
零、写在前面
这一章主要讲了下如何对llm进行微调。
本章代码:ch06
一、Fine-tuning for classification
1.1 Different categories of fine-tuning
对语言模型最常用的微调方式有 instruction fine-tuning 以及 classification fine-tuning。
instruction fine-tuning涉及到在基于指令的任务集合上进行训练,然后提高llm对于自然语言prompt的理解以及执行任务的能力。
而 classification fine-tuning则更简单一点,就是对llm在分类问题的数据上训练,只能输出训练的时候见过的类别标签。
显然,instruction fine-tuning更通用,因为可以用于多个领域。classification fine-tuning其实是一种专用模型,比如 翻译、分类……
classification fine-tuning的训练要容易的多,所以本章主要涉及classification fine-tuning。在下一章会进行 instruction fine-tuning。
1.2 准备数据集
import requests
import zipfile
import os
from pathlib import Path
url = "https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip"
zip_path = "sms_spam_collection.zip"
extracted_path = "sms_spam_collection"
data_file_path = Path(extracted_path) / "SMSSpamCollection.tsv"
def download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path):
if data_file_path.exists():
print(f"{data_file_path} already exists. Skipping download and extraction.")
return
# Downloading the file
response = requests.get(url, stream=True, timeout=60)
response.raise_for_status()
with open(zip_path, "wb") as out_file:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
out_file.write(chunk)
# Unzipping the file
with zipfile.ZipFile(zip_path, "r") as zip_ref:
zip_ref.extractall(extracted_path)
# Add .tsv file extension
original_file_path = Path(extracted_path) / "SMSSpamCollection"
os.rename(original_file_path, data_file_path)
print(f"File downloaded and saved as {data_file_path}")
try:
download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)
except (requests.exceptions.RequestException, TimeoutError) as e:
print(f"Primary URL failed: {e}. Trying backup URL...")
url = "https://f001.backblazeb2.com/file/LLMs-from-scratch/sms%2Bspam%2Bcollection.zip"
download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)
这里选择了一个比较小的垃圾邮件分类的数据集。
可以用pandas读一下:
import pandas as pd
df = pd.read_csv(
data_file_path, sep="\t", header=None, names=["Label", "Text"]
)
df
| Label | Text | |
|---|---|---|
| 0 | ham | Go until jurong point, crazy.. Available only … |
| 1 | ham | Ok lar… Joking wif u oni… |
| 2 | spam | Free entry in 2 a wkly comp to win FA Cup fina… |
| 3 | ham | U dun say so early hor… U c already then say… |
| 4 | ham | Nah I don’t think he goes to usf, he lives aro… |
| … | … | … |
| 5567 | spam | This is the 2nd time we have tried 2 contact u… |
| 5568 | ham | Will ü b going to esplanade fr home? |
| 5569 | ham | Pity, * was in mood for that. So…any other s… |
| 5570 | ham | The guy did some bitching but I acted like i’d… |
| 5571 | ham | Rofl. Its true to its name |
5572 rows × 2 columns
df["Label"].value_counts()
Label
ham 4825
spam 747
Name: count, dtype: int64
为了进一步缩减训练时间,作者选择抽出来和垃圾邮件相等数目的非垃圾邮件,来作为训练数据:
def create_balanced_dataset(df):
# Count the instances of "spam"
num_spam = df[df["Label"] == "spam"].shape[0]
# Randomly sample "ham" instances to match the number of "spam" instances
ham_subset = df[df["Label"] == "ham"].sample(num_spam, random_state=123)
# Combine ham "subset" with "spam"
balanced_df = pd.concat([ham_subset, df[df["Label"] == "spam"]])
