
零、写在前面
MAE也是将 NLP 引入CV的工作。之前ViT证明NLP是可以迁移到CV的,并且大规模训练下效果很好,但是没有解决如何有效且高效地做self-supervised training的问题。
MAE 通过“高比例随机 mask + asymmetric encoder-decoder + masked patch pixel reconstruction”,把图像自监督学习变成一个简单、可扩展且对大模型友好的预训练范式。
一、标题

Masked Autoencoders Are Scalable Vision Learners
这个标题也是一个常见的句式模板,XX 是一个好同志(×)
题目本身就点明了本文的技术路线:masked autoencoder,可以在图像领域做大规模的训练。
作者又是何恺明团队,来自Facebook AI Research(不过之前小扎把Facebook改名meta了hh)
二、摘要

MAE将图像自监督学习变成一个简单、可扩展的训练范式,基于两个核心设计:
- 设计一个非对称的encoder-decoder的架构,encoder 仅对不带掩码的patch进行操作,然后由一个轻量的decoder来预测mask掉的部分。
- 将原图以高比例,如75% 进行mask,是一个很重要且有意义的任务。
基于上述设计,在ViT-Huge model上,仅用 ImageNet-1K 的一百万张图片进行自监督训练,就可以做到和以前一样好的效果了。而且在下游任务上进行迁移学习效果也很好。
三、示例图
3.1 MAE architecture
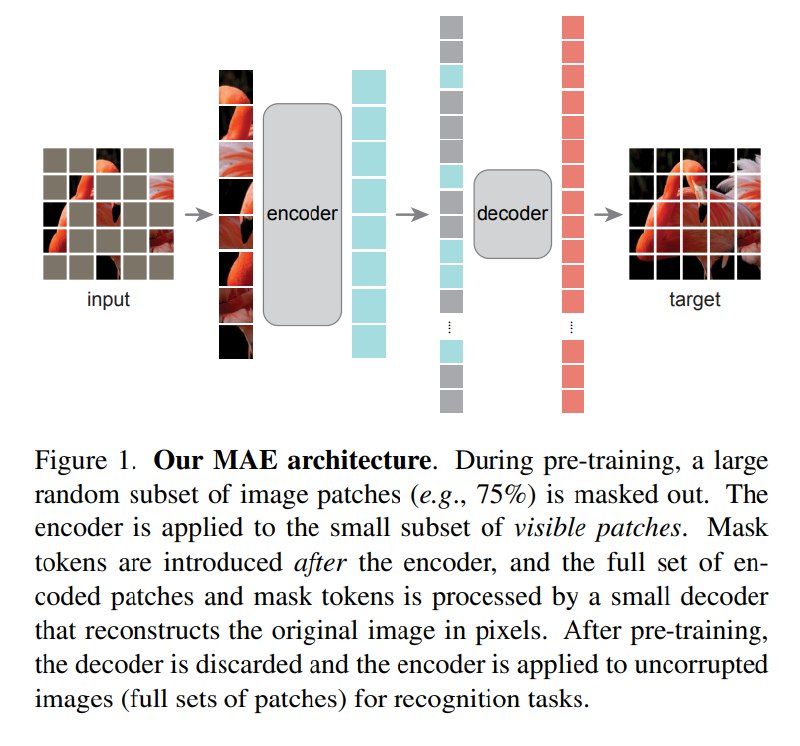
上图展示了MAE的架构:
- 将图片打成patch,然后以一个比较高的比例(e.g.,75%),随机mask掉一些patch
- 没被mask掉的扔进encoder,然后等维度输出,替换放进原来的图片
- 再将mask的部分和encoder输出的部分一起扔进docoder,去重建原来的图片
Transformer的O(n^2)计算量很大,这样做可以降低训练的负担,而且最后的效果也不错。
3.2 Example results


感觉跟魔法一样(,效果很惊人。
3.3 example with different mask ratios

从给的例子来看,当ratio 逐渐高于75%生成的东西就开始抽象了,但是95%的ratio效果看起来也不赖(,有点逆天
四、结论
在NLP领域,自监督学习让模型可以大规模的训练达到很好的效果。但在CV领域,尽管自监督学习一直在发展,但实际中,有监督训练一直是训练范式。
本文提出的MAE,基于自监督训练,通过一个自编码器可以在 ImageNet以及迁移训练上达到和有标号的监督训练一样好的效果。
但Image和word是不一样的,一个词含有的语义信息很多,而一个图像patch可能就没包含物体,作者随机remove掉一些patch(因为很多patch可能就不包含语义信息),发现MAE仍然能够表现得很好。作者的的解释是,可能MAE能够很好的学习到隐藏的语义表达。
当然,因为这是一个生成模型,生成的内容有可能有误导性,所以应用于其它领域时要注意一下(
五、导言
- 导言很长,占了两页,因为他用了很多图片,这在CV领域是一个加分项
- 作者用了问问题、回答问题、引出作者想法的写法,没有提供更多的技术细节,摘要已经很清楚了,为了提高文本流畅度,作者回到把 BERT 引入 CV会有的问题(作者提出了3个),然后引出MAE算法。解释清楚了设计MAE的原因。
5.1 NLP的成功经验
BERT 的 masked language modeling 和 GPT 的 autoregressive language modeling 都遵循一个共同思想:隐藏一部分输入,让模型预测缺失内容。这类任务在 NLP 中天然强,因为文本 token 是人类生成的、语义密度高的离散符号。预测几个被 mask 的词,往往需要句法、语义和上下文理解。
5.2 图像与文本的关键差异
作者强调 vision 和 language 至少有三类差异:
- 架构差异曾经阻碍 mask token 的自然使用
- 过去 vision 以 CNN 为主,卷积在 regular grid 上操作,不像 Transformer 那样自然支持 token 序列、positional embeddings 和 mask tokens。ViT 出现后,图像也可以被处理为 patch tokens,这使 BERT-style masked modeling 在架构上变得可行。
- 图像信息密度低、空间冗余高
- 语言 token 高度语义化,而自然图像是 recorded light。局部区域之间高度相关,一个缺失 patch 可以由邻近纹理外推出来。如果只 mask 少量 patches,模型可能学到的是低层 interpolation,而不是 object-level 或 scene-level understanding。
- 因此 MAE 使用非常高的 mask ratio,例如 75%。这相当于只给模型 25% 的 patch,让任务从“补纹理”变成“根据整体线索推断合理图像内容”。
- decoder 在 vision 中更容易学到低层重建偏好
