
零、写在前面
Swin Transformer 基于CNN局部性的先验知识,将更适合序列建模的Transformer 改造成了一种具有 CNN 式多尺度层次结构、同时又保留自注意力建模能力的通用视觉 backbone。
- 通过 窗口自注意力(Window-based Multi-head Self-Attention, W-MSA)降低高分辨率图像上的计算复杂度。
- 再通过 移位窗口(Shifted Window Multi-head Self-Attention, SW-MSA)实现跨窗口信息交互。
一、标题
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
使用移位窗口的层次化视觉 Transformer
作者团队来自微软亚洲研究院。
二、摘要
论文首先指出:Transformer 在自然语言处理(Natural Language Processing,NLP)中已经非常成功,但将其直接迁移到视觉任务时会遇到两类关键困难:
-
视觉实体尺度变化更大
- 语言中的基本处理单元通常是 word token 或 subword token,尺度相对稳定。
- 图像中的视觉实体可以非常小,也可以非常大;检测、分割等任务尤其依赖多尺度建模。
-
图像分辨率远高于文本序列长度对应的处理规模
- 视觉任务常常需要高分辨率输入,尤其是语义分割这类像素级 dense prediction 任务。
- 标准全局自注意力需要计算所有 token 两两之间的关系,复杂度随 token 数平方增长,直接用于高分辨率图像代价很高。
为解决这些问题,论文提出 Swin Transformer:
- 构建 hierarchical Transformer,逐层合并 patch,形成多尺度 feature maps;
- 在 non-overlapping local windows 内计算 self-attention,减少计算量;
- 使用 shifted windowing scheme 让相邻窗口之间也能交换信息;
- 因为每个窗口大小固定,所以模型对图像大小具有近似线性计算复杂度。
在摘要中给出了 Swin Transformer 在三类任务上的代表性结果:
| 任务 | 数据集 | 指标 | 结果 |
|---|---|---|---|
| 图像分类 | ImageNet-1K | Top-1 Accuracy | 87.3 |
| 目标检测 | COCO test-dev | Box AP | 58.7 |
| 实例分割 | COCO test-dev | Mask AP | 51.1 |
| 语义分割 | ADE20K val | mIoU | 53.5 |
论文还强调,相比此前 state-of-the-art 方法,Swin 在 COCO 上提升 +2.7 box AP / +2.6 mask AP,在 ADE20K 上提升 +3.2 mIoU。
之前ViT 已经证明了Transformer 可以做视觉任务,但是ViT 只做了分类,Swin Transformer 试图解决的是:如何让 Transformer 像 CNN 一样成为视觉领域的通用 backbone。
这意味着它必须同时满足三个条件:
- 能处理多尺度视觉实体:所以需要 hierarchical feature maps。
- 能处理高分辨率输入:所以不能使用全局 self-attention。
- 能服务 dense prediction:所以输出特征必须方便接入 FPN、Mask R-CNN、UperNet 等视觉框架。
Swin 的方法设计基本都是围绕这三点展开的。
三、引言
3.1 ViT 的启发与不足
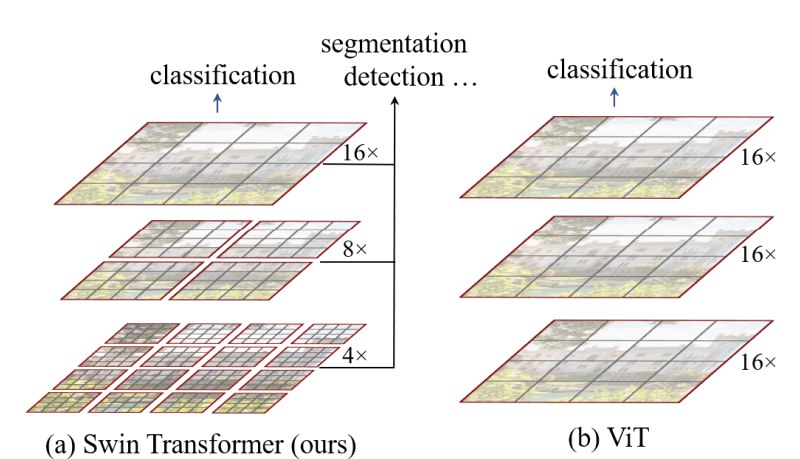
Vision Transformer(ViT)证明了一个重要事实:只要把图像切成 patch,并把 patch 当作 token 输入 Transformer,纯 Transformer 也可以完成图像分类。
但论文指出,ViT 作为通用视觉 backbone 仍然存在明显不足:
-
特征分辨率单一
- ViT 通常在固定尺度的 patch token 上处理图像。
- 它不像 CNN 那样天然产生从高分辨率到低分辨率的多级特征。