return balanced_df
balanced_df = create_balanced_dataset(df)
balanced_df["Label"].value_counts()
Label
ham 747
spam 747
Name: count, dtype: int64
然后将label 改成 0/1 两种取值:
balanced_df["Label"] = balanced_df["Label"].map({"ham": 0, "spam": 1})
balanced_df
| Label | Text | |
|---|---|---|
| 4307 | 0 | Awww dat is sweet! We can think of something t… |
| 4138 | 0 | Just got to <#> |
| 4831 | 0 | The word “Checkmate” in chess comes from the P… |
| 4461 | 0 | This is wishing you a great day. Moji told me … |
| 5440 | 0 | Thank you. do you generally date the brothas? |
| … | … | … |
| 5537 | 1 | Want explicit SEX in 30 secs? Ring 02073162414… |
| 5540 | 1 | ASKED 3MOBILE IF 0870 CHATLINES INCLU IN FREE … |
| 5547 | 1 | Had your contract mobile 11 Mnths? Latest Moto… |
| 5566 | 1 | REMINDER FROM O2: To get 2.50 pounds free call… |
| 5567 | 1 | This is the 2nd time we have tried 2 contact u… |
1494 rows × 2 columns
进一步划分训练集、验证集:
def random_split(df, train_frac, validation_frac):
# Shuffle the entire DataFrame
df = df.sample(frac=1, random_state=123).reset_index(drop=True)
# Calculate split indices
train_end = int(len(df) * train_frac)
validation_end = train_end + int(len(df) * validation_frac)
# Split the DataFrame
train_df = df[:train_end]
validation_df = df[train_end:validation_end]
test_df = df[validation_end:]
return train_df, validation_df, test_df
train_df, validation_df, test_df = random_split(balanced_df, 0.7, 0.1)
# Test size is implied to be 0.2 as the remainder
train_df.to_csv("train.csv", index=None)
validation_df.to_csv("validation.csv", index=None)
test_df.to_csv("test.csv", index=None)
1.3 Creating data loaders
序列长短不一,我们有两种选择:
- 选定seq_len为数据集中最短那个,然后长于这个长度的直接截断为seq_len。
- 选定seq_len为数据集中最长那个,然后长度不够的,加 token>进行填充。
截断会丢失信息,pad会让数据集规模变大,不过我们这个数据集很小,直接选择填充。
不过在第二章将tokenizer的时候就介绍过,GPT model 只有 这一种特殊token,所以我们直接用 填充。
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
print(tokenizer.encode("<|endoftext|>", allowed_special={"<|endoftext|>"}))
[50256]
然后就可以写一个dataset:
import torch
from torch.utils.data import Dataset
class SpamDataset(Dataset):
def __init__(self, csv_file, tokenizer, max_length=None, pad_token_id=50256):
self.data = pd.read_csv(csv_file)
# Pre-tokenize texts
self.encoded_texts = [
tokenizer.encode(text) for text in self.data["Text"]
]
if max_length is None:
self.max_length = self._longest_encoded_length()
else:
self.max_length = max_length
# Truncate sequences if they are longer than max_length
self.encoded_texts = [
encoded_text[:self.max_length]
for encoded_text in self.encoded_texts
]
# Pad sequences to the longest sequence
self.encoded_texts = [
encoded_text + [pad_token_id] * (self.max_length - len(encoded_text))
for encoded_text in self.encoded_texts
]
def __getitem__(self, index):
encoded = self.encoded_texts[index]
label = self.data.iloc[index]["Label"]
return (
torch.tensor(encoded, dtype=torch.long),
torch.tensor(label, dtype=torch.long)
)
def __len__(self):
return len(self.data)
def _longest_encoded_length(self):
max_length = 0
for encoded_text in self.encoded_texts:
encoded_length = len(encoded_text)
if encoded_length > max_length:
