
一、自注意力机制
1.1 为什么需要注意力机制
假如输入一句话:
我昨天买了一本关于深度学习的书,它非常有意思。
如果模型现在要理解“它”指代什么,它其实应该重点看前面的“书”,而不是平均看整句话。
传统的 RNN/LSTM 虽然能处理序列,但有两个问题:
- 长距离依赖难学
- 前面的信息传到后面会逐渐衰减
- 所有信息被压缩到一个固定长度表示中
- 容易丢失细节
注意力机制解决的核心思路是:在生成当前表示时,直接去“检索”输入序列中最相关的位置。
1.2 自注意力的运作原理
我们以一个输入和输出数量相同的情况,序列标注(sequence labeling)为例。
序列标注要给序列里面的每一个向量一个标签。要怎么解决序列标注的问题呢?直觉的 想法就是使用全连接网络。
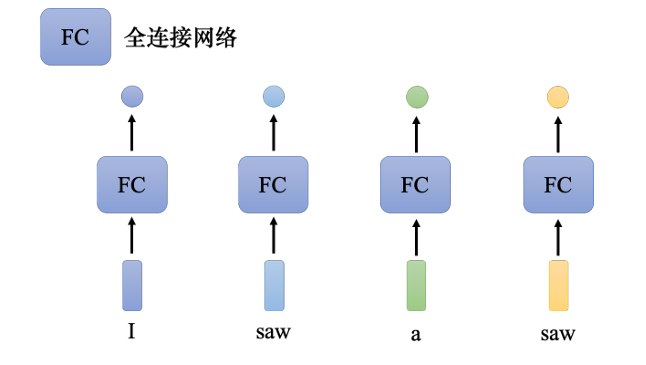
比如我们要做词性标注,给机器一个句子:I saw a saw。
对于全连接网络,两个saw完全一模一样,既然全连接网络输入同一个词汇,它没有理由输出不同的东西。
但实际上,我们期待第一个saw要输出动词,第二个saw要输出名词。
有没有可能让全连接网络考虑更多的信息,比如上下文的信息呢?
这是有可能的,把每个向量的前后几个向 量都“串”起来,一起输入到全连接网络就可以了。
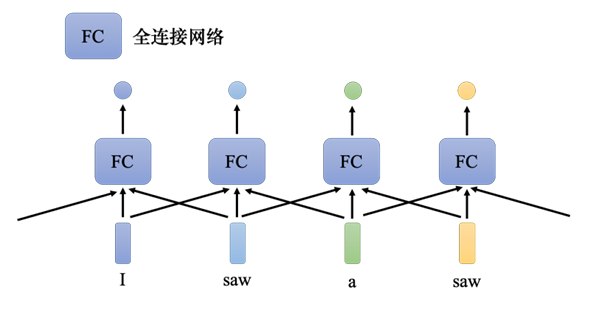
这就引入另一个问题,窗口开多大才好呢?有的时候窗口并不是越大越好,过大,不仅会运算量超大,而且容易过拟合。
如果想要更好地考虑整个输入序列的信息,就要用到自注意力模型。
运作方式如下:
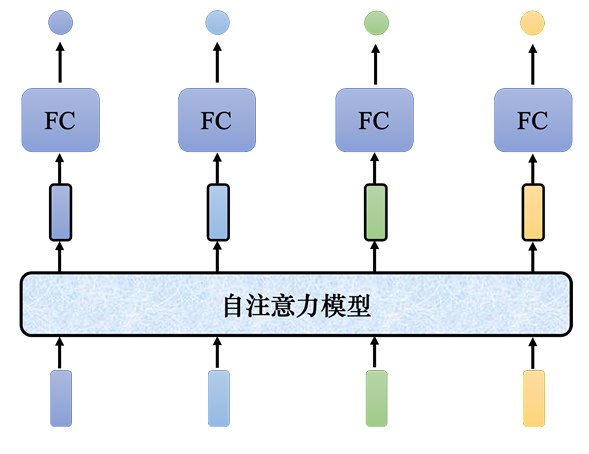
自注意力模型会“吃”整个序列的数据,输入几个向量,它就输出几个向量。
自注意力模型不是只能用一次,可以叠加很多次,自注意力模型的输出可以经过一些网络,然后接着做注意力机制。
那么自注意力模型的输出是如何得到的呢?