- 在 BERT 中,decoder 可以很简单(一个MLP效果就不错),因为预测 word 本身就是语义任务。MAE 中 decoder 输出 pixel values,像素是低层信号。如果 decoder 太弱,encoder 可能被迫保留很多低层细节;如果 decoder 合理承担 reconstruction burden,encoder 的 latent representation 可以更抽象、更适合 recognition。
5.3 MAE 的效果
MAE 只是用100万张图片进行自监督训练,就可以训练ViT里面要使用100倍大小以上的数据才能达到的效果。并且在下游任务,如目标检测、实例分割、语义分割上的效果都很好。
六、相关工作
6.1 Masked language modeling
MAE 继承了 NLP self-supervised pre-training 的基本哲学:mask掉一部分输入,预测缺失内容。但它没有机械照搬 BERT 的 15% mask ratio,也没有让 encoder 处理大量 mask tokens,而是针对视觉冗余和 ViT 计算特点重新设计。
6.2 Autoencoding
MAE 可以看作 denoising autoencoder 的现代 Transformer 版本,但与传统 DAE 不同:
- corruption 是 high-ratio patch removal;
- encoder 只处理 uncorrupted visible patches;
- loss 只在 masked patches 上计算;
- decoder 是预训练辅助模块,不用于 downstream。
6.3 ViT
ViT 把图像变成 patch tokens,让 masked image modeling 变得自然。并且ViT也做了 mask image encoding的工作。
MAE 的成功很大程度上依赖 ViT 的 tokenized representation 和 Transformer 对不规则可见 patch 集合的处理能力。
6.4 BEiT
BEiT 预测 discrete visual tokens,需要 dVAE tokenizer。MAE 证明 pixel prediction 也可以达到甚至超过 token prediction,只要 masking 和 architecture 设计得当。
6.5 Contrastive learning
MoCo、SimCLR、BYOL、DINO 等方法通常依赖数据增强构造 views,并学习image 的similarity 和 dissimilarity。MAE 走另一条路线:不显式构造 positive/negative pairs,而是通过 masked reconstruction 构造 self-supervised signal。
七、MAE 模型
7.1 masking
MAE 沿用 ViT 的输入形式:把图像切成不重叠 patches,每个 patch 经过 linear projection 得到 token。随后对 patch tokens 进行 uniform random sampling:
- 随机打乱所有 patch tokens。(值得注意的是,这个打乱是patch经过linear proj,然后加完pos embedding之后才shuffle的)
- 保留前 25% 作为 visible patches。
- 移除后 75% 作为 masked patches。
这里的“mask”不是把 patch 替换成特殊 token 后送入 encoder,而是直接从 encoder 输入中删除 masked patches。
这个细节非常重要:encoder 的 sequence length 从完整图像的 196 patches 降为约 49 patches,Transformer self-attention 的计算量显著下降。
7.2 encoder
MAE encoder 本质上是一个 ViT encoder,但输入只有 visible patches。流程和
- patch embedding 经过 Linear Projection
- Linear Projection的输出加上 positional embedding,然后和ViT类似,前面加上一个像[CLS]那样的auxiliary dummy token,作为MAE的class token
- 然后进入 Transformer encoder
与 BERT-style encoder 最大区别是:encoder 中没有 mask tokens。这样做有两个好处:
- 效率更高:encoder 只处理 25% tokens。
- train-test gap 更小:downstream recognition 时输入是不被 mask 的完整图像,如果预训练时 encoder 见到大量 mask tokens,会产生分布差异。
7.3 decoder
decoder 的输入是完整 token 序列:
- encoded visible tokens;
- learnable mask tokens;(注意是learnable)
- positional embeddings,用于告诉 mask token 自己对应图像中的哪个位置。