max_length = encoded_length
return max_length
# Note: A more pythonic version to implement this method
# is the following, which is also used in the next chapter:
# return max(len(encoded_text) for encoded_text in self.encoded_texts)
创建三个dataset:
train_dataset = SpamDataset(
csv_file="train.csv",
max_length=None,
tokenizer=tokenizer
)
train_dataset.max_length
120
val_dataset = SpamDataset(
csv_file="validation.csv",
max_length=train_dataset.max_length,
tokenizer=tokenizer
)
test_dataset = SpamDataset(
csv_file="test.csv",
max_length=train_dataset.max_length,
tokenizer=tokenizer
)
然后创建三个dataloader用于后续训练用:
from torch.utils.data import DataLoader
num_workers = 0
batch_size = 8
torch.manual_seed(123)
train_loader = DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers,
drop_last=True
)
val_loader = DataLoader(
dataset=val_dataset,
batch_size=batch_size,
num_workers=num_workers,
drop_last=False
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=batch_size,
num_workers=num_workers,
drop_last=False
)
for input_batch, target_batch in train_loader:
pass
print("Input batch dimensions:", input_batch.shape)
print("Label batch dimensions", target_batch.shape)
Input batch dimensions: torch.Size([8, 120])
Label batch dimensions torch.Size([8])
print(f"{len(train_loader)} training batches")
print(f"{len(val_loader)} validation batches")
print(f"{len(test_loader)} test batches")
130 training batches
19 validation batches
38 test batches
1.4 用预训练权重初始化模型
这个主要就是上一章的内容,加载GPT-2的权重,不过因为我们要做分类任务微调,那么原来那个输出头肯定不能用了,我们需要用一个二分类的输出头替换。
先加载权重:
CHOOSE_MODEL = "gpt2-small (124M)"
INPUT_PROMPT = "Every effort moves"
BASE_CONFIG = {
"vocab_size": 50257,
"context_length": 1024,
"drop_rate": 0.0,
"qkv_bias": True
}
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
BASE_CONFIG.update(model_configs[CHOOSE_MODEL])
from gpt_download import download_and_load_gpt2
from previous_chapters import GPTModel, load_weights_into_gpt
model_size = CHOOSE_MODEL.split(" ")[-1].lstrip("(").rstrip(")")
settings, params = download_and_load_gpt2(
model_size=model_size, models_dir="gpt2"
)
model = GPTModel(BASE_CONFIG)
load_weights_into_gpt(model, params)
model.eval()
随便测个句子看权重加载正确没:
from previous_chapters import generate_text_simple, text_to_token_ids, token_ids_to_text
text_1 = "Every effort moves you"
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(text_1, tokenizer),
max_new_tokens=15,
context_size=BASE_CONFIG["context_length"]
)
token_ids_to_text(token_ids, tokenizer)
'Every effort moves you forward.\n\nThe first step is to understand the importance of your work'
我们尝试给一个instruction:
text_2 = (
"Is the following text 'spam'? Answer with 'yes' or 'no':"
" 'You are a winner you have been specially"
" selected to receive $1000 cash or a $2000 award.'"
)
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(text_2, tokenizer),
max_new_tokens=23,
context_size=BASE_CONFIG["context_length"]
)
print(token_ids_to_text(token_ids, tokenizer))
Is the following text 'spam'? Answer with 'yes' or 'no': 'You are a winner you have been specially selected to receive $1000 cash or a $2000 award.'