- 这对检测、分割等任务不友好,因为这些任务依赖多尺度 feature maps。
-
全局 self-attention 复杂度过高
- ViT 中每个 token 都和所有 token 计算 attention。
- 当输入图像分辨率升高时,token 数增加,全局 attention 的计算量呈平方增长。
- 对语义分割等像素级任务,这种成本很难接受。
-
视觉实体尺度变化更大
- 文本 token 的粒度相对稳定。
- 图像中的物体可能从很小的局部区域到占据整张图,尺度变化更强。
- 因此视觉 backbone 更需要层次化、多尺度表征。
3.2 核心设计
为了解决上述问题,Swin Transformer 引入两类设计:
1. 用 patch merging 构建层次化特征
Swin 从小 patch 开始,随着网络加深逐渐合并相邻 patch,使空间分辨率降低、通道维度增加。这样得到的特征层级类似 CNN 的多个 stage:
- 浅层:高分辨率,适合保留局部细节;
- 深层:低分辨率,高语义抽象;
- 多级输出:特征图适合接入 FPN、U-Net、Mask R-CNN、UperNet 等框架。
这解决了 ViT 输出单一低分辨率 feature map 的问题。
2. 用窗口 attention 控制复杂度
Swin 不在整张图上做全局 self-attention,而是把 feature map 划分成固定大小的非重叠窗口,并在每个窗口内部独立计算 attention。
这样做的关键好处是:
- 每个窗口的 token 数固定;
- 图像越大,只是窗口数量变多;
- 因此总复杂度随图像大小近似线性增长。
3. 用 shifted window 实现跨窗口连接
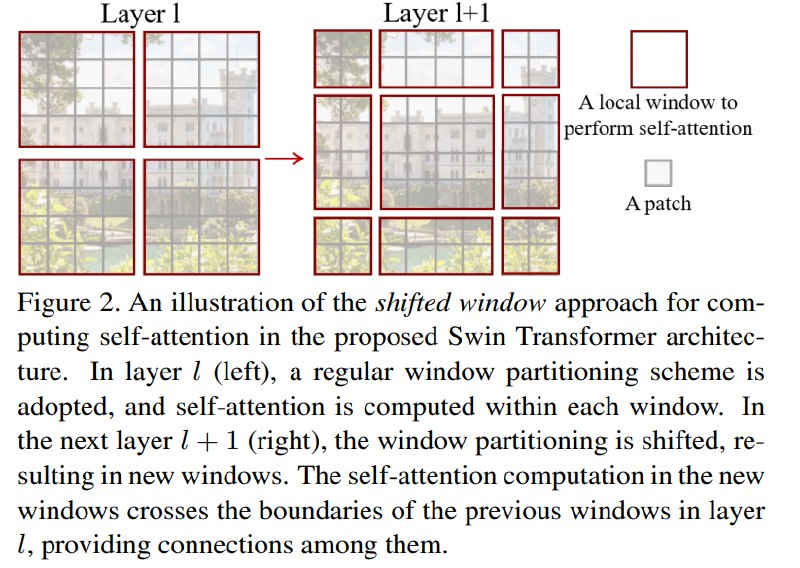
单纯的窗口 attention 有一个明显问题:不同窗口之间没有信息交互。Swin 的关键设计是让相邻 block 采用不同的窗口划分:
- 一个 block 使用 regular window partition;
- 下一个 block 使用 shifted window partition;
- shifted 后的新窗口会跨过上一层窗口边界;
- 因此原本位于不同窗口的 token 可以在下一层被放到同一窗口中交互。
这就是论文标题中 Shifted Windows 的含义。
Q:为什么非得做shifted window?
A:
因为Transformer 做全局注意力的初衷就是为了更好地理解上下文,通过shifted window 可以让不同窗口的信息更好地融合。
四、结论
结论写的很简洁,主要强调三点:
- Swin Transformer 是一种新的 vision Transformer,能够产生层次化特征表示。
- Swin 的计算复杂度相对于输入图像大小是线性的,因此适合高分辨率视觉任务。
- Swin 在 COCO 目标检测和 ADE20K 语义分割上达到当时 state-of-the-art 性能,显著超过此前最佳方法。
作者还表示,希望 Swin Transformer 在多种视觉任务上的强表现能够推动视觉和语言信号的统一建模。
关于 shifted window 的结论:
论文最后特别指出:shifted window based self-attention 是 Swin Transformer 的关键组成部分。它在视觉问题上被证明既有效又高效。作者还提出未来希望探索 shifted window 在 NLP 中的应用。
五、Method
5.1 层次化 Vision Transformer
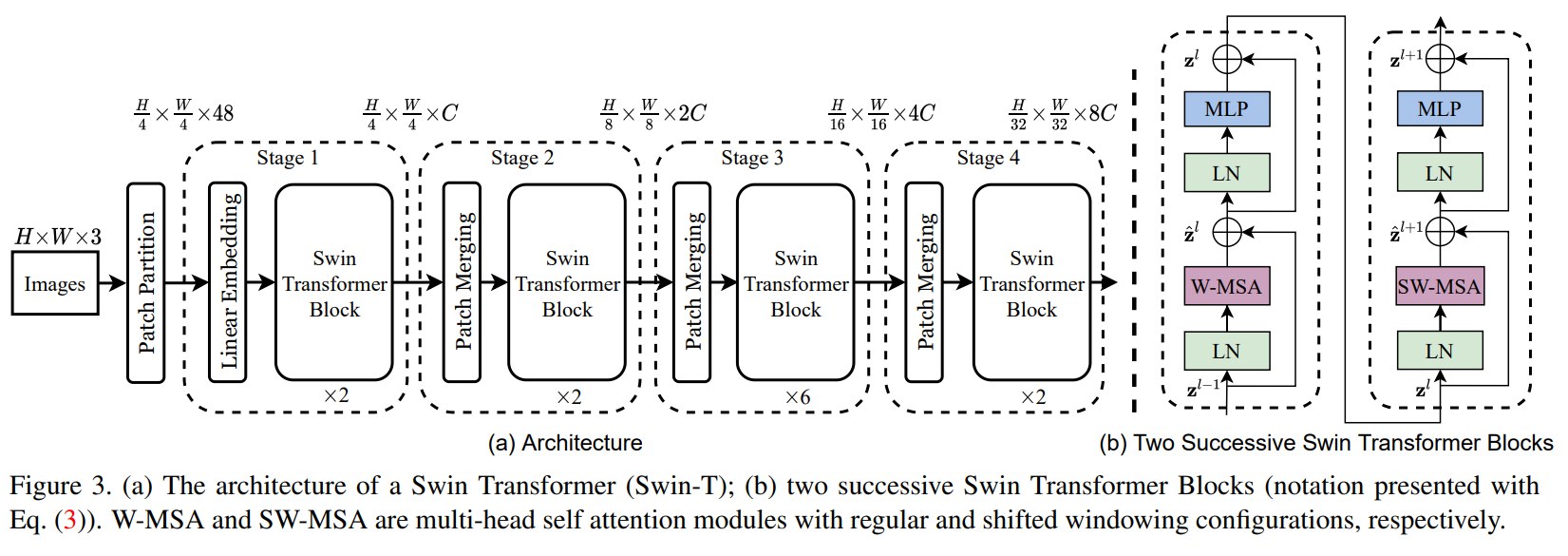
Swin Transformer 的整体架构:既保留 Transformer block 的基本形式,又引入 CNN 式的多 stage 层次化结构。
1、 Patch Partition:把图像切成 token
给定输入 RGB 图像,Swin 首先使用 patch splitting module 将图像划分成不重叠 patch。论文实现中使用的 patch size 是:
4 x 4
每个 patch 包含 4 x 4 个像素,每个像素有 3 个 RGB 通道,因此一个 patch 的原始特征维度为:
4 x 4 x 3 = 48
以一张224 * 224 * 3 的图片为例,做Patch Partition 之后维度会变成 56 * 56 * 48。
2、Linear Embedding:把原始像素特征投影到 C 维
patch 的原始 RGB 拼接特征维度是 48,但 Transformer block 需要在统一的 hidden dimension 上处理 token。因此,Swin 使用一个 linear embedding layer 将每个 patch token 投影到维度 C。
这里的 C 是 Stage 1 的 hidden channel 数,不同模型变体取值不同:
- Swin-T / Swin-S:
C = 96 - Swin-B:
C = 128 - Swin-L:
C = 192
3、Stage 1:保持 H/4 x W/4 分辨率
经过 4 x 4 patch partition 后,如果原图大小是 H x W,那么 token map 的空间分辨率变为:
H/4 x W/4
Stage 1 包括 linear embedding 和若干 Swin Transformer blocks。在 Stage 1 内部,token 数量保持不变。
4、Stage 2~4:通过 Patch Merging 逐层降采样
为了形成层次化表示,Swin 在 stage 之间插入 patch merging layer。每经过一次 patch merging:
- 空间分辨率下降 2 倍;
- token 数量减少到原来的 1/4;
- 通道维度增加。
四个 stage 的输出分辨率为:
| Stage | 输出分辨率 | 相对输入图像的下采样率 | 作用 |
|---|---|---|---|
| Stage 1 | H/4 x W/4 |
4x | 保留较高空间细节 |
| Stage 2 | H/8 x W/8 |
8x | 初步语义抽象 |
| Stage 3 | H/16 x W/16 |
16x | 中高层语义表征 |
| Stage 4 | H/32 x W/32 |
32x | 高层语义表征 |
这与 ResNet、VGG 等 CNN backbone 的 feature hierarchy 非常相似。因此,Swin 的输出可以方便地接入检测和分割框架。
5.2 Patch Merging
Patch merging 是 Swin 形成 hierarchical representation 的核心操作。
具体做法:
在某个 stage 的末尾,假设当前 token 的通道维度是 C。Patch merging 会:
- 取相邻
2 x 2个 token; - 将它们的特征在 channel 维度上拼接;
- 得到一个
4C维向量; - 使用 linear layer 将
4C维特征映射到2C维; - 得到下一 stage 的 token。
也就是说,patch merging 的形式可以理解为:
2 x 2 neighboring tokens -> concatenate -> 4C channels -> linear projection -> 2C channels
它与 CNN 下采样的关系
Patch merging 在功能上类似 CNN 中的 pooling 或 stride convolution:
- 都会降低空间分辨率;
- 都会扩大后续 token / feature 的感受范围;
- 都会让网络逐渐从局部细节走向高级语义。
但 patch merging 不是卷积,也不是简单丢弃 token。它保留了 2 x 2 邻域内的信息,并通过线性变换整合这些信息。
Q:为什么 patch merging 很重要?
A:
如果没有 patch merging,Swin 就会更接近 ViT:全程保持同一尺度的 token 表示。这会带来两个问题:
- 不方便输出多尺度 feature maps;
- 对检测、分割这类 dense prediction 任务不友好。
因此,patch merging 是 Swin 从“分类 Transformer”走向“通用视觉 backbone”的关键部件。
5.3 Swin Transformer Block