decoder 经过若干 Transformer blocks 后输出每个 patch 的 pixel prediction。预训练结束后,decoder 被丢弃,只保留 encoder 用于 classification、detection、segmentation 等 downstream tasks。
论文默认 decoder:
- depth:8 blocks;
- width:512;
- 相比 ViT-L encoder,每 token FLOPs 约为 9%。
这体现了 asymmetric encoder-decoder 的含义:heavy encoder learns representation,light decoder solves reconstruction。
Q:mask_token 是每个位置一个吗?
A:
mask_token 只是单个的,可学习的 Emebdding,和BERT中的[mask]类似,只是一个泛用的mask向量。
在不同的position Embedding下,decoder会有不同的解释。
7.4 Reconstruction target 与 loss
MAE 预测 masked patches 的 pixel values。decoder 输出会被 reshape 回 patch 像素向量,然后与原始图像 patch 计算 MSE loss。
关键选择:loss 只在 masked patches 上计算,不在 visible patches 上计算。这与 BERT 类似,也避免模型把主要能力浪费在复制已经可见的输入上。
论文还研究了 normalized pixels:对每个 patch 内的 pixel values 做 mean/std normalization,再作为 reconstruction target。实验显示 normalized pixels 比 raw pixels 更好。
Q:为什么做normalization?
A:
normalization 是用 patch 内的 mean 和 var 来做标准化。它会让模型不要过度关注 patch 的绝对亮度、颜色均值,而更多关注局部纹理、边缘、结构等 high-frequency components。
7.5 简单实现流程
image
-> patchify
-> patch embedding + positional embedding
-> random shuffle patch tokens # shuffle 在加pos embedding 之后
-> keep visible tokens, remove masked tokens
-> encoder(visible tokens)
-> append mask tokens
-> unshuffle to original patch order # 这说明shuffle是需要记住的
-> decoder(full tokens)
-> predict patch pixels
-> MSE loss on masked patches only
7.6 为什么效果好?
-
高 mask ratio 把任务变难
如果只 mask 15% patch,图像重建可能主要依赖邻域插值。MAE 使用 75% mask 后,模型经常只能看到稀疏线索,需要根据 object shape、scene layout 和 semantic prior 推断缺失内容。
这解释了为什么论文中 Figure 2 和 Figure 4 的 reconstruction 虽然不一定像 ground truth,但往往 semantically plausible:模型不是机械复制,而是在生成一种合理解释。
-
Asymmetry 同时提升效率和 representation quality
MAE 的 asymmetry 不是单纯为了省算力。它还影响 representation 的语义层级:
- encoder 不直接处理 mask tokens,因此更接近 downstream 输入形式;
- decoder 独立承担 pixel reconstruction 的低层任务;
- encoder 可以学习更抽象的 representation;
- decoder 被丢弃,避免 reconstruction-specific layers 污染 downstream encoder。
-
Pixel target 简化了 masked image modeling
BEiT 需要 dVAE tokenizer,把图像转成 discrete visual tokens。MAE 证明:如果 masking ratio、encoder/decoder 分工和 target normalization 设计得当,直接预测 pixels 也可以非常强。
这让方法更简洁:不需要额外 tokenizer,不需要额外 tokenizer pre-training data,也减少 pipeline complexity。
八、实验
论文在 ImageNet-1K 上 self-supervised pre-train,然后用 supervised fine-tuning 或 linear probing 评估 representation。
Q:什么是linear probing?和Fine-tuning 的区别?