The following text 'spam'? Answer with 'yes' or 'no': 'You are a winner
没有像我们日常生活中用的llm那样给出结果,这是正常的,因为我们还没有进行微调。
1.5 增加分类头
在训练之间,我们需要替换掉原来的输出头。原来的输出头输出的是对于vocab的预测,我们现在要换成垃圾邮件的二分类头。
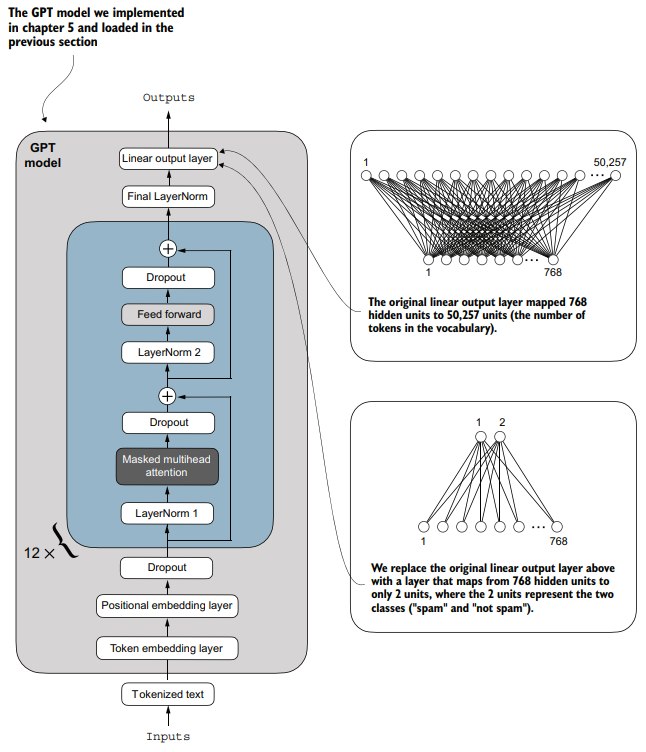
我们可以先打印看一下model架构:
model
GPTModel(
(tok_emb): Embedding(50257, 768)
(pos_emb): Embedding(1024, 768)
(drop_emb): Dropout(p=0.0, inplace=False)
(trf_blocks): Sequential(
(0): TransformerBlock(
(att): MultiHeadAttention(
(W_q): Linear(in_features=768, out_features=768, bias=True)
(W_k): Linear(in_features=768, out_features=768, bias=True)
(W_v): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_shortcut): Dropout(p=0.0, inplace=False)
)
(1): TransformerBlock(
...
)
)
(final_norm): LayerNorm()
(out_head): Linear(in_features=768, out_features=50257, bias=False)
)
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
那么我们只需要替换掉out_head,在那之前,先把模型权重的requires_grad置False:
for param in model.parameters():
param.requires_grad = False
因为我们希望复用已经有的语义提取能力。
然后更换分类头:
torch.manual_seed(123)
num_classes = 2
model.out_head = torch.nn.Linear(
in_features=BASE_CONFIG["emb_dim"],
out_features=num_classes
)
有趣的是,作者做过实验,发现把最后一层 transformer 和 最后一个层归一化的requires_grad置为True,效果最好:
for param in model.trf_blocks[-1].parameters():
param.requires_grad = True
for param in model.final_norm.parameters():
param.requires_grad = True
1.6 classification loss and accuracy
先写个 accuracy 计算函数:
def calc_accuracy_loader(data_loader, model, device, num_batches=None):
model.eval()
correct_predictions, num_examples = 0, 0
if num_batches is None:
num_batches = len(data_loader)
else:
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
with torch.no_grad():
logits = model(input_batch)[:, -1, :]
predicted_labels = torch.argmax(logits, dim=-1)
num_examples += predicted_labels.shape[0]
correct_predictions += ((predicted_labels == target_batch).sum().item())
else:
break
return correct_predictions / num_examples
然后看一下效果:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
torch.manual_seed(123)
train_accuracy = calc_accuracy_loader(
train_loader, model, device, num_batches=10
)
val_accuracy = calc_accuracy_loader(
val_loader, model, device, num_batches=10
)
test_accuracy = calc_accuracy_loader(
test_loader, model, device, num_batches=10
)
print(f"Training accuracy: {train_accuracy*100:.2f}%")
print(f"Validation accuracy: {val_accuracy*100:.2f}%")
print(f"Test accuracy: {test_accuracy*100:.2f}%")
device
Training accuracy: 46.25%
Validation accuracy: 45.00%
Test accuracy: 48.75%
这是符合预期的,基本跟乱猜概率差不多,因为我们还没开始训练。
然后是loss计算:
def calc_loss_batch(input_batch, target_batch, model, device):
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
logits = model(input_batch)[:, -1, :]
loss = torch.nn.functional.cross_entropy(logits, target_batch)
return loss
# Same as in chapter 5
def calc_loss_loader(data_loader, model, device, num_batches=None):
total_loss = 0.