Swin Transformer block 基本保留标准 Transformer block 的结构,但替换了 self-attention 的计算方式。
一个 Swin Transformer block 通常包含:
- LayerNorm(LN);
- Window-based MSA 或 Shifted Window-based MSA;
- Residual connection;
- LayerNorm;
- 两层 MLP,中间使用 GELU 非线性;
- Residual connection。
论文用两个连续 block 表示 W-MSA 与 SW-MSA 的交替:
z_hat^l = W-MSA(LN(z^{l-1})) + z^{l-1}
z^l = MLP(LN(z_hat^l)) + z_hat^l
z_hat^{l+1} = SW-MSA(LN(z^l)) + z^l
z^{l+1} = MLP(LN(z_hat^{l+1})) + z_hat^{l+1}
这里:
- W-MSA 表示 regular window partition 下的窗口自注意力;
- SW-MSA 表示 shifted window partition 下的窗口自注意力;
z_hat是 attention 模块后的输出;z是 MLP 模块后的输出。
5.4 W-MSA:窗口内多头自注意力
Swin 使用 Window-based Multi-head Self-Attention(W-MSA):
- 将 feature map 划分为多个不重叠窗口;
- 每个窗口大小为
M x M个patch; - 每个窗口内部独立计算 self-attention;
- 不同窗口之间在该层不直接计算 attention。
论文默认窗口大小为:
M = 7
也就是说,一个窗口内有 7 x 7 = 49 个 patch token。
复杂度对比
论文给出标准 MSA 和 W-MSA 的复杂度:
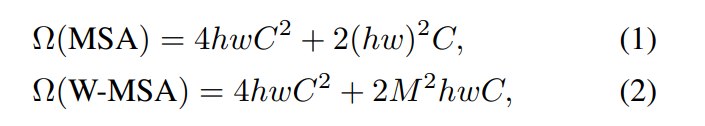
计算过程推导:
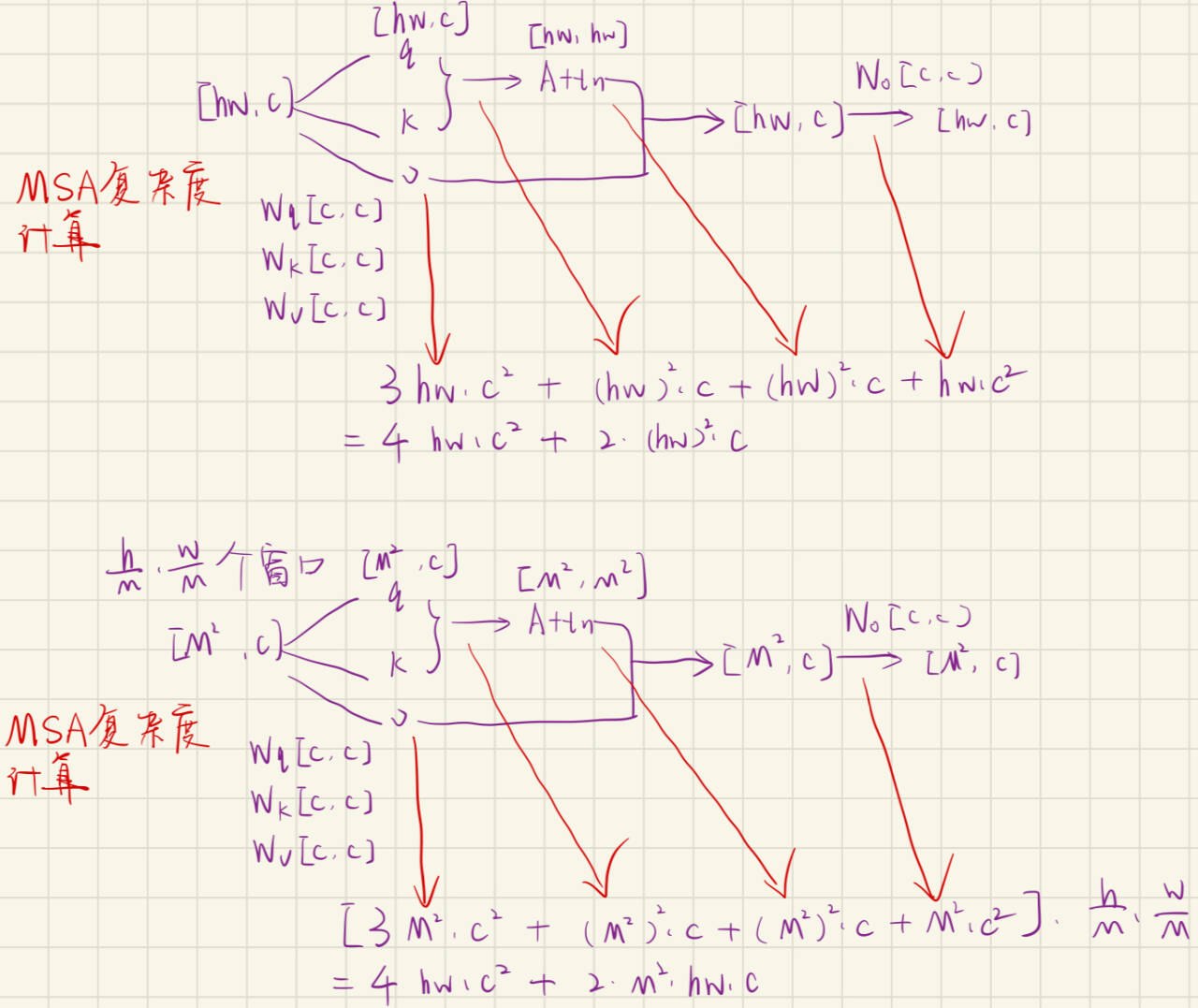
其中:
-
h, w:feature map 的高和宽,以 patch token 为单位; -
C:通道维度; -
M:窗口边长; -
hw:token 总数。 -
标准 MSA 的 attention 项是
2(hw)^2C,对 token 数平方增长; -
W-MSA 的 attention 项是
2M^2hwC,当M固定时,对hw线性增长。
因此,Swin 并不是让 attention 本身消失,而是把全局 attention 分解成多个固定大小窗口内的局部 attention,从而避免高分辨率下的平方复杂度。
5.5 SW-MSA:移位窗口自注意力
基本思想
Swin 在连续两个 Transformer block 中交替使用两种窗口划分:
- Regular window partition:从左上角开始,将 feature map 均匀划分为不重叠窗口。
- Shifted window partition:下一个 block 的窗口相对于上一个 block 平移一定距离。
平移量为:
(floor(M/2), floor(M/2))
如果窗口大小 M = 7,则平移量约为窗口边长的一半。
这样一来,上一层中位于不同窗口的 token,在下一层可能被划入同一个 shifted window,从而发生 self-attention 交互。
它为什么能建立跨窗口连接
可以把 shifted window 理解为“改变窗口边界”:
- 在 regular window 中,边界固定,窗口 A 和窗口 B 不交互;
- 到 shifted window 中,窗口整体平移,新的窗口会覆盖原来多个窗口的一部分;
- 因此,原来属于不同窗口的 token 在新窗口中被放到一起;
- 它们就可以通过 self-attention 交换信息。
这个过程不需要让每个 token 与全图所有 token 交互,因此仍然比全局 attention 高效。
cyclic shift 与 attention mask
做了shift后,窗口数目会变多,且出现了一些不够M*M的窗口,怎么做注意力计算呢?
