 & 19\\ 168 & 60 & 18\\ 180 & 80 & 20\\ 175 & 75 & 19 \end{bmatrix} $$这里:
- 行表示样本
- 列表示特征
2、中心化
中心化:每一列减去这一列的均值(将每一个特征维度的均值拉到0)。
$$ X_c = X - \bar X $$例如某个特征是:
[170,172,168,180,175]
均值是:173
中心化后变成:
[-3,-1,-5,7,2]
为什么要中心化?
因为 PCA 关心的是数据围绕均值如何变化,而不是数据本身离原点有多远。
如果不中心化,PCA 可能会被数据整体位置误导。
3、PCA 和协方差矩阵
中心化后的数据矩阵是:
$$ X_c \in \mathbb{R}^{m\times n} $$协方差矩阵定义为:
$$ C = \frac{1}{m-1}X_c^T X_c $$- 它是一个 $n\times n$ 矩阵。
- X[i, j] 代表第 i 个特征和第 j 个特征的协方差
- 这是概率统计基础知识,协方差:
- 大于 0:两个特征大致同向变化
- 小于 0:两个特征大致反向变化
- 接近 0:线性关系较弱
协方差矩阵描述的是不同特征之间如何共同变化。
4、数学目标
PCA 要找一个单位方向向量 $w$,使得数据投影到这个方向后方差最大。
对每个样本 $x_i$,投影到 $w$ 上的结果是:
$$ z_i = x_i^T w $$所有样本投影后组成:
$$ z = X_c w $$投影后的方差为:
$$ \frac{1}{m-1}\|X_c w\|^2 $$展开:
$$ \begin{align} &\frac{1}{m-1}(X_c w)^T(X_c w) \\ =&\frac{1}{m-1}w^T X_c^T X_c w \end{align} $$由于协方差矩阵有如下表示:
$$ C = \frac{1}{m-1}X_c^T X_c $$所以投影方差为:
$$ w^T C w $$PCA 的第一主成分就是解这个优化问题:
$$ \max_{\|w\|=1} w^T C w $$5、问题的解是什么?
解是协方差矩阵 \(C\) 的最大特征值对应的特征向量。
证明:二次型最值
也就是说:
- 第一主成分方向 = \(C\) 最大特征值对应的特征向量
- 第二主成分方向 = \(C\) 第二大特征值对应的特征向量
- 第 \(k\) 主成分方向 = \(C\) 第 \(k\) 大特征值对应的特征向量
如果
$$ C v_i = \lambda_i v_i $$并且
$$ \lambda_1 \ge \lambda_2 \ge \cdots \ge \lambda_n $$那么:
- $v_1$ 是第一主成分方向
- $v_2$ 是第二主成分方向
- $\lambda_i$ 表示第 $i$ 个主成分方向上的方差
6、结合SVD
对中心化后的数据矩阵做 SVD:
$$ X_c = U\Sigma V^T $$那么:
$$ \begin{align} X_c^T X_c &= (V\Sigma^T U^T)(U\Sigma V^T) \\ &= V\Sigma^T\Sigma V^T \\ \end{align} $$因为:
$$ C = \frac{1}{m-1}X_c^T X_c $$所以:
$$ C = V\left(\frac{\Sigma^T\Sigma}{m-1}\right)V^T $$这说明:
中心化数据矩阵 $X_c$ 的 SVD 中,$V$ 的列向量就是 PCA 的主成分方向。
并且:
$$ \lambda_i = \frac{\sigma_i^2}{m-1} $$其中:
- $\lambda_i$:第 $i$ 个主成分解释的方差
- $\sigma_i$:第 $i$ 个奇异值
所以:
$$ \text{explained variance}_i = \frac{\sigma_i^2}{m-1} $$1.5.4 总结
经过上面的推导,我们现在对PCA和SVD(很多时候用的是Truncated SVD)的认识已经很清晰了:
principal components(主成分方向):原始特征空间中的一组新坐标轴。
在 SVD 中,它们就是 $V$ 的列向量!