if len(data_loader) == 0:
return float("nan")
elif num_batches is None:
num_batches = len(data_loader)
else:
# Reduce the number of batches to match the total number of batches in the data loader
# if num_batches exceeds the number of batches in the data loader
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
loss = calc_loss_batch(input_batch, target_batch, model, device)
total_loss += loss.item()
else:
break
return total_loss / num_batches
然后是训练函数:
# Same as chapter 5
def evaluate_model(model, train_loader, val_loader, device, eval_iter):
model.eval()
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)
val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)
model.train()
return train_loss, val_loss
# Overall the same as `train_model_simple` in chapter 5
def train_classifier_simple(model, train_loader, val_loader, optimizer, device, num_epochs,
eval_freq, eval_iter):
# Initialize lists to track losses and examples seen
train_losses, val_losses, train_accs, val_accs = [], [], [], []
examples_seen, global_step = 0, -1
# Main training loop
for epoch in range(num_epochs):
model.train() # Set model to training mode
for input_batch, target_batch in train_loader:
optimizer.zero_grad() # Reset loss gradients from previous batch iteration
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward() # Calculate loss gradients
optimizer.step() # Update model weights using loss gradients
examples_seen += input_batch.shape[0] # New: track examples instead of tokens
global_step += 1
# Optional evaluation step
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter)
train_losses.append(train_loss)
val_losses.append(val_loss)
print(f"Ep {epoch+1} (Step {global_step:06d}): "
f"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}")
# Calculate accuracy after each epoch
train_accuracy = calc_accuracy_loader(train_loader, model, device, num_batches=eval_iter)
val_accuracy = calc_accuracy_loader(val_loader, model, device, num_batches=eval_iter)
print(f"Training accuracy: {train_accuracy*100:.2f}% | ", end="")
print(f"Validation accuracy: {val_accuracy*100:.2f}%")
train_accs.append(train_accuracy)
val_accs.append(val_accuracy)
return train_losses, val_losses, train_accs, val_accs, examples_seen
基本都和第五章一样。
1.7 Fine-tuning the model on supervised data
然后就是训练:
import time
start_time = time.time()
torch.manual_seed(123)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5, weight_decay=0.1)
num_epochs = 5
train_losses, val_losses, train_accs, val_accs, examples_seen = \
train_classifier_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=50,
eval_iter=5
)
end_time = time.time()
execution_time_minutes = (end_time - start_time) / 60
print(f"Training completed in {execution_time_minutes:.2f} minutes.")
Ep 1 (Step 000000): Train loss 2.153, Val loss 2.392
Ep 1 (Step 000050): Train loss 0.617, Val loss 0.637
Ep 1 (Step 000100): Train loss 0.523, Val loss 0.557
Training accuracy: 70.00% | Validation accuracy: 72.50%
Ep 2 (Step 000150): Train loss 0.561, Val loss 0.489
Ep 2 (Step 000200): Train loss 0.419, Val loss 0.397
Ep 2 (Step 000250): Train loss 0.409, Val loss 0.353
Training accuracy: 82.50% | Validation accuracy: 85.00%
Ep 3 (Step 000300): Train loss 0.333, Val loss 0.320
Ep 3 (Step 000350): Train loss 0.340, Val loss 0.306
Training accuracy: 90.00% | Validation accuracy: 90.00%
Ep 4 (Step 000400): Train loss 0.136, Val loss 0.200
Ep 4 (Step 000450): Train loss 0.153, Val loss 0.132
Ep 4 (Step 000500): Train loss 0.222, Val loss 0.137
Training accuracy: 100.00% | Validation accuracy: 97.50%
Ep 5 (Step 000550): Train loss 0.207, Val loss 0.143
Ep 5 (Step 000600): Train loss 0.083, Val loss 0.074
Training accuracy: 100.00% | Validation accuracy: 97.50%
Training completed in 1.23 minutes.