一个想法是,我们做padding,把所有窗口的大小都补全到 M*M,但是这样的话计算复杂度就上升了。论文举例说明,在窗口数较少时,窗口数量可能从 2 x 2 变成 3 x 3,计算量变为 2.25 倍。
为避免这个问题,Swin 使用 cyclic shift:
- 先对 feature map 做循环平移,重组成h/M * w/M 个窗口;
- 再按 regular window 的方式切分窗口;
- 这样 batch 中窗口数量保持不变;
- 由于 cyclic shift 后某些窗口包含了原图中并不相邻的 sub-window,因此使用 attention mask 限制不应互相注意的 token。
代码仓库的一个issue给了很好的可视化https://github.com/microsoft/Swin-Transformer/issues/52
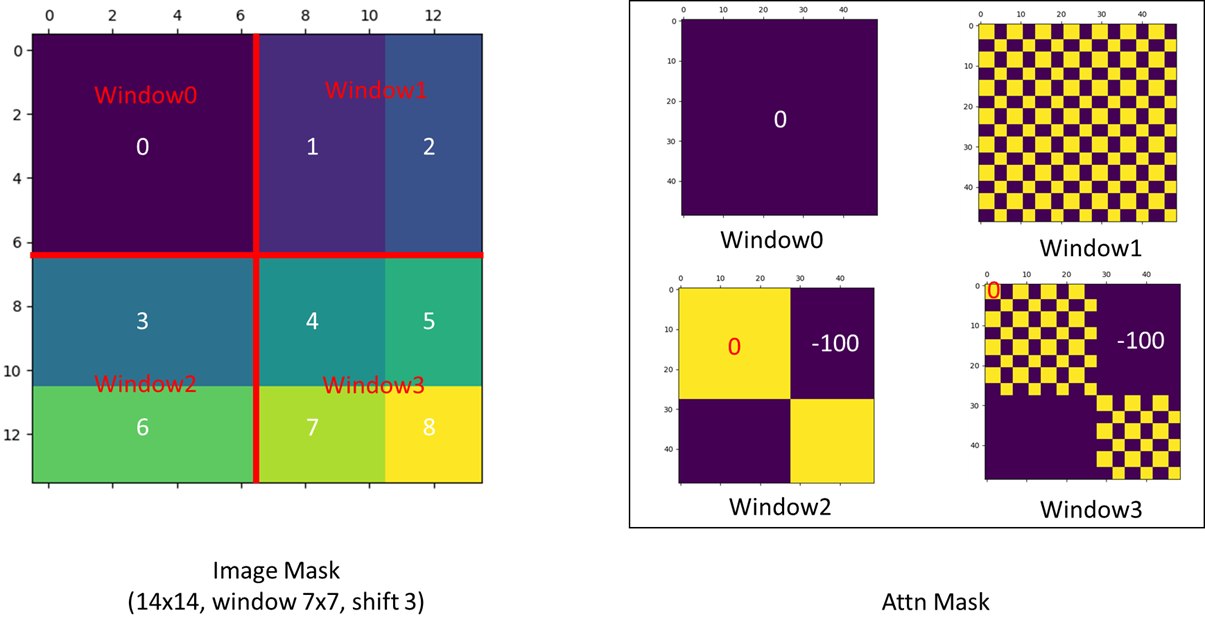
如上图所示,虽然我们通过循环移位避免出现多个窗口,但是属于不同window的窗口因为移位而处于同一窗口之中,我们应该通过掩码来避免它们发生注意力计算。
为什么?因为对于图像而言,假如说图片上方是一个天空,然后因为移位,天空和地面处于一个窗口中,且天空位于地面下方,我们应该避免引入这种误导的语义信息,所以要加掩码。
上图给出了移位之后的掩码矩阵设置,这使得我们仍然可以一次前向过程高效完成注意力计算。
后面消融实验部分还将SW-MSA和Sliding Window MSA 进行对比,结果是 SW-MSA 效率远高于Sliding Window MSA ,并且精度略高于或者持平。
这其实是底层硬件的访存机制、并行计算友好度以及内存复用率导致的。
SW-MSA 通过循环移位和masking,让即使是边缘的窗口,依然可以拼成规则的矩阵,继续调用 GPU 最擅长的密集矩阵乘法。
可以去了解下Sliding Window MSA 的机制,最终要做的是稀疏矩阵乘法,这个硬件开销就要大得多,甚至还要手写专门CUDA算子,但是效率仍然不理想。
5.6 Relative Position Bias:相对位置偏置
和ViT注入位置信息的方式不同,ViT 常用 absolute position embedding,但 Swin 选择在窗口 attention 中加入 relative position bias(相对位置偏置)。
论文中的 attention 计算为:
$$ Attention(Q, K, V) = SoftMax(QK^T / \sqrt{d} + B)V $$其中:
Q, K, V ∈ R^{M^2 x d}:窗口内 token 的 query、key、value;M^2:一个窗口内的 token 数;d:query/key 的维度;B ∈ R^{M^2 x M^2}:relative position bias。
这个 B 会加到 attention logits 上,用于表达窗口内两个 token 的相对空间关系。
如果窗口大小是 M x M,两个 token 在横向或纵向上的相对位移范围是:[-M+1, M-1]
因此,论文不直接学习完整的 M^2 x M^2 bias matrix,而是学习一个更小的表:
然后根据 token 对之间的相对位置从 $\hat B$ 中取值,组成 B。
Q:为什么相对位置更适合 Swin
A:
Swin 的 attention 是在局部窗口内部计算的。窗口内 token 的相对空间关系非常重要,例如:
- 左右相邻;
- 上下相邻;
- 对角线相邻;
- 距离较远但仍在同一窗口内。
Relative position bias 直接建模这些相对关系,比固定输入尺度上的 absolute position embedding 更适合窗口内部注意力。
论文消融实验显示:relative position bias 明显优于无位置编码或 absolute position embedding。额外再加入 absolute position embedding 反而略微降低性能,因此默认实现中不采用 absolute position embedding。
5.7 模型变体
论文构建了四个主要版本:Swin-T、Swin-S、Swin-B、Swin-L。
| 模型 | Stage 1 通道数 C | 每个 stage 的 block 数 | 相对规模说明 |
|---|---|---|---|
| Swin-T | 96 | {2, 2, 6, 2} |
Tiny,约为 Swin-B 的 0.25x 规模/复杂度 |
| Swin-S | 96 | {2, 2, 18, 2} |
Small,约为 Swin-B 的 0.5x 规模/复杂度 |
| Swin-B | 128 | {2, 2, 18, 2} |
Base,与 ViT-B / DeiT-B 规模相近 |
| Swin-L | 192 | {2, 2, 18, 2} |
Large,约为 Swin-B 的 2x 规模/复杂度 |
其他默认设置包括:
- 窗口大小:
M = 7; - 每个 attention head 的 query dimension:
d = 32; - MLP expansion ratio:
α = 4。
根据论文架构图和 appendix 规格表,Swin-T 的典型配置可以概括为:
| Stage | 下采样率 | 输出尺寸示例(输入 224x224) | 通道维度 | Head 数 | Block 数 |
|---|---|---|---|---|---|
| Stage 1 | 4x | 56 x 56 | 96 | 3 | 2 |
| Stage 2 | 8x | 28 x 28 | 192 | 6 | 2 |
| Stage 3 | 16x | 14 x 14 | 384 | 12 | 6 |
| Stage 4 | 32x | 7 x 7 | 768 | 24 | 2 |
这张表非常重要,因为它说明 Swin 并不是“把 ViT 换成局部 attention”这么简单,而是完整地重构了视觉 Transformer 的 backbone 形态。
六、实验
6.1 实验总体设置
论文在三类视觉任务上验证 Swin Transformer:
- ImageNet-1K 图像分类;
- COCO 目标检测与实例分割;
- ADE20K 语义分割。
这种实验设计对应论文的核心主张:Swin 不只是分类模型,而是可以作为 通用视觉 backbone。
6.2 ImageNet-1K 图像分类
1、数据集与指标
ImageNet-1K 包含:
- 1.28M training images;
- 50K validation images;
- 1000 classes。
论文报告 single-crop Top-1 accuracy。
2、训练设置
论文考虑两种训练设置:
-
Regular ImageNet-1K training
- 优化器:AdamW;
- 训练 300 epochs;
- cosine decay learning rate scheduler;
- 20 epochs linear warm-up;
- batch size 1024;
- initial learning rate 0.001;