A:
Linear probing 是一种评估预训练模型 representation 质量的方法:冻结预训练好的 encoder,只在其输出特征上训练一个线性分类器,看这个线性头能取得多高准确率。
具体流程:
预训练 encoder -> 冻结参数,不更新 -> 输入图片,提取 feature -> 接一个 linear classifier -> 只训练 linear classifier -> 用分类准确率评价 feature quality和 fine-tuning 的区别:
方法 Encoder 是否更新 训练什么 评估含义 Linear probing 不更新,冻结 只训练线性分类头 feature 是否已经 linearly separable Fine-tuning 更新 encoder + 分类头一起训练 预训练模型经过任务适配后的最终性能 Partial fine-tuning 更新一部分 最后几层 encoder + 分类头 feature 经少量非线性适配后的质量
8.1 ViT-L baseline:MAE 明显优于从头训练

ViT-L 在 ImageNet-1K 上直接 supervised training 容易 overfit,即使强 recipe 能到 82.5,MAE pre-training 仍带来明显提升。更重要的是,fine-tuning 只需要 50 epochs,而 scratch training 需要更长 schedule。
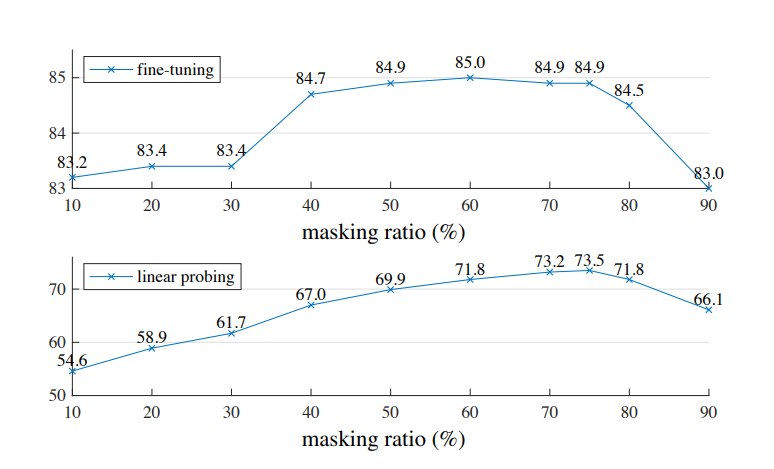
8.2 Masking ratio:75% 是关键
论文发现 75% mask ratio 对 fine-tuning 和 linear probing 都表现好,这与 BERT 常用 15% mask ratio 形成鲜明对比。
8.3 Decoder depth:深一点有利于 linear probing
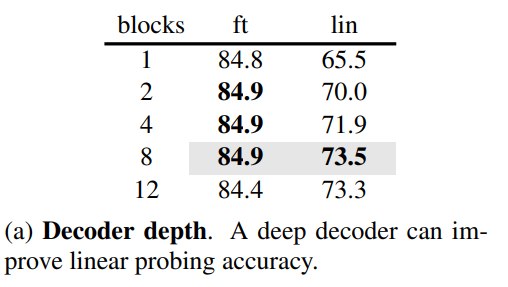
decoder 太浅时,encoder 需要承担更多 pixel reconstruction 的低层细节,linear probing 表现较差。适当加深 decoder 后,decoder 能吸收 reconstruction-specific burden,让 encoder representation 更抽象。但 fine-tuning 对 decoder depth 不敏感,因为 downstream training 可以调整 encoder 后层。
8.4 Decoder width:不需要和 encoder 一样宽
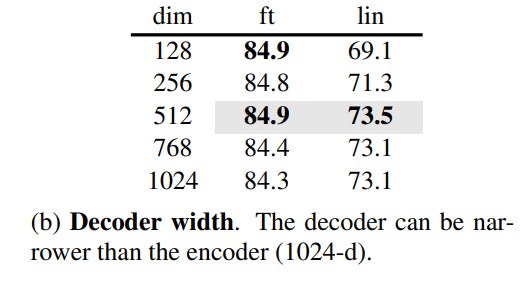
默认 512-d 已经足够。decoder 并不是越大越好,因为它只是预训练时的 reconstruction head,不是最终 representation encoder。
8.5 Encoder 中是否使用 mask token:不用更好
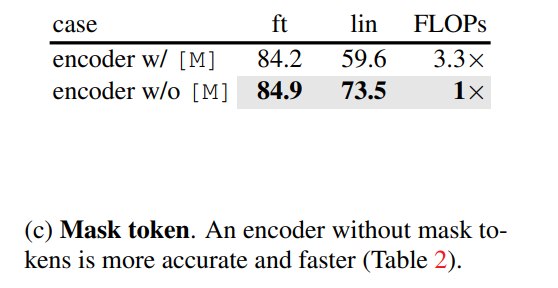