用的破游戏本的3050Ti
画个图可视化一下:
import matplotlib.pyplot as plt
def plot_values(epochs_seen, examples_seen, train_values, val_values, label="loss"):
fig, ax1 = plt.subplots(figsize=(5, 3))
# Plot training and validation loss against epochs
ax1.plot(epochs_seen, train_values, label=f"Training {label}")
ax1.plot(epochs_seen, val_values, linestyle="-.", label=f"Validation {label}")
ax1.set_xlabel("Epochs")
ax1.set_ylabel(label.capitalize())
ax1.legend()
# Create a second x-axis for examples seen
ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis
ax2.plot(examples_seen, train_values, alpha=0) # Invisible plot for aligning ticks
ax2.set_xlabel("Examples seen")
fig.tight_layout() # Adjust layout to make room
plt.savefig(f"{label}-plot.pdf")
plt.show()
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
examples_seen_tensor = torch.linspace(0, examples_seen, len(train_losses))
plot_values(epochs_tensor, examples_seen_tensor, train_losses, val_losses)
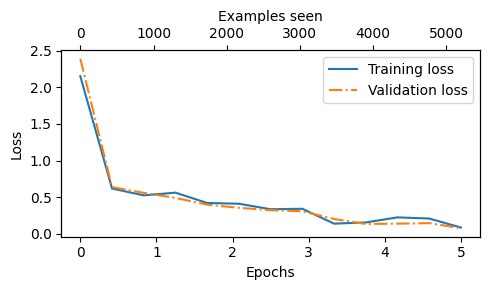
epochs_tensor = torch.linspace(0, num_epochs, len(train_accs))
examples_seen_tensor = torch.linspace(0, examples_seen, len(train_accs))
plot_values(
epochs_tensor, examples_seen_tensor, train_accs, val_accs,
label="accuracy"
)
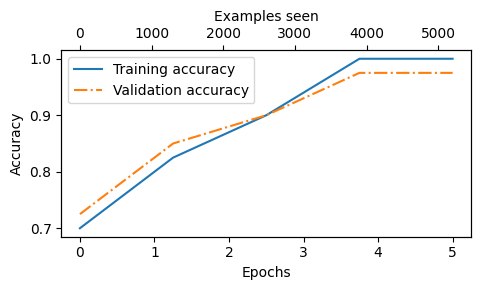
效果看起来还是比较好的。
我们打印一下三个数据集的数据:
train_accuracy = calc_accuracy_loader(train_loader, model, device)
val_accuracy = calc_accuracy_loader(val_loader, model, device)
test_accuracy = calc_accuracy_loader(test_loader, model, device)
print(f"Training accuracy: {train_accuracy*100:.2f}%")
print(f"Validation accuracy: {val_accuracy*100:.2f}%")
print(f"Test accuracy: {test_accuracy*100:.2f}%")
1.8 Using the LLM as a spam classifier
写一个辅助函数,用于对文本进行垃圾分类:
def classify_review(text, model, tokenizer, device, max_length=None, pad_token_id=50256):
model.eval()
input_ids = tokenizer.encode(text)
supported_context_length = model.pos_emb.weight.shape[1]
input_ids = input_ids[:min(
max_length, supported_context_length
)]
input_ids += [pad_token_id] * (max_length - len(input_ids))
input_tensor = torch.tensor(
input_ids, device=device
).unsqueeze(0)
with torch.no_grad():
logits = model(input_tensor)[:, -1, :]
predicted_label = torch.argmax(logits, dim=-1).item()
return "spam" if predicted_label == 1 else "not spam"
text_1 = (
"You are a winner you have been specially"
" selected to receive $1000 cash or a $2000 award."
)
print(classify_review(
text_1, model, tokenizer, device, max_length=train_dataset.max_length
))
spam
text_2 = (
"Hey, just wanted to check if we're still on"
" for dinner tonight? Let me know!"
)
print(classify_review(
text_2, model, tokenizer, device, max_length=train_dataset.max_length
))
not spam
效果还不错。
然后保存权重:
torch.save(model.state_dict(), "review_classifier.pth")
方便以后加载:
model_state_dict = torch.load("review_classifier.pth", map_location=device)
model.load_state_dict(model_state_dict)

说些什么吧!