- weight decay 0.05。
-
ImageNet-22K pre-training + ImageNet-1K fine-tuning
- 在 ImageNet-22K 上预训练;
- ImageNet-22K 包含 14.2M images 和 22K classes;
- 预训练 90 epochs;
- fine-tuning 30 epochs。
3、Regular ImageNet-1K 结果
| 方法 | 输入尺寸 | 参数量 | FLOPs | Throughput | Top-1 |
|---|---|---|---|---|---|
| DeiT-S | 224² | 22M | 4.6G | 940.4 | 79.8 |
| Swin-T | 224² | 29M | 4.5G | 755.2 | 81.3 |
| Swin-S | 224² | 50M | 8.7G | 436.9 | 83.0 |
| DeiT-B | 224² | 86M | 17.5G | 292.3 | 81.8 |
| Swin-B | 224² | 88M | 15.4G | 278.1 | 83.5 |
| DeiT-B | 384² | 86M | 55.4G | 85.9 | 83.1 |
| Swin-B | 384² | 88M | 47.0G | 84.7 | 84.5 |
关键观察:
- Swin-T 在相近 FLOPs 下比 DeiT-S 高 +1.5% Top-1。
- Swin-B 在 224² 和 384² 输入下分别比 DeiT-B 高 +1.7% 和 +1.4%。
- 相比 RegNet、EfficientNet 等 CNN,Swin 也表现出有竞争力的 speed-accuracy trade-off。
4、ImageNet-22K 预训练结果
| 方法 | 输入尺寸 | 参数量 | FLOPs | Throughput | Top-1 |
|---|---|---|---|---|---|
| ViT-B/16 | 384² | 86M | 55.4G | 85.9 | 84.0 |
| ViT-L/16 | 384² | 307M | 190.7G | 27.3 | 85.2 |
| Swin-B | 224² | 88M | 15.4G | 278.1 | 85.2 |
| Swin-B | 384² | 88M | 47.0G | 84.7 | 86.4 |
| Swin-L | 384² | 197M | 103.9G | 42.1 | 87.3 |
论文指出,ImageNet-22K 预训练为 Swin-B 带来约 1.8% 到 1.9% 的提升。Swin-L 达到 87.3 Top-1,是摘要中报告的分类结果。
5、分类实验说明了什么
分类实验说明 Swin 的局部窗口 attention 和层次化结构并没有牺牲图像分类能力。更重要的是,Swin 的分类性能已经足够强,使其可以作为下游 dense prediction 的强 backbone 初始化。
不过,从论文目标看,ImageNet 分类不是终点,而是证明 Swin 具备 backbone 基础能力的第一步。
6.3 COCO 目标检测与实例分割
1、数据集与任务
COCO 2017 包含:
- 118K training images;
- 5K validation images;
- 20K test-dev images。
论文评估两个任务:
- Object detection:指标为 box AP;
- Instance segmentation:指标为 mask AP。
2、检测框架
论文在多个检测框架中替换 backbone 进行对比:
- Cascade Mask R-CNN;
- ATSS;
- RepPoints v2;
- Sparse R-CNN;
- system-level comparison 中使用改进版 HTC++。
重要的是,论文强调比较时主要是替换 backbone,其他设置保持一致。这使结果更能说明 backbone 本身的贡献。
3、Swin-T 与 ResNet-50 的多框架对比
| 框架 | Backbone | Box AP | 参数量 | FLOPs | FPS |
|---|---|---|---|---|---|
| Cascade Mask R-CNN | R-50 | 46.3 | 82M | 739G | 18.0 |
| Cascade Mask R-CNN | Swin-T | 50.5 | 86M | 745G | 15.3 |
| ATSS | R-50 | 43.5 | 32M | 205G | 28.3 |
| ATSS | Swin-T | 47.2 | 36M | 215G | 22.3 |
| RepPointsV2 | R-50 | 46.5 | 42M | 274G | 13.6 |
| RepPointsV2 | Swin-T | 50.0 | 45M | 283G | 12.0 |
| Sparse R-CNN | R-50 | 44.5 | 106M | 166G | 21.0 |
| Sparse R-CNN | Swin-T | 47.9 | 110M | 172G | 18.4 |
论文总结:Swin-T 相比 ResNet-50 在四个检测框架中带来 +3.4 到 +4.2 box AP 的一致提升。
这说明 Swin 的收益并不依赖某一个特定检测头,而是来自 backbone 表征能力。
4、不同 backbone 的 Cascade Mask R-CNN 对比
| Backbone | Box AP | Mask AP | 参数量 | FLOPs | FPS |
|---|---|---|---|---|---|
| DeiT-S | 48.0 | 41.4 | 80M | 889G | 10.4 |
| R50 | 46.3 | 40.1 | 82M | 739G | 18.0 |
| Swin-T | 50.5 | 43.7 | 86M | 745G | 15.3 |
| X101-32 | 48.1 | 41.6 | 101M | 819G | 12.8 |
| Swin-S | 51.8 | 44.7 | 107M | 838G | 12.0 |
| X101-64 | 48.3 | 41.7 | 140M | 972G | 10.4 |
| Swin-B | 51.9 | 45.0 | 145M | 982G | 11.6 |
关键观察:
- Swin-T 比 DeiT-S 高 +2.5 box AP / +2.3 mask AP,且 FPS 更高。
- Swin-B 比相近规模的 ResNeXt101-64x4d 高 +3.6 box AP / +3.3 mask AP。
- DeiT 由于只产生单一分辨率 feature map,需要额外 deconvolution layers 构造层次特征;Swin 则天然输出多尺度 feature maps。
5、COCO test-dev 上的 system-level 结果
| 方法 | Test-dev Box AP | Test-dev Mask AP |