这是 MAE 最关键的 ablation 之一。encoder 加 mask tokens 不仅慢,而且 representation 更差。
原因是预训练时 encoder 输入中大部分是 artificial mask tokens,而 downstream 时没有这些 token,造成 train-test mismatch。
8.6 Reconstruction target:normalized pixels 很强
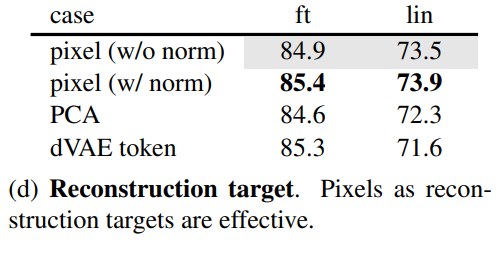
normalized pixels 比 raw pixels 更好,说明局部 contrast normalization 有利于 representation learning。dVAE token 在 fine-tuning 上接近 normalized pixels,但没有明显优势,还引入额外 tokenizer 和训练成本。
Q:这里的PCA是对数据做PCA降维吗?
A:
不是。
论文里 PCA reconstruction target 的意思是:decoder 的预测目标不再是完整 patch pixels,而是每个 patch 在 PCA 空间里的低维系数。
即,原先是像素级还原每个patch(比如16 * 16 * 3),PCA reconstruction可能只需要预测(4 * 4 * 3),然后计算loss的时候和原始图像的PCA进行计算。
8.7 Data augmentation:MAE 不依赖强增强

MAE 与 contrastive learning 的重要区别在这里体现出来:
- contrastive learning 高度依赖 multi-view augmentation
- **而 MAE 的主要“增强”来自 random masking。**每次迭代的 mask pattern 都不同,天然生成不同训练任务。
8.8 Mask sampling:random sampling 最好


- Block-wise masking 更难,重建更模糊,75% 时 representation 下降明显。
- Grid-wise masking 更规则、更容易,重建更清晰,但 representation 更差。
说明好的 pretext task 不是让 reconstruction 最漂亮,而是让任务难度恰好促使模型学到有用 representation。
8.9 Training schedule:长训练继续受益
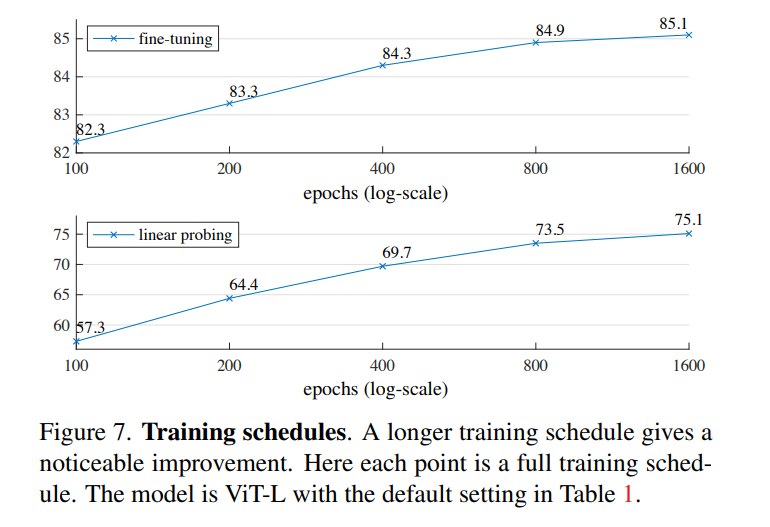
MAE 的 accuracy 随 pre-training epochs 增加持续提升,1600 epochs 仍未明显饱和。作者指出,MAE encoder 每个 epoch 只看到 25% patches,而 contrastive learning 中两视图或多视图会让 encoder 每 epoch 看到更多图像内容,因此 MAE 可能天然需要更长 schedule。
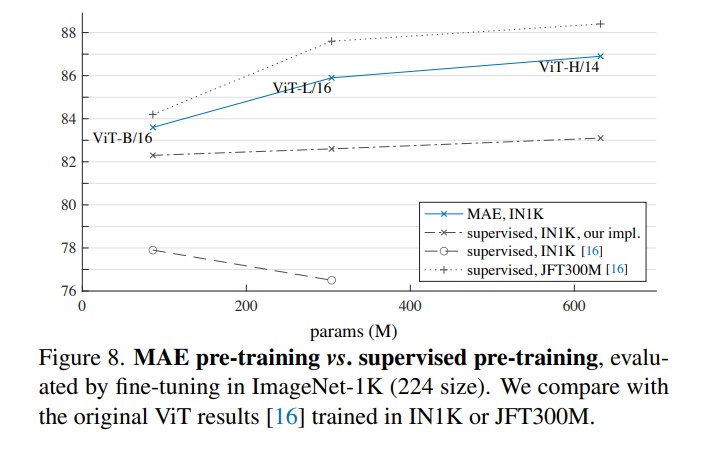
8.10 与已有方法的 ImageNet 对比