scores:样本在主成分方向上的坐标。
如果选择前 k 个主成分:
$$ V_k = [v_1,\dots,v_k] $$那么降维后的数据是:
$$ Z = X_c V_k $$其中:
$$ Z \in \mathbb{R}^{m\times k} $$这就是每个样本在新坐标系下的表示。
这个推导也不难,就是线性代数中的基变换
假设原始数据 Y 是在主成分方向上的坐标
则有 $VY = X \Rightarrow Y = XV^{-1} = XV^T$
explained variance(每个主成分解释的方差):
$$ \lambda_i = \frac{\sigma_i^2}{m-1} $$explained variance ratio(解释方差占比):
$$ \frac{\lambda_i}{\sum_j \lambda_j} $$例如:
PC1: 85%
PC2: 10%
PC3: 3%
PC4: 2%
这说明前两个主成分已经解释了 95% 的数据方差。
1.5.5 几何意义
假设原始数据是二维的,呈椭圆分布。
PCA 会找到椭圆的长轴和短轴:
*
* *
* *
* *
* *
* *
*
- 长轴方向:第一主成分
- 短轴方向:第二主成分
如果只保留第一主成分,相当于把二维点投影到长轴上。
也就是用一条线尽量表示原始二维数据。
1.5.6 python 可视化
下面构造一个二维椭圆形数据,然后用 PCA 找出主方向。
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
# 1. 生成二维相关数据
n_samples = 300
# 原始随机数据
Z = np.random.randn(n_samples, 2)
# 通过线性变换制造相关性
A = np.array([
[3, 1],
[1, 0.5]
])
X = Z @ A.T
# 2. 中心化
mean = X.mean(axis=0)
X_centered = X - mean
# 3. SVD 做 PCA
U, S, Vt = np.linalg.svd(X_centered, full_matrices=False)
# 主成分方向
components = Vt
# explained variance
explained_variance = S**2 / (n_samples - 1)
explained_variance_ratio = explained_variance / explained_variance.sum()
print("主成分方向:")
print(components)
print("解释方差:")
print(explained_variance)
print("解释方差占比:")
print(explained_variance_ratio)
# 4. 可视化
plt.figure(figsize=(7, 7))
plt.scatter(X[:, 0], X[:, 1], alpha=0.4, label="data")
# 画均值点
plt.scatter(mean[0], mean[1], color="red", s=80, label="mean")
# 画主成分方向
for i in range(2):
direction = components[i]
length = np.sqrt(explained_variance[i]) * 2
start = mean
end = mean + direction * length
plt.arrow(
start[0], start[1],
end[0] - start[0], end[1] - start[1],
head_width=0.15,
head_length=0.25,
linewidth=2,
color=["red", "green"][i],
label=f"PC{i+1}"
)
plt.axis("equal")
plt.grid(True)
plt.legend()
plt.title("PCA via SVD")
plt.show()
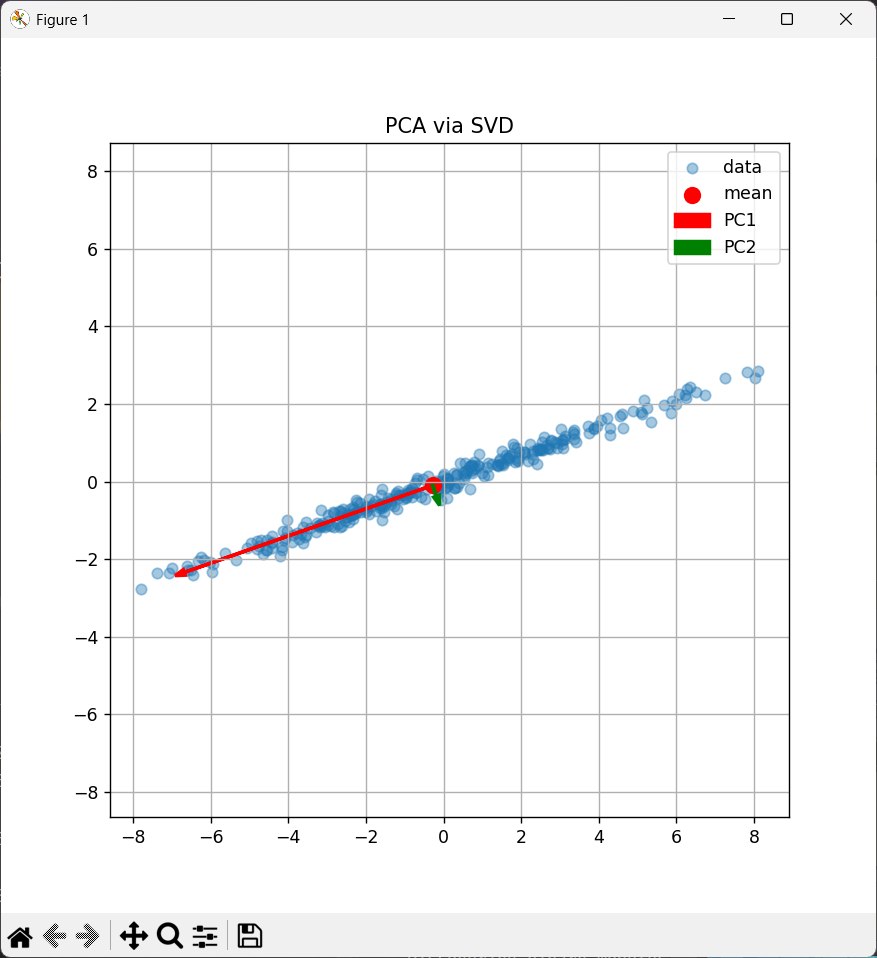
- 数据呈椭圆形
- 第一主成分沿椭圆长轴
- 第二主成分沿椭圆短轴
- 两个主成分方向互相垂直
当然我们平时可以直接调用sklearn等工具库的api
1.6 图像压缩中的 SVD
一张灰度图可以看成矩阵 $A$。
做 SVD:
$$ A = \sum_{i=1}^r \sigma_i u_i v_i^T $$如果只保留前 \(k\) 项:
$$ A_k = \sum_{i=1}^k \sigma_i u_i v_i^T 就得到近似图像。 $$如果奇异值衰减很快,那么 \(k\ll r\) 时图像仍然很清晰,但存储量大幅减少。
这说明:
- 大奇异值对应主要结构
- 小奇异值往往对应细节或噪声
1.7 SVD 与四个基本子空间
设 $A\in\mathbb{R}^{m\times n}$,秩为 \(r\)。
则:
1)列空间 $C(A)$
由 $u_1,\dots,u_r$ 张成。
2)行空间 $C(A^T)$
由 $v_1,\dots,v_r$ 张成。
3)零空间 $N(A)$
由那些对应零奇异值的右奇异向量张成。
4)左零空间 $N(A^T)$
由那些对应零奇异值的左奇异向量张成。
SVD 把矩阵的四个基本子空间全部同时揭示出来了,非常的巧妙欸(⊙o⊙)

说些什么吧!