|---|---|---|
| Copy-paste | 56.0 | 47.4 |
| DetectoRS | 55.7 | 48.5 |
| Swin-L HTC++ | 57.7 | 50.2 |
| Swin-L HTC++ multi-scale testing | 58.7 | 51.1 |
论文报告最佳 Swin-L HTC++ multi-scale testing 达到:
58.7 box AP / 51.1 mask AP
相比此前最佳结果:
- Box AP 提升 +2.7;
- Mask AP 提升 +2.6。
6、检测实验说明了什么
COCO 实验是 Swin 论文最关键的证据之一。它说明:
- 层次化 feature maps 对检测非常重要。
- 检测任务需要同时识别小物体和大物体。
- Swin 的多 stage 输出天然适合 FPN 类结构。
- 线性复杂度对高分辨率输入很重要。
- 检测输入通常比分类输入更大。
- DeiT/ViT 的全局 attention 会因高分辨率导致速度下降。
- Swin 的优势不只是分类精度高。
- 如果只是 ImageNet 高,未必能迁移到检测。
- COCO 结果说明 Swin 的结构更适合作为视觉 backbone。
6.4 ADE20K 语义分割
1、数据集与设置
ADE20K 是常用语义分割数据集,覆盖 150 个语义类别。论文给出的划分为:
- 20K training images;
- 2K validation images;
- 3K testing images。
论文使用 UperNet 作为基础分割框架,并在 mmseg 中实现。
2、主要结果
| 方法 | Backbone | Val mIoU | Test score | 参数量 | FLOPs | FPS |
|---|---|---|---|---|---|---|
| UperNet | ResNet-101 | 44.9 | - | 86M | 1029G | 20.1 |
| SETR | T-Large | 50.3 | 61.7 | 308M | - | - |
| UperNet | DeiT-S | 44.0 | - | 52M | 1099G | 16.2 |
| UperNet | Swin-T | 46.1 | - | 60M | 945G | 18.5 |
| UperNet | Swin-S | 49.3 | - | 81M | 1038G | 15.2 |
| UperNet | Swin-B | 51.6 | - | 121M | 1841G | 8.7 |
| UperNet | Swin-L | 53.5 | 62.8 | 234M | 3230G | 6.2 |
关键结果:
- Swin-S 比 DeiT-S 高 +5.3 mIoU;
- Swin-S 比 ResNet-101 高 +4.4 mIoU;
- Swin-S 比 ResNeSt-101 高 +2.4 mIoU;
- Swin-L with ImageNet-22K pre-training 达到 53.5 mIoU,比 SETR 的 50.3 高 +3.2 mIoU。
3、分割实验说明了什么
语义分割是像素级 dense prediction 任务,对 backbone 的要求比分类更复杂:
- 需要高分辨率空间细节;
- 需要全局语义上下文;
- 需要多尺度特征融合。
Swin 在 ADE20K 上的结果说明,其层次化结构和局部窗口 attention 不仅没有限制 dense prediction,反而比 DeiT 这类单尺度 Transformer 更适合分割任务。
6.5 消融实验
消融实验用于回答一个关键问题:Swin 的性能到底来自哪里?是模型更大,还是核心设计真的有效?
论文主要消融了:
- shifted windows;
- relative position bias;
- 不同 self-attention 实现方式。
6.5.1 Shifted windows 的作用
| 设置 | ImageNet Top-1 | COCO Box AP | COCO Mask AP | ADE20K mIoU |
|---|---|---|---|---|
| w/o shifting | 80.2 | 47.7 | 41.5 | 43.3 |
| shifted windows | 81.3 | 50.5 | 43.7 | 46.1 |
使用 shifted windows 带来的提升为:
- ImageNet:+1.1 Top-1;
- COCO:+2.8 box AP / +2.2 mask AP;
- ADE20K:+2.8 mIoU。
这个结果非常关键,因为它直接证明:跨窗口连接不是可有可无的细节,而是 Swin 建模能力的重要来源。
如果没有 shifted windows,模型虽然仍然有窗口 attention,但窗口之间的信息交流不足,检测和分割性能明显下降。
6.5.2 Relative position bias 的作用
| 位置编码方式 | ImageNet Top-1 | COCO Box AP | COCO Mask AP | ADE20K mIoU |
|---|---|---|---|---|
| no pos. | 80.1 | 49.2 | 42.6 | 43.8 |
| abs. pos. | 80.5 | 49.0 | 42.4 | 43.2 |
| abs. + rel. pos. | 81.3 | 50.2 | 43.4 | 44.0 |
| rel. pos. w/o app. | 79.3 | 48.2 | 41.9 | 44.1 |
| rel. pos. | 81.3 | 50.5 | 43.7 | 46.1 |
论文结论:relative position bias 对所有三类任务都有帮助。
特别值得注意的是:absolute position embedding 虽然让 ImageNet Top-1 从 80.1 提升到 80.5,但在 COCO 和 ADE20K 上反而下降。这说明,对于通用视觉 backbone,尤其是 dense prediction,过强依赖绝对位置可能不如相对位置关系稳健。
论文进一步指出,某种鼓励平移不变性的 inductive bias 对通用视觉建模仍然重要,尤其在检测和分割任务中。
6.5.3 不同 self-attention 方法的真实速度
论文比较了 sliding window、Performer、window without shifting、shifted window padding、shifted window cyclic 等方法在 V100 GPU 上的速度。
| 方法 | Stage 1 MSA ms | Stage 2 MSA ms | Stage 3 MSA ms | Stage 4 MSA ms | Swin-T FPS |
|---|---|---|---|---|---|
| sliding window naive | 122.5 | 38.3 | 12.1 | 7.6 | 183 |
| sliding window kernel | 7.6 | 4.7 | 2.7 | 1.8 | 488 |