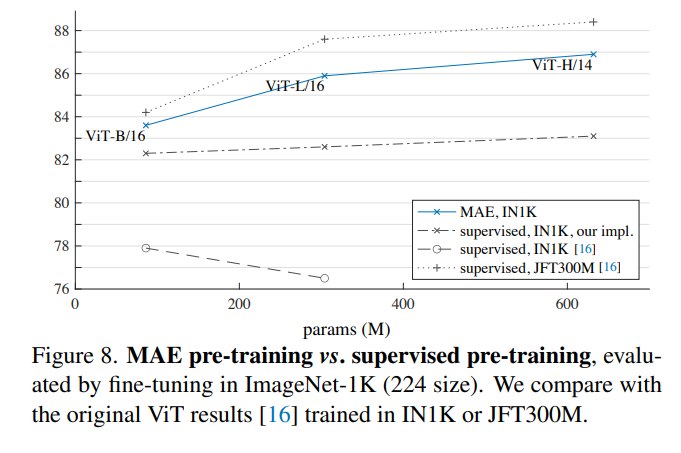
- ViT-B 上差距不大,但模型变大后 MAE 优势扩大。
- MAE ViT-H 在 224 resolution 达到 86.9,448 resolution 达到 87.8。
- 这些结果只用 ImageNet-1K 数据,不依赖 JFT-300M 或 DALLE tokenizer data。
- MAE 的强项不仅是 accuracy,还包括 simplicity 和 training efficiency。
8.11 Partial fine-tuning:linear probing 不是唯一标准
论文指出,MAE 的 linear probing 与 fine-tuning 表现不完全一致。MAE 的 feature 未必最 linearly separable,但经过少量非线性调整后很强。
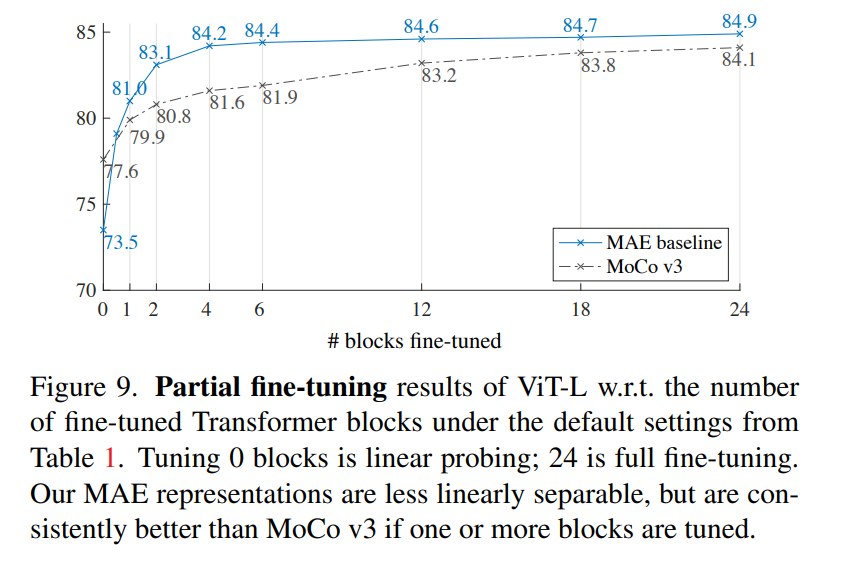
| Protocol | 现象 |
|---|---|
| Linear probing,0 blocks tuned | 73.5 |
| Tune 1 Transformer block | 提升到 81.0 |
| Tune half of last block / MLP-like head | 可达 79.1 |
| Tune 4 或 6 blocks | 接近 full fine-tuning |
contrastive methods 可能在 linear probing 上更强,但 MAE 在 partial fine-tuning 后优于 MoCo v3。这说明 linear separability 不能完全代表 representation quality,尤其对深层 Transformer representation 来说更明显。
九、Transfer learning
9.1 COCO object detection and instance segmentation
使用 ViT Mask R-CNN baseline,在 COCO 上 fine-tune。
| Method | Pre-train data | ViT-B box AP | ViT-L box AP | ViT-B mask AP | ViT-L mask AP |
|---|---|---|---|---|---|
| Supervised | IN1K labels | 47.9 | 49.3 | 42.9 | 43.9 |
| MoCo v3 | IN1K | 47.9 | 49.3 | 42.7 | 44.0 |
| BEiT | IN1K + DALLE | 49.8 | 53.3 | 44.4 | 47.1 |
| MAE | IN1K | 50.3 | 53.3 | 44.9 | 47.2 |
MAE 相比 supervised pre-training 在 ViT-L 上 box AP 提升 4.0,说明它学到的 representation 不只是服务于 ImageNet classification,也能迁移到 dense prediction。