每一个输入都要有一个输出,而每一个输出,都是考虑了整个输入之后才生成出来的。
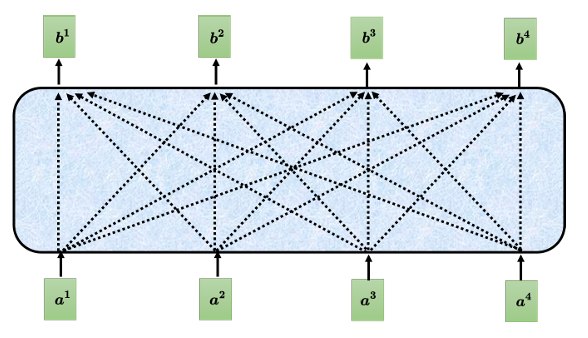
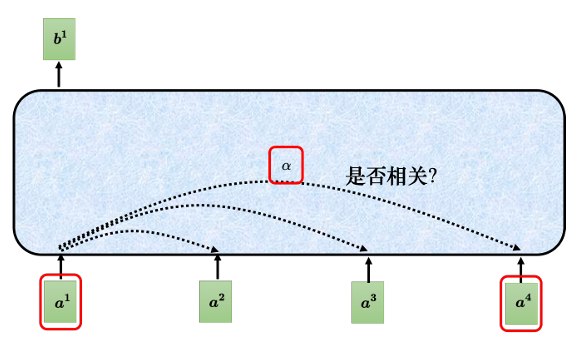
我们以$b^1$的产生的过程为例,其它的可以类推。
首先我们要能够判断$a^1$和其它输入的关联程度$\alpha$,给两个向量 $a^1$ 跟 $a^4$ ,它怎么计算出一个数值α呢?我们需要一个计算注意力的模块。
一个常见的方式是点积(dot product)。
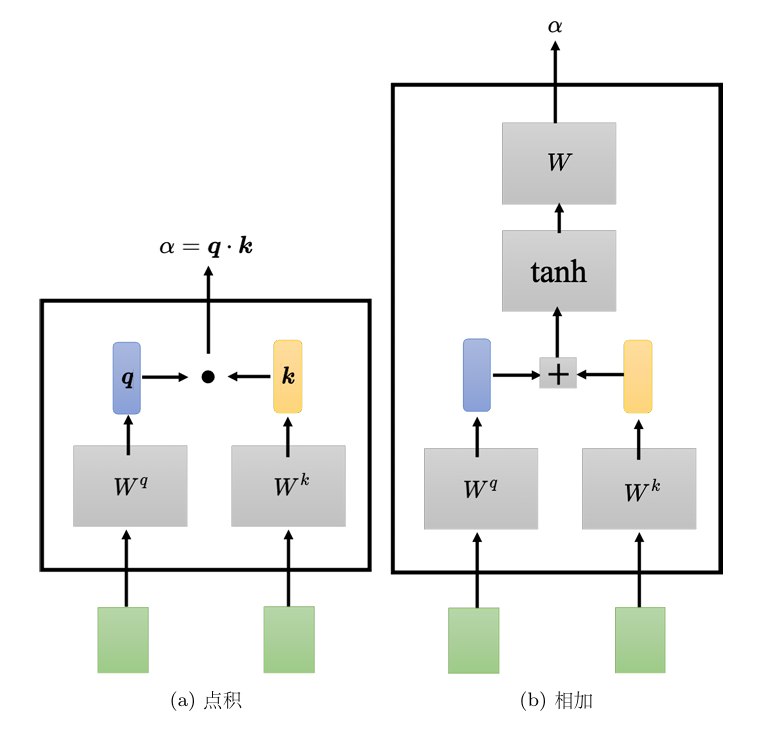
把输入的两个向量分别乘上两个不同的矩阵,左边这个向量乘上矩阵$W^q$,右边这个向量乘上矩阵$W^k$,得到两个向量 $q$ 跟 $k$,再把 $q$ 跟 $k$ 做点积,把它们做逐元素(element-wise)的相乘,再全部加起来以后就得到一个标量(scalar)α,这是一种计算 α 的方式。
有另外一个叫做**相加(additive)**的计算方式,其计算方法就是把两个向量通过$W^q$、$W^k$得到$q$和$k$,但不是把它们做点积,而是把 $q$ 和$k$“串”起来“丢”到一个 tanh 函数,再乘上矩阵$W$得到α。总之,有非常多不同的方法可以计算注意力,可以计算关联程度α。但是在接下来的内容里面,我们都只用点积这个方法, 这也是目前最常用的方法,也是用在 Transformer 里面的方法
接下来如何把它套用在自注意力模型里面呢?自注意力模型一般采用查询-键-值(Query-Key-Value,QKV)模式。分别计算 $a^1$ 与 $a^2$、$a^3$、$a^4$ 之间的关联性 α。
把 $a^1$ 乘上$W^q$ 得到$q^1$。$q$ 称为查询(query),它就像是我们使用搜索引擎查找相关文章所使用的关键字,所以称之为查询。
接下来把$a^2$、$a^3$、$a^4$ 乘上$W^k$ 得到向量$k$,向量$k$称为键(key)。把查询$q^1$ 跟键 $k^2$ 算内积(inner-product)就得到 $α_{1,2}$查询,即$q^1$和$k^2$之间的关联性,也被称为$a^1$和$a^2$的注意力分数。
实践的时候,$a^1$也会跟自己算关联性,计算出$a^1$跟每个向量的关联性后,通常会对所有关联性做一个softmax。
$$ \alpha'_{1,i}=exp(\alpha_{1,i})/\sum_{j}exp(\alpha_{1,j}) $$当然也不一定用softmax,也可以用ReLU之类的激活函数,有些时候结果比softmax还要好。
接下来我们要根据关联性,即注意力的分数来抽取重要的信息。把向量$a^1$ 到$a^4$ 乘上$W^v$ 得到新的向量:$v^1$、$v^2$、$v^3$ 和$v^4$,接下来把每一个向量都去乘上注意力的分数$α^′$,再把它们加起来。
$$ b^1 = \sum_{i}\alpha'_{1,i} v^i $$每个输入都以此类推的得到各自输出,于是整个自注意力机制(以点积注意力为例)的过程就可以用矩阵运算来表示:
$$ &Q = W^qI\\ &K = W^kI\\ &V = W^vI\\ &A = K^TQ\\ &A' = softmax(A)\\ &O = VA' $$不过实际当中,通常用的是Scaled Dot-Product Attention(缩放点积注意力):
$$ A' = softmax(\frac{K^TQ}{\sqrt{d_k}}) $$其中,$d_k$为向量维度,向量维度越大,点积的数值通常也会越大,导致:
- •某些值特别大
- softmax 输出过于尖锐
- 梯度变小,不利于训练
所以除以 $\sqrt{d_k}$ 是为了让数值更稳定。
1.3 多头注意力
如果只做一次注意力,模型等于只用一种方式理解关系。
但现实里,一个词和其他词的关系可能很多样:
- 语法关系
- 语义关系
- 指代关系
- 位置关系
与其只做一次注意力,不如并行做多次,每次学不同的关注模式。
这就是多头注意力。
假设说我们有 h 个头,那么每个头都有各自的参数:
$$ W_q^i,W_k^i,W_v^i $$然后每个头分别计算
$$ h_i' = softmax(\frac{K^T_iQ_i}{\sqrt{d_k}})V_i \\ $$然后把所有头拼接起来,再做输出:
$$ O = W_oConcat(h1',h2',...,h_h') $$1.4 位置编码
自注意力层少了一个也许很重要的信息,即位置的信息。
对一个自注意力层而言,每一个输入是出现在序列的最前面还是最后面,它是完全没有这个信息的。
因此做自注意力的时候,如果我们觉得位置的信息很重要,需要考虑位置信息时,就要用到位置编码(positional encoding)。
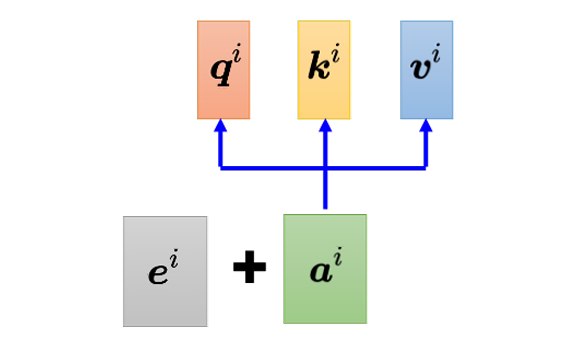
位置编码为每一个位置设定一个向量,即位置向量(positional vector)。不同位置都有专属的位置向量$e^i$,把$e^i$加到对应输入上就结束了。
位置编码的生成方式有很多,最早的 “AttentionIs All You Need"中,就是用正余弦函数来生成位置编码。、
假设输入表示 $\mathbf{X} \in \mathbb{R}^{n \times d}$ 包含一个序列中 $n$ 个词元的 $d$ 维嵌入表示。 位置编码使用相同形状的位置嵌入矩阵 $\mathbf{P} \in \mathbb{R}^{n \times d}$ 输出$\mathbf{X} + \mathbf{P}$, 矩阵第$i$行、第$2j$列和$2j+1$列上的元素为:
$$ \begin{split}\begin{aligned} p_{i, 2j} &= \sin\left(\frac{i}{10000^{2j/d}}\right),\\p_{i, 2j+1} &= \cos\left(\frac{i}{10000^{2j/d}}\right).\end{aligned}\end{split} $$Q:为什么要通过正弦函数和余弦函数产生向量,有其他选择吗?为什么一定要这样产生手工的位置向量呢?