| Performer | 4.8 | 2.8 | 1.8 | 1.5 | 638 |
| window w/o shifting | 2.8 | 1.7 | 1.2 | 0.9 | 770 |
| shifted window padding | 3.3 | 2.3 | 1.9 | 2.2 | 670 |
| shifted window cyclic | 3.0 | 1.9 | 1.3 | 1.0 | 755 |
关键结论:
- cyclic implementation 比 naive padding 更高效;
- shifted window cyclic 的速度接近不 shift 的 window attention;
- 相比 sliding window,shifted window 在真实硬件延迟上明显更优。
6.5.4 不同 self-attention 方法的精度
| 方法 | Backbone | ImageNet Top-1 | COCO Box AP | COCO Mask AP | ADE20K mIoU |
|---|---|---|---|---|---|
| sliding window | Swin-T | 81.4 | 50.2 | 43.5 | 45.8 |
| Performer | Swin-T | 79.0 | - | - | - |
| shifted window | Swin-T | 81.3 | 50.5 | 43.7 | 46.1 |
从精度看,shifted window 与 sliding window 接近甚至略优;从速度看,shifted window 明显更高效。因此,shifted window 是一个兼顾建模能力和硬件效率的设计。
6.6 实验总结
实验部分整体支撑了论文的三个核心判断:
- Swin 能做分类:ImageNet 上优于 DeiT 等 Transformer baseline。
- Swin 更适合 dense prediction:COCO 和 ADE20K 上提升明显,尤其相比 DeiT 的优势更大。
- 核心设计有效:shifted windows、relative position bias、cyclic implementation 均通过消融得到验证。
尤其重要的是,Swin 的优势在检测和分割中比分类更明显。这与论文动机一致:Swin 不是为了单纯刷新分类精度,而是为了让 Transformer 成为视觉通用 backbone。
七、总结
1、核心思想
Swin Transformer 提出了一种层次化、局部窗口化、可跨窗口通信的视觉 Transformer 架构,使 Transformer 能够更自然地承担 CNN 过去在视觉任务中的通用 backbone 角色。
具体来说:
-
层次化架构
- 通过 patch merging 逐层降低分辨率、增加通道数;
- 形成类似 CNN 的多尺度 feature maps;
- 方便接入检测、分割框架。
-
窗口自注意力
- 将 self-attention 限制在固定大小窗口内;
- 避免全局 attention 在高分辨率图像上的平方复杂度;
- 使复杂度对图像大小近似线性。
-
移位窗口机制
- 相邻 block 交替使用 regular windows 和 shifted windows;
- 以较低成本建立跨窗口连接;
- 显著提升分类、检测、分割性能。
-
相对位置偏置
- 在窗口 attention 中注入局部空间关系;
- 比 absolute position embedding 更适合通用视觉 backbone,尤其对 dense prediction 更友好。
2. 为什么 Swin 比 ViT 更适合做视觉 backbone
| 维度 | ViT | Swin Transformer |
|---|---|---|
| 特征层级 | 通常单一分辨率 | 多 stage 层次化特征 |
| Attention 范围 | 全局 self-attention | 窗口内 self-attention + shifted windows |
| 复杂度 | 对图像大小平方增长 | 窗口固定时近似线性增长 |
| Dense prediction 适配 | 需要额外构造多尺度特征 | 天然适配 FPN/UperNet 等框架 |
| 空间归纳偏置 | 较弱 | 局部窗口 + 相对位置偏置提供更强视觉先验 |
因此,Swin 的意义不是否定 ViT,而是补上 ViT 作为通用视觉 backbone 时缺失的结构属性。
3、方法优点
Swin 的方法设计有几个非常清晰的优点:
- 效率高:W-MSA 避免全局 attention 的平方复杂度。
- 结构通用:hierarchical feature maps 可直接替换 CNN backbone。
- 跨窗口建模有效:SW-MSA 用很小额外代价增强窗口间信息交流。
- 实验覆盖全面:分类、检测、分割三类任务共同验证。
- 工程可实现性强:cyclic shift + attention mask 保持较低真实延迟。
4、潜在局限
论文没有系统展开局限性,但从方法本身可以看出一些边界:
-
长程依赖仍需多层传播
- 单层 W-MSA/SW-MSA 仍然是局部 attention。
- 远距离 token 之间的信息交互需要依靠多层堆叠逐步传递。
-
实现复杂度高于普通 ViT
- shifted window、cyclic shift、attention mask、patch merging 都增加了工程复杂度。
- 对框架实现和硬件优化有更高要求。
-
窗口大小是重要超参数
- 窗口太小会限制上下文;
- 窗口太大会增加计算量;
- 论文默认
M=7,但不同任务和分辨率下可能需要调整。
-
不是完全全局建模
- Swin 更强调局部窗口与层次化归纳偏置。
- 对极强全局依赖的任务,可能仍需要额外全局交互机制。
-
NLP 方向只是展望
- 论文结论提到希望探索 shifted window 在 NLP 中的应用,但没有提供实验验证。
5、对后续工作的影响
Swin Transformer 对后续视觉 Transformer 研究产生了重要影响:
- 它证明 Transformer backbone 不必沿用 ViT 的全局 attention + 单尺度结构。
- 它把 CNN 中非常有效的层次化、多尺度思想重新引入 Transformer。
- 它推动了窗口 attention、局部 attention、多尺度 Transformer backbone 的大量后续研究。
- 它也成为多模态模型和视觉基础模型中常用的视觉编码器候选之一。
6、最终理解
如果用一句更深入的话总结 Swin Transformer:
Swin 并不是简单地把 Transformer 用到图像上,而是重新设计了 Transformer 的视觉归纳偏置:用 patch merging 获得多尺度结构,用 window attention 控制复杂度,用 shifted window 恢复跨区域连接,用 relative position bias 注入空间关系。正是这些设计,使它从一个分类模型变成了真正意义上的通用视觉 backbone。

说些什么吧!