9.2 ADE20K semantic segmentation
| Method | Pre-train data | ViT-B mIoU | ViT-L mIoU |
|---|---|---|---|
| Supervised | IN1K labels | 47.4 | 49.9 |
| MoCo v3 | IN1K | 47.3 | 49.1 |
| BEiT | IN1K + DALLE | 47.1 | 53.3 |
| MAE | IN1K | 48.1 | 53.6 |
MAE 在 segmentation 上同样优于 supervised pre-training 和 BEiT,进一步支持 pixel-based MAE 的 transfer ability。
9.3 Classification transfer:iNaturalist 与 Places
| dataset | ViT-B | ViT-L | ViT-H | ViT-H448 | prev best |
|---|---|---|---|---|---|
| iNat 2017 | 70.5 | 75.7 | 79.3 | 83.4 | 75.4 |
| iNat 2018 | 75.4 | 80.1 | 83.0 | 86.8 | 81.2 |
| iNat 2019 | 80.5 | 83.4 | 85.7 | 88.3 | 84.1 |
| Places205 | 63.9 | 65.8 | 65.9 | 66.8 | 66.0 |
| Places365 | 57.9 | 59.4 | 59.8 | 60.3 | 58.0 |
MAE 在 iNaturalist 和 Places 上也体现出 scaling behavior,尤其 ViT-H 448 在多个 dataset 上超过 previous best。值得注意的是,一些 previous best 使用十亿级图片预训练,而 MAE 仅使用 IN1K self-supervised pre-training。
9.4 Pixels vs tokens:tokenization 不是必要条件
| Target | IN1K ViT-B | IN1K ViT-L | IN1K ViT-H | COCO ViT-B | COCO ViT-L | ADE20K ViT-B | ADE20K ViT-L |
|---|---|---|---|---|---|---|---|
| Pixel without normalization | 83.3 | 85.1 | 86.2 | 49.5 | 52.8 | 48.0 | 51.8 |
| Pixel with normalization | 83.6 | 85.9 | 86.9 | 50.3 | 53.3 | 48.1 | 53.6 |
| dVAE token | 83.6 | 85.7 | 86.9 | 50.3 | 53.2 | 48.1 | 53.4 |
结论:dVAE token 与 normalized pixels 差异很小,tokenization 没有必要。MAE 的简单 pixel prediction 已经足够强。

说些什么吧!