A:当然有其他选择,有专门的论文去讨论如何选择位置编码,这里简单聊一下正余弦函数生成位置编码的好处。
- 相邻位置的表示要有连续变化,不是跳跃的,且不同位置尽量不同
- 不同维度对应不同“频率”,有的维度变化很快:能区分局部位置差异;有的维度变化很慢:能表示更大尺度的位置趋势
- 让模型容易学到“相对位置”,因为根据三角函数的加法公式,我们可以通过线性组合来得到某个偏移量的位置编码,那么模型更容易从绝对位置编码中推导出相对位置信息。
1.5 截断注意力
自注意力不是只能用在自然语言处理相关的应用上,它还可以用在很多其他的问题上。比如在做语音的时候,也可以用自注意力。不过将自注意力用于语音处理时,可以对自注意力做一些小小的改动。
对于普通的注意力机制,如果序列长度是 ,那么:
- 每个位置都要和其他 n 个位置算相关性
- 会得到一个 $n \times n$ 的注意力矩阵
这意味着复杂度大致是:
时间复杂度:$O(n^2)$
空间复杂度:$O(n^2)$
**截断自注意力(truncated self-attention)**可以处理向量序列长度过大的问题。截断自注意力在做自注意力的时候不要看一整句话,就只看一个小的范围就好,这个范围是人设定的。在做语音识别的时候,如果要辨识某个位置有什么样的音标,这个位置有什么样的内容,并不需要看整句话,只要看这句话以及它前后一定范围之内的信息,就可以判断。在做自注意力的时候,也许没有必要让自注意力考虑一整个句子,只需要考虑一个小范围就好,这样就可以加快运算的速度。这就是截断自注意力。
1.6 自注意力 vs CNN
自注意力怎么看图像
如果对图像中的某个像素做 self-attention:
- 这个像素会生成一个 query
- 其他像素生成 key/value
- 它会和整张图像的所有像素计算相关性
- 最后综合整张图的信息
自注意力机制看全局
CNN 怎么看图像
- 每个卷积核只看一个局部区域
- 即所谓的感受野(receptive field)
- 只利用附近像素的信息
CNN看局部
CNN:
- 感受野是人工设定的
- 每个神经元只看固定局部范围
- 哪些位置参与计算,是先验决定的
Self-Attention:
- 不需要手工规定感受野
- 网络会自动学出该关注哪些位置
- 关注范围和形状都是数据驱动学习出来的
所以这段话的核心可以概括成:CNN 是固定局部连接,自注意力是可学习的动态连接。
CNN 其实是 Self-Attention 的特例,卷积神经网络可以看作是受限制的自注意力。
Self-Attention 的表达能力更大、更灵活,如果给 Self-Attention 加上某些限制,它就可以表现得和卷积一样。
通常情况下,CNN在小数据集上更强,一旦数据量多时,Self-Attention 更灵活,更能从海量数据中获益,最终可能超过 CNN。
1.7 自注意力 vs RNN
-
二者都能处理序列
- RNN 处理序列输入,Self-Attention 也处理序列输入
-
信息整合方式不同
- Self-Attention 每个位置的输出都可以直接看整个输入序列。即:每个 token 都能直接访问全局上下文。
- RNN 的信息则是沿时间链条逐步传播的。
-
长距离依赖上的差别
-
RNN如果最后一个位置想利用第一个位置的信息:必须把这个信息一直存在 hidden state 里经过很多步传递中间容易衰减、遗忘
所以:RNN 处理长距离依赖比较困难。
-
Self-Attention 更容易建模长距离依赖。
-
-
并行性差异
- RNN:无法完全并行
- Self-Attention:更容易并行,训练和推理更高效。
1.8 图结构上的自注意力
如果输入不只是向量集合,而且还带有“图结构”,那么自注意力也能进一步利用图中的边信息。
图里面除了节点向量,还有边:
- 有边,说明两个节点有关联
- 没边,说明关系弱或者没有关系
既然图结构本身已经提供了先验知识,那么就没必要还让模型在所有节点间都学习关系。
所以可以直接限制:只在有边连接的节点之间计算注意力。
这样就变成了图神经网络(GNN) 比如:
- 节点 1 只和 5、6、8 相连
- 那么节点 1 只需要和 5、6、8 算注意力
- 不相连的节点直接不算,权重设为 0
这样做的本质就是:
- 利用图结构限制注意力的连接范围
- 只在邻居之间聚合信息

说些什